Non-Uniform Memory Access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to a processor. Under NUMA, a processor can access its own local memory faster than non-local memory, that is, memory local to another processor or memory shared between processors.
This means in a physical server with two or more sockets on an Intel Nehalem or AMD Opteron platform, very often we find memory that is local to one and memory that is local to the other socket. A socket, its local memory and the bus connecting the two components is called a NUMA node. Both sockets are connected to the other sockets’ memory allowing remote access.
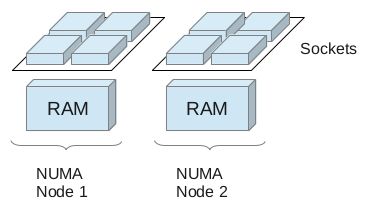
Please be aware that an additional socket in a system does NOT
necessarily mean an additional NUMA node! Two or more sockets can be
connected to memory with no distinction between local and remote. In
this case, and in the case where we have only a single socket, we have
a UMA (uniform memory access) architecture.
uma Summarizing NUMA Scheduling
UMA system: one or more sockets connected to the same RAM.
Scheduling – The Complete Picture
Whenever we virtualize complete operating systems, we get two levels
of where scheduling takes place: A VM is provided with vCPUs (virtual
CPUs) for execution and the hypervisor has to schedule those vCPUs
accross pCPUs (physical CPUs). On top of this, the guest scheduler
distributes execution time on vCPUs to processes and threads.
scheduling overview Summarizing NUMA Scheduling
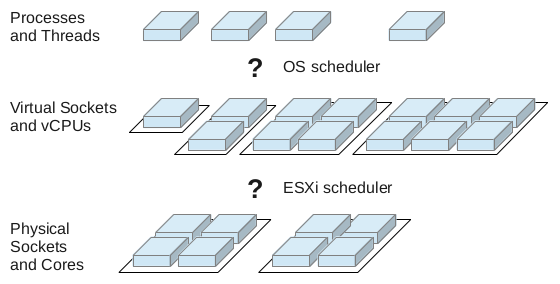
So, we have to take a look at scheduling at two different levels to understand what is going on there. But before we go into more detail we have to take a look at a problem that might arise in NUMA systems.
The Locality Problem
Each NUMA node has its own computing power (the cores on the socket)
and a dedicated amount of memory assigned to that node. You can very
often even see that taking a look at your mainboard. You will see two
sockets and two separate groups of memory slots.
P 500 Summarizing NUMA Scheduling

Those two sockets are connected to their local memory through a memory bus, but they can also access the other socket’s memory via an interconnect. AMD calls that interconnect HyperTransport which is the equivalent to Intel’s QPI (QuickPath Interconnect) technology. The names both suggest very high throughput and low latency. Well, that’s true, but compared to the local memory bus connection they are still far behind.
What does this mean to us? A process or virtual machine that was started on either of the two nodes should not be moved to a different node by the scheduler. If that happened – and it can happen if the scheduler in NUMA-unware – the process or VM would have to access its memory through the NUMA node interconnect resulting in higher memory latency. For memory intensive workloads, this can seriously influence performance of applications! This is referred to by the term “NUMA locality”.
