|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
|
|
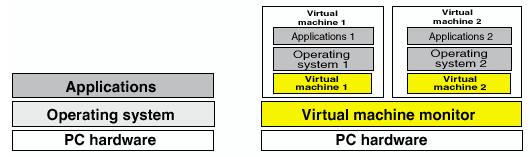
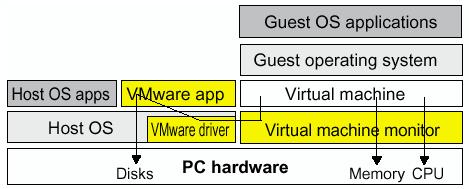
At the center of the UNIX onion is a program called the kernel. Although you are unlikely to deal with the kernel directly, it is absolutely crucial to the operation of the UNIX system.
|
|
The kernel provides the essential services that make up the heart of UNIX systems; it allocates memory, keeps track of the physical location of files on the computer's hard disks, loads and executes binary programs such as shells, and schedules the task swapping without which UNIX systems would be incapable of doing more than one thing at a time. The kernel accomplishes all these tasks by providing an interface between the other programs running under its control and the physical hardware of the computer; this interface, the system call interface, effectively insulates the other programs on the UNIX system from the complexities of the computer. For example, when a running program needs access to a file, it cannot simply open the file; instead it issues a system call which asks the kernel to open the file. The kernel takes over and handles the request, then notifies the program whether the request succeeded or failed. To read data in from the file takes another system call; the kernel determines whether or not the request is valid, and if it is, the kernel reads the required block of data and passes it back to the program. Unlike DOS (and some other operating systems), UNIX system programs do not have access to the physical hardware of the computer. All they see are the kernel services, provided by the system call interface.
The critical part of the kernel is usually loaded into a protected area of memory, which prevents it from being overwritten by other parts of the operating system or, worse, applications (actually the ability to overwrite kernel in Unix is a side effect of using C which does not control pointers). The kernel performs its tasks, such as executing processes and handling interrupts, in kernel space, whereas other process operate in user space. This separation prevents user data and kernel data from interfering with each other and thereby diminishing performance or causing the system to become unstable (and possibly crashing).
The system call interface is an example of an API, or application programming interface. An API is a set of system calls with strictly defined parameters, which allow an application (or other program) to request access to a service; it literally acts as an interface. In this sense kernel is not that different from other applications. For example, a database system also provides an API that allows programmers to write external programs that request services from the database.
1978 IBM poster explaining virtual memory
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
sysctl the Command and the Subroutine, Aug 20, 2000 ) May 24, 2021 | www.linuxquestions.org
Registered: Feb 2009
Location: SurinameDistribution: Slackware 12.1
Posts: 6
[ Log in to get rid of this advertisement]Alright, you just got that fast NVMe SSD, or even a couple You hope this drive, the size of a pack of chewing gum, will feed your need for speed.
So, you install it in your system and notice that your system is noticeably more responsive; but there's something that makes you feel as though you might have missed something. What is it?
Well, for starters, most likely, the one thing most people tend to overlook, is the filesystem they choose to format their new NVMe SSD with. Two of the most popular filesystems on Linux are "The Fourth Extended Filesystem" or as it is also known: "ext4", and XFS, which is a 64-bit journalling file system created by Silicon Graphics, Inc
EXT4 and XFS are robust, journalling filesystems, and very well known and supported in the Linux world. They are also given as options for formatting hard drives, during installation of the various Linux distributions. But what is not as well known, is that EXT4 and XFS, like most other filesystems, were never intended to be used on anything other than spinning hard drives.
There was no NAND flash-based media when they were developed.
Granted, it works fine, can be grown or shrunk, depending on the needs of the user or system administrator. Why then, you ask, did I even write this tutorial? I'll tell you.
SSDs and NVMe PCIe drives, are flash-based; and do things quite a bit differently than rotational hard drives. In short, the filesystem I'm about to suggest, Flash Friendly Filesystem (F2FS), has been designed from the ground up, specifically NAND flash-based SSDs, by Samsung. Static binaries start up noticeably faster on this filesystem. And in this tutorial, I will be using a pair of Samsung EVO PLUS 970 NVMe SSDs which offer sequential performance at read/write speeds of up to 3,500/3,300 MB/s. And as a bonus, the 970 EVO Plus includes an AES 256-bit hardware-based encryption engine; a nice touch for those who like to encrypt their data.Why two? Because my motherboard has two M.2 slots, while some have three or more; and because I prefer at least two drives in my setup. This means that in your case, one drive might get a Windows installation, and the other Linux, or a Virtual Machine (VM) if you're into that sort of thing.
Personally, I advise installing the '/' (root) on drive 1, and '/home' (user files) on drive 2. Or maybe you're a video editor, and the Operating System (OS) is on drive 1, and drive 2 for your video editing and rendering software, etc. Or perhaps you're a gamer, and place the OS on drive 1, and your games on drive number 2. The point is, when possible, place your OS on drive 1, and the programs you install yourself, on the second drive. And should you have three or more drives, which you can use from within your OS, even better. This will allow you to interleave commands between the drives, and as a result, you end up not noticing any slowdowns in your perceived performance of the system.
Even though NVMe drives are way faster than rotational drives, it's still more efficient to separate large programs from the OS, even though some might say it's not really necessary, because the drives are so fast with a lot of throughput. It all depends on how you will be using the system.
Anyway, let's get to the meat of this tutorial.
F2FS stands for "Flash Friendly File System", and was developed at Samsung Electronics Co., Ltd. And F2FS is also a filesystem designed to make the most of the performance capabilities of modern NAND flash-based devices. It was designed from the ground up, for that purpose.
While it is possible to use it on rotational hard drives, it would defeat the purpose; as you would not allow the filesystem to show you what it can do. It really should be used on NAND flash-based drives.
My personal layout I will describe below.First the hardware specifications:
CPU Intel i9-9900k
MOTHERBOARD Asus TUF-Z390 PLUS GAMING
RAM 32GB DDR4NVMe SSDs 2x Samsung 970 EVO PLUS 250GB
SATA SSDs 2x Samsung 860 EVO 1TB
SATA HDD 1x Western Digital 3TB 5400rpm
Linux OS Slackware -current 64 bit (August 30, 2019)
You will need F2FS tools: f2fs-tools-1.12.0-x86_64-1.txz (latest version at the time of this writing)
You may download it from https://slackware.pkgs.org , or any of the other repositories.
Since I desired to get the most user perceived speed out of the system, I used a combination of filesystems for the system, temp, and home partitions.
Like this:
Swap is the first partition, and also the smallest, at 8GB.
The OS root partition (/) at 32GB, is formatted with F2FS (programs start fastest with F2FS)
The temp partition (/tmp) at 40GB, is formatted with EXT4 (fastest when compiling software)
The user files partition (/home) at 150GB, is formatted with XFS (speedy for large and random files)
Here is a link with a speed test comparison between BTRFS, EXT, F2FS, XFS, on Linux:
https://www.phoronix.com/scan.php?pa...esystems&num=1Now, one last thing: the drive space is setup under LVM (Logical Volume Management)
This makes it much simpler to shrink and or expand partition sizes on the fly.
I created the following:1 Physical Volume (PV)
1 Volume Group (VG)
3 Logical Volumes (LVs)So far this is fairly straightforward.
I forgot to mention that the other NVMe SSD was used for a Windows 10 installation, *before* I started with the install of Slackware Linux. This prevents Windows from overwriting the boot loader.Now, for those unfamiliar with creating an LVM setup, I'll give generic instructions, which should work on most Linux systems. Some of the instructions are lifted from alien Bob's slackware LVM. Read all the instructions before you begin. Let's go.
To create a new Logical Volume (LV), this has to happen before you run the part of the installer, where you actually install the OS. Start by creating the partition where you will place the LVM with fdisk for BIOS, or gdisk for GPT disks. After creating the partition, then change the type to "8e", which is Linux LVM. Reboot the system, and continue with setting up the LVM.
Now I will leave the partition sizes up to you, but in this example, I will be dividing a 250GB SSD, over 2 partitions; swap, and the rest of the space for system install.
Start as follows:1. pvcreate /dev/nvme0n1p2 (<-- the second partiton after swap)
2. vgcreate slackware /dev/nvme0n1p2 (<-- slackware is the name I chose, can be anything)
3. lvcreate -L 32GB -n root slackware
4. lvcreate -L 40GB -n temp slackware
5. lvcreate -l 100%FREE -n home slackware (this command uses all the remaining space for home)
Now you can continue with the OS installation.
Make sure you choose "/dev/slackware/root" as the "/" partition, when asked where to install to; and format it with F2FS.
Then make sure you choose "/dev/slackware/temp" to mount as the "/tmp" partition, and choose to format it with EXT4. And lastly, choose "/dev/slackware/home" to mount as the "/home" partition, and format it with XFS.When the installer finishes, it will ask you to reboot. But select "no" and go with the option to let it drop you into a command prompt.
To boot this setup, you need to add the F2FS modules to your initrd, if using LILO, and install the F2FS tools in your OS, before you reboot.I previously downloaded the f2fs-tools-1.12.0-x86_64-1.txz on a partition of one of the other SSDs, which I simply mounted, located the binary, and ran "installpkg f2fs-tools-1.12.0-x86_64-1.txz".
Now, chroot into the installed OS, by typing: chroot /mnt (<-- Slackware specific instructions YMMV)
Here's the command to create the initrd for kernel version 4.19.69 with modules for LVM and F2FS:
(is a single line)
mkinitrd -c -k 4.19.69 -m crc32:libcrc32c:crc32c_generic:crc32c-intel:crc32-pclmul:f2fs -f f2fs -r /dev/slackware/root -LFor a system using LILO, edit the lilo.conf file, so lilo uses the initrd, and add the following:
image = /boot/vmlinuz-generic-4.19.69
initrd = /boot/initrd.gz
root = /dev/slackware/root
label = linux
read-onlyRun /sbin/lilo when you are done editing lilo.conf.
If using GRUB, after installing the F2FS tools, you need to make sure the LVM modules load before the rest of the system.
Edit /etc/default/grub, find the following line:
GRUB_PRELOAD_MODULES="... " (<-- there might be other modules already there)And add the required modules between the quotation marks at the end.
Like so:GRUB_PRELOAD_MODULES="... lvm f2fs"
Then run update-grub (or grub-mkconfig -o /boot/grub/grub.cfg), wait for it to complete, and you should be set.
If at this point you reboot, and you can boot into your shiny new system without error... Congratulations!
You are done.Cheers!
For suggestions on improving this tutorial, please email to:
[email protected]
or simply reply to this thread=========================================================================
DISCLAIMER:If your computer explodes, any part of it gets damaged, you lose data, or Earth is destroyed as a result of you following these instructions... I am not responsible for anything other than providing you with the instructions on how to setup a system, with user-perceivable increased speed. Understand this before you go through with it.
Last edited by WiseSon; 09-26-2019 at 12:17 PM. Reason: typos, spacing
09-16-2019, 01:59 PM # 2 MensaWater LQ Guru
Registered: May 2005
Location: Atlanta Georgia USADistribution: Redhat (RHEL), CentOS, Fedora, CoreOS, Debian, FreeBSD, HP-UX, Solaris, SCO
Posts: 7,831Blog Entries: 15
Rep:
Nice write up. One thing though - you don't mention RAID setup. While I prefer to separate OS and other filesystems as you mentioned I would not do it at the cost of RAID redundancy of the drives. Rather I'd put both drives into a RAID1 setup (NVME hardware or meta disk) then use that as the PV for the VG then create separate LVs for the OS and other filesystems. Of course I'd lose space availability of the equivalent of one drive but wouldn't have to worry about one drive going down blowing me out of the water as I would in a non-RAID config.
We made the mistake of using a single SSD card in a system because it claimed to do "internal redundancy" by duplicating data from one memory spot to another. It bit us when the controller on the SSD card itself died - that particular item was not redundant so we lost the drive and the data on it.
2 members found this post helpful.
09-17-2019, 12:49 PM # 3 WiseSon LQ Newbie
Registered: Feb 2009
Location: SurinameDistribution: Slackware 12.1
Posts: 6Rep:
Original PosterHi, You are right.
An LVM in a RAID SETUP, RAID 1 at least, would provide the minimum required redundancy.
Though I must confess, I have never setup a RAID array before. However, since most of the new motherboards come with a halfway decent raid chip, and the UEFI includes automated RAID array creation, it has become rather easy.While I familiarize myself with the RAID documentation, I will also add something that is of use for those with UEFI/GPT setups: I successfully installed Slackware, GRUB on the GPT initialized NVMe SSD. It turned out to be very simple as well. I'll edit the instructions to include the updated information.
Thanks for the heads up
Cheers!
09-19-2019, 04:41 AM # 4 rogan Member
Registered: Aug 2004
Distribution: SlackwarePosts: 197
Rep:
Exellent work. I would not draw too many conclusions based on phoronix benchmarks though. File system performance and usability
wary wildly between every kernel release (even "maintenance" releases). The best is always to do some simple
tests yourself, with the software you intend to use, and for your use case.While designing a file system specifically with the underlying media in thought might seem like a good idea, I
can't help but to wonder if the manufacturers of these devices thought: "Someone will probably come up with a
file system that actually works well with these devices, one day" or if they are well suited for the file systems
that were available at the time of their introduction.Anyways; f2fs is (as of 5.2.15 on current) not really up to par in my tests. Heres an exerpt from one of my
benchmark logs:Benchmarking wd 250G ssd on 5.2.15, 32G AMD 9590 sata, current of 10sept 2019.
All tests are done on newly formatted and trimmed (ssd) media. File systems
were loaded with hardware accelerated routines where applicable.
Hot cache copying ~50G (a few ftp archives and ~30 kernel source trees)
from ssd (ext4) to ssd. Reads were never close to exhaustion in any of these.
Measured time is return time, variance is around 10 sec. Actual time to
unmount readiness is ~20 +seconds for xfs, a little bit less for the others.mkfs.btrfs -L d5 -m single -d single /dev/sde1:
root@trooper~# time cp -r /usr/local/src/system /mnt/d5/
real 5m34.001s
user 0m4.620s
sys 1m29.392s
root@trooper~# time rm -rf /mnt/d5/systemreal 0m42.177s
user 0m0.797s
sys 0m40.454smkfs.ext4 -L d5 -O 64bit -E lazy_itable_init=0,lazy_journal_init=0 /dev/sde1:
root@trooper~# time cp -r /usr/local/src/system /mnt/d5/
real 5m10.676s
user 0m4.432s
sys 1m26.711s
root@trooper~# time rm -rf /mnt/d5/systemreal 0m27.748s
user 0m0.912s
sys 0m25.331smkfs.xfs -L d5 /dev/sde1:
root@trooper~# time cp -r /usr/local/src/system /mnt/d5/
real 4m50.607s
user 0m4.642s
sys 1m22.464s
root@trooper~# time rm -rf /mnt/d5/systemreal 1m5.594s
user 0m0.915s
sys 0m38.763smkfs.f2fs -l d5 /dev/sde1:
root@trooper~# time cp -r /usr/local/src/system /mnt/d5/
real 7m25.367s
user 0m4.171s
sys 1m22.977s
root@trooper~# time rm -rf /mnt/d5/systemreal 1m1.034s
user 0m0.846s
sys 0m26.094sWhile test installing "current" systems on f2fs root I've also had some nasty surprises:
#1 mkinitrd does not include dependencies for f2fs (crc32c) when you build an initrd.
#2 fsck while booting on f2fs always claim corruption.
09-19-2019, 05:30 AM # 5 syg00 LQ Veteran
Registered: Aug 2003
Location: AustraliaDistribution: Lots ...
Posts: 19,645
Rep:
Many years ago - well before the turn of the century we had a very bad time with an early log structured enterprise SAN (mainframe). I've always been leery about them ever since - especially the garbage collection.
And given the changes constantly incorporated for flash support into the tradition filesystems, I see no requirement in normal operation for f2fs.Each to their own though, and good to see documentation efforts like this.
May 24, 2021 | arstechnica.com
This Monday, ZFS on Linux lead developer Brian Behlendorf published the OpenZFS 2.0.0 release to GitHub. Along with quite a lot of new features, the announcement brings an end to the former distinction between "ZFS on Linux" and ZFS elsewhere (for example, on FreeBSD). This move has been a long time coming -- the FreeBSD community laid out its side of the roadmap two years ago -- but this is the release that makes it official.
AvailabilityThe new OpenZFS 2.0.0 release is already available on FreeBSD, where it can be installed from ports (overriding the base system ZFS) on FreeBSD 12 systems and will be the base FreeBSD version in the upcoming FreeBSD 13. On Linux, the situation is a bit more uncertain and depends largely on the Linux distro in play.
Users of Linux distributions that use DKMS-built OpenZFS kernel modules will tend to get the new release rather quickly. Users of the better-supported but slower-moving Ubuntu probably won't see OpenZFS 2.0.0 until Ubuntu 21.10, nearly a year from now. For Ubuntu users who are willing to live on the edge, the popular but third-party and individually maintained jonathonf PPA might make it available considerably sooner.
OpenZFS 2.0.0 modules can be built from source for Linux kernels from 3.10-5.9 -- but most users should stick to getting prebuilt modules from distributions or well-established developers. "Far beyond the beaten trail" is not a phrase one should generally apply to the file system that holds one's precious data!
Advertisement New features Sequential resilverRebuilding degraded arrays in ZFS has historically been very different from conventional RAID. On nearly empty arrays, the ZFS rebuild -- known as "resilvering" -- was much faster because ZFS only needs to touch the used portion of the disk rather than cloning each sector across the entire drive. But this process involved an abundance of random I/O -- so on more nearly full arrays, conventional RAID's more pedestrian block-by-block whole-disk rebuild went much faster. With sequential resilvering, ZFS gets the best of both worlds: largely sequential access while still skipping unused portions of the disk(s) involved.
Persistent L2ARCOne of ZFS' most compelling features is its advanced read cache, known as the ARC. Systems with very large, very hot working sets can also implement an SSD-based read cache called L2ARC, which populates itself from blocks in the ARC nearing eviction. Historically, one of the biggest issues with L2ARC is that although the underlying SSD is persistent, the L2ARC itself is not -- it becomes empty on each reboot (or export and import of the pool). This new feature allows data in the L2ARC to remain available and viable between pool import/export cycles (including system reboots), greatly increasing the potential value of the L2ARC device.
Zstd compression algorithmOpenZFS offers transparent inline compression, controllable at per-data-set granularity. Traditionally, the algorithm most commonly used has been lz4, a streaming algorithm offering relatively poor compress ratio but very light CPU loading. OpenZFS 2.0.0 brings support for zstd -- an algorithm designed by Yann Collet (the author of lz4) which aims to provide compression similar to gzip, with CPU load similar to lz4.
The x-axis is transfer speed, the y-axis is compression ratio. Look for ZSTD1-19 on the upper left in dark blue, ZSTD-FAST on the lower right in light blue, and LZ4 as a single orangish dot to the right of ZSTD-FAST.
Kjeld Schouten-LebbingZstd is the dark blue cluster on the upper left, zstd-fast is the light blue line running across the bottom of the graph, and LZ4 is the single orangish dot a bit to the right of zstd-fast's upright segment.
Kjeld Schouten-Lebbing Previous Slide Next SlideThese graphs are a bit difficult to follow -- but essentially, they show zstd achieving its goals. During compression (disk writes), zstd-2 is more efficient than even gzip-9 while maintaining high throughput.
Compared to lz4, zstd-2 achieves 50 percent higher compression in return for a 30 percent throughput penalty. On the decompression (disk read) side, the throughput penalty is slightly higher, at around 36 percent.
Keep in mind, the throughput "penalties" described assume negligible bottlenecking on the storage medium itself. In practice, most CPUs can run rings around most storage media (even relatively slow CPUs and fast SSDs). ZFS users are broadly accustomed to seeing lz4 compression accelerate workloads in the real world, not slow them down!
Redacted replicationThis one's a bit of a brain-breaker. Let's say there are portions of your data that you don't want to back up using ZFS replication. First, you clone the data set. Next, you delete the sensitive data from the clone. Then, you create a bookmark on the parent data set, which marks the blocks which changed from the parent to the clone. Finally, you can send the parent data set to its backup target, including the
Additional improvements and changes--redact redaction_bookmarkargument -- and this replicates the non sensitive blocks only to the backup target.In addition to the major features outlined above, OpenZFS 2.0.0 brings
fallocatesupport; improved and reorganizedmanpages; higher performance forzfs destroy,zfs send, andzfs receive;more efficient memory management; and optimized encryption performance. Meanwhile, some infrequently used features -- deduplicated send streams, dedupditto blocks, and the zfs_vdev_scheduler module option -- have all been deprecated.For a full list of changes, please see the original release announcement on GitHub at https://github.com/openzfs/zfs/releases/tag/zfs-2.0.0 .
Stack Overflow
hasen ,What exactly is RESTful programming? What exactly is RESTful programming?kushalvm ,see also the answer at the following link stackoverflow.com/a/37683965/3762855 – Ciro Corvino Jun 7 '16 at 19:59Shirgill Farhan , 2015-04-15 11:26:17An architectural style called An architectural style called REST (Representational State Transfer) advocates that web applications should use HTTP as it was originally envisioned . Lookups should useHoCo_ ,GETrequests.PUT,POST, andDELETErequests should be used for mutation, creation, and deletion respectively . REST proponents tend to favor URLs, such as REST proponents tend to favor URLs, such as REST proponents tend to favor URLs, such ashttp://myserver.com/catalog/item/1729but the REST architecture does not require these "pretty URLs". A GET request with a parameter but the REST architecture does not require these "pretty URLs". A GET request with a parameterhttp://myserver.com/catalog?item=1729is every bit as RESTful. Keep in mind that GET requests should never be used for updating information. For example, a GET request for adding an item to a cart is every bit as RESTful. Keep in mind that GET requests should never be used for updating information. For example, a GET request for adding an item to a cart Keep in mind that GET requests should never be used for updating information. For example, a GET request for adding an item to a cart Keep in mind that GET requests should never be used for updating information. For example, a GET request for adding an item to a carthttp://myserver.com/addToCart?cart=314159&item=1729would not be appropriate. GET requests should be would not be appropriate. GET requests should be idempotent . That is, issuing a request twice should be no different from issuing it once. That's what makes the requests cacheable. An "add to cart" request is not idempotent -- issuing it twice adds two copies of the item to the cart. A POST request is clearly appropriate in this context. Thus, even a RESTful web application needs its share of POST requests. This is taken from the excellent book This is taken from the excellent book This is taken from the excellent book Core JavaServer faces book by David M. Geary.Lisiting Available Idempotent Operations: GET(Safe), PUT & DELETE (Exception is mentioned in this link restapitutorial.com/lessons/idempotency.html). Additional Reference for Safe & Idempotent Methods w3.org/Protocols/rfc2616/rfc2616-sec9.html – Abhijeet Jul 21 '15 at 4:0022 revs, 15 users 88% , 2019-04-10 15:31:47REST is the underlying architectural principle of the web. The amazing thing about the web is the fact that clients (browsers) and servers can interact in complex ways without the client knowing anything beforehand about the server and the resources it hosts. The key constraint is that the server and client must both agree on the media used, which in the case of the web is HTML . An API that adheres to the principles of An API that adheres to the principles of An API that adheres to the principles of REST does not require the client to know anything about the structure of the API. Rather, the server needs to provide whatever information the client needs to interact with the service. An HTML form is an example of this: The server specifies the location of the resource and the required fields. The browser doesn't know in advance where to submit the information, and it doesn't know in advance what information to submit. Both forms of information are entirely supplied by the server. (This principle is called HATEOAS : Hypermedia As The Engine Of Application State .) So, how does this apply to So, how does this apply to So, how does this apply to HTTP , and how can it be implemented in practice? HTTP is oriented around verbs and resources. The two verbs in mainstream usage areT.R. ,GETandPOST, which I think everyone will recognize. However, the HTTP standard defines several others such asPUTandDELETE. These verbs are then applied to resources, according to the instructions provided by the server. For example, Let's imagine that we have a user database that is managed by a web service. Our service uses a custom hypermedia based on JSON, for which we assign the mimetype For example, Let's imagine that we have a user database that is managed by a web service. Our service uses a custom hypermedia based on JSON, for which we assign the mimetype For example, Let's imagine that we have a user database that is managed by a web service. Our service uses a custom hypermedia based on JSON, for which we assign the mimetypeapplication/json+userdb(There might also be anapplication/xml+userdbandapplication/whatever+userdb- many media types may be supported). The client and the server have both been programmed to understand this format, but they don't know anything about each other. As Roy Fielding points out:A REST API should spend almost all of its descriptive effort in defining the media type(s) used for representing resources and driving application state, or in defining extended relation names and/or hypertext-enabled mark-up for existing standard media types. A REST API should spend almost all of its descriptive effort in defining the media type(s) used for representing resources and driving application state, or in defining extended relation names and/or hypertext-enabled mark-up for existing standard media types.A request for the base resource A request for the base resource/might return something like this: Request Request RequestGET / Accept: application/json+userdbResponse Response200 OK Content-Type: application/json+userdb { "version": "1.0", "links": [ { "href": "/user", "rel": "list", "method": "GET" }, { "href": "/user", "rel": "create", "method": "POST" } ] }We know from the description of our media that we can find information about related resources from sections called "links". This is called We know from the description of our media that we can find information about related resources from sections called "links". This is called Hypermedia controls . In this case, we can tell from such a section that we can find a user list by making another request for/user: Request Request RequestGET /user Accept: application/json+userdbResponse Response200 OK Content-Type: application/json+userdb { "users": [ { "id": 1, "name": "Emil", "country: "Sweden", "links": [ { "href": "/user/1", "rel": "self", "method": "GET" }, { "href": "/user/1", "rel": "edit", "method": "PUT" }, { "href": "/user/1", "rel": "delete", "method": "DELETE" } ] }, { "id": 2, "name": "Adam", "country: "Scotland", "links": [ { "href": "/user/2", "rel": "self", "method": "GET" }, { "href": "/user/2", "rel": "edit", "method": "PUT" }, { "href": "/user/2", "rel": "delete", "method": "DELETE" } ] } ], "links": [ { "href": "/user", "rel": "create", "method": "POST" } ] }We can tell a lot from this response. For instance, we now know we can create a new user by We can tell a lot from this response. For instance, we now know we can create a new user byPOSTing to/user: Request Request RequestPOST /user Accept: application/json+userdb Content-Type: application/json+userdb { "name": "Karl", "country": "Austria" }Response Response201 Created Content-Type: application/json+userdb { "user": { "id": 3, "name": "Karl", "country": "Austria", "links": [ { "href": "/user/3", "rel": "self", "method": "GET" }, { "href": "/user/3", "rel": "edit", "method": "PUT" }, { "href": "/user/3", "rel": "delete", "method": "DELETE" } ] }, "links": { "href": "/user", "rel": "list", "method": "GET" } }We also know that we can change existing data: Request We also know that we can change existing data: Request Request RequestPUT /user/1 Accept: application/json+userdb Content-Type: application/json+userdb { "name": "Emil", "country": "Bhutan" }Response Response200 OK Content-Type: application/json+userdb { "user": { "id": 1, "name": "Emil", "country": "Bhutan", "links": [ { "href": "/user/1", "rel": "self", "method": "GET" }, { "href": "/user/1", "rel": "edit", "method": "PUT" }, { "href": "/user/1", "rel": "delete", "method": "DELETE" } ] }, "links": { "href": "/user", "rel": "list", "method": "GET" } }Notice that we are using different HTTP verbs ( Notice that we are using different HTTP verbs (GET,PUT,POST,DELETEetc.) to manipulate these resources, and that the only knowledge we presume on the client's part is our media definition. Further reading: Further reading: Further reading:(This answer has been the subject of a fair amount of criticism for missing the point. For the most part, that has been a fair critique. What I originally described was more in line with how REST was usually implemented a few years ago when I first wrote this, rather than its true meaning. I've revised the answer to better represent the real meaning.) (This answer has been the subject of a fair amount of criticism for missing the point. For the most part, that has been a fair critique. What I originally described was more in line with how REST was usually implemented a few years ago when I first wrote this, rather than its true meaning. I've revised the answer to better represent the real meaning.)
- The many much better answers on this very page.
How I explained REST to my wife .- How I explained REST to my wife .
- Martin Fowler's thoughts
- PayPal's API has hypermedia controls
No. REST didn't just pop up as another buzzword. It came about as a means of describing an alternative to SOAP-based data exchange. The term REST helps frame the discussion about how to transfer and access data. – tvanfosson Mar 22 '09 at 15:11D.Shawley , 2009-03-22 19:37:57RESTful programming is about: RESTful programming is about:Philip Couling ,The last one is probably the most important in terms of consequences and overall effectiveness of REST. Overall, most of the RESTful discussions seem to center on HTTP and its usage from a browser and what not. I understand that R. Fielding coined the term when he described the architecture and decisions that lead to HTTP. His thesis is more about the architecture and cache-ability of resources than it is about HTTP. If you are really interested in what a RESTful architecture is and why it works, read The last one is probably the most important in terms of consequences and overall effectiveness of REST. Overall, most of the RESTful discussions seem to center on HTTP and its usage from a browser and what not. I understand that R. Fielding coined the term when he described the architecture and decisions that lead to HTTP. His thesis is more about the architecture and cache-ability of resources than it is about HTTP. If you are really interested in what a RESTful architecture is and why it works, read If you are really interested in what a RESTful architecture is and why it works, read If you are really interested in what a RESTful architecture is and why it works, read his thesis a few times and read the whole thing not just Chapter 5! Next look into why DNS works . Read about the hierarchical organization of DNS and how referrals work. Then read and consider how DNS caching works. Finally, read the HTTP specifications ( RFC2616 and RFC3040 in particular) and consider how and why the caching works the way that it does. Eventually, it will just click. The final revelation for me was when I saw the similarity between DNS and HTTP. After this, understanding why SOA and Message Passing Interfaces are scalable starts to click. I think that the most important trick to understanding the architectural importance and performance implications of a RESTful and I think that the most important trick to understanding the architectural importance and performance implications of a RESTful and I think that the most important trick to understanding the architectural importance and performance implications of a RESTful and Shared Nothing architectures is to avoid getting hung up on the technology and implementation details. Concentrate on who owns resources, who is responsible for creating/maintaining them, etc. Then think about the representations, protocols, and technologies.
- resources being identified by a persistent identifier: URIs are the ubiquitous choice of identifier these days
- resources being manipulated using a common set of verbs: HTTP methods are the commonly seen case - the venerable
Create,Retrieve,Update,DeletebecomesPOST,GET,PUT, andDELETE. But REST is not limited to HTTP, it is just the most commonly used transport right now.- the actual representation retrieved for a resource is dependent on the request and not the identifier: use Accept headers to control whether you want XML, HTTP, or even a Java Object representing the resource
- maintaining the state in the object and representing the state in the representation
- representing the relationships between resources in the representation of the resource: the links between objects are embedded directly in the representation
- resource representations describe how the representation can be used and under what circumstances it should be discarded/refetched in a consistent manner: usage of HTTP Cache-Control headers
An answer providing a reading list is very appropriate for this question. – ellisbben Feb 1 '12 at 19:50pbreitenbach ,This is what it might look like. Create a user with three properties: This is what it might look like. Create a user with three properties: Create a user with three properties: Create a user with three properties:Himanshu Ahuja ,POST /user fname=John&lname=Doe&age=25The server responds: The server responds:200 OK Location: /user/123In the future, you can then retrieve the user information: In the future, you can then retrieve the user information:GET /user/123The server responds: The server responds:200 OK <fname>John</fname><lname>Doe</lname><age>25</age>To modify the record ( To modify the record (lnameandagewill remain unchanged):PATCH /user/123 fname=JohnnyTo update the record (and consequently To update the record (and consequentlylnameandagewill be NULL):PUT /user/123 fname=JohnnyFor me this answer captured the essence of the desired answer. Simple and pragmatic. Granted there are lots of other criteria, but the example provided is a great launch pad. – CyberFonic Feb 1 '12 at 22:0914 revs, 4 users 94% , 2013-09-08 17:43:09A great book on REST is A great book on REST is REST in Practice . Must reads are Must reads are Must reads are Representational State Transfer (REST) and REST APIs must be hypertext-driven See Martin Fowlers article the See Martin Fowlers article the See Martin Fowlers article the Richardson Maturity Model (RMM) for an explanation on what an RESTful service is. To be RESTful a Service needs to fulfill the To be RESTful a Service needs to fulfill the To be RESTful a Service needs to fulfill the To be RESTful a Service needs to fulfill the To be RESTful a Service needs to fulfill the Hypermedia as the Engine of Application State. (HATEOAS) , that is, it needs to reach level 3 in the RMM, read the article for details or the slides from the qcon talk .Brent Bradburn ,The HATEOAS constraint is an acronym for Hypermedia as the Engine of Application State. This principle is the key differentiator between a REST and most other forms of client server system. ... A client of a RESTful application need only know a single fixed URL to access it. All future actions should be discoverable dynamically from hypermedia links included in the representations of the resources that are returned from that URL. Standardized media types are also expected to be understood by any client that might use a RESTful API. (From Wikipedia, the free encyclopedia) The HATEOAS constraint is an acronym for Hypermedia as the Engine of Application State. This principle is the key differentiator between a REST and most other forms of client server system. ... A client of a RESTful application need only know a single fixed URL to access it. All future actions should be discoverable dynamically from hypermedia links included in the representations of the resources that are returned from that URL. Standardized media types are also expected to be understood by any client that might use a RESTful API. (From Wikipedia, the free encyclopedia) ... A client of a RESTful application need only know a single fixed URL to access it. All future actions should be discoverable dynamically from hypermedia links included in the representations of the resources that are returned from that URL. Standardized media types are also expected to be understood by any client that might use a RESTful API. (From Wikipedia, the free encyclopedia) ... A client of a RESTful application need only know a single fixed URL to access it. All future actions should be discoverable dynamically from hypermedia links included in the representations of the resources that are returned from that URL. Standardized media types are also expected to be understood by any client that might use a RESTful API. (From Wikipedia, the free encyclopedia) A client of a RESTful application need only know a single fixed URL to access it. All future actions should be discoverable dynamically from hypermedia links included in the representations of the resources that are returned from that URL. Standardized media types are also expected to be understood by any client that might use a RESTful API. (From Wikipedia, the free encyclopedia) A client of a RESTful application need only know a single fixed URL to access it. All future actions should be discoverable dynamically from hypermedia links included in the representations of the resources that are returned from that URL. Standardized media types are also expected to be understood by any client that might use a RESTful API. (From Wikipedia, the free encyclopedia)REST Litmus Test for Web Frameworks is a similar maturity test for web frameworks. Approaching pure REST: Learning to love HATEOAS is a good collection of links. REST versus SOAP for the Public Cloud discusses the current levels of REST usage. REST and versioning discusses Extensibility, Versioning, Evolvability, etc. through ModifiabilityI think this answer touches the key point of understanding REST: what does the word representational mean. Level 1 - Resources says about state . Level 2 - HTTP Verbs says about transfer (read change ). Level 3 - HATEOAS says driving future transfers via representation (JSON/XML/HTML returned), which means you've got known how to say the next round of talk with the information returned. So REST reads: "(representational (state transfer))", instead of "((representational state) transfer)". – lcn Dec 9 '14 at 19:49Ravi , 2012-11-18 20:46:20Chaklader Asfak Arefe ,What is REST? REST stands for Representational State Transfer. (It is sometimes spelled "ReST".) It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. What is REST? REST stands for Representational State Transfer. (It is sometimes spelled "ReST".) It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. REST stands for Representational State Transfer. (It is sometimes spelled "ReST".) It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. REST stands for Representational State Transfer. (It is sometimes spelled "ReST".) It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. REST is a lightweight alternative to mechanisms like RPC (Remote Procedure Calls) and Web Services (SOAP, WSDL, et al.). Later, we will see how much more simple REST is. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#. Despite being simple, REST is fully-featured; there's basically nothing you can do in Web Services that can't be done with a RESTful architecture. REST is not a "standard". There will never be a W3C recommendataion for REST, for example. And while there are REST programming frameworks, working with REST is so simple that you can often "roll your own" with standard library features in languages like Perl, Java, or C#.One of the best reference I found when I try to find the simple real meaning of rest. One of the best reference I found when I try to find the simple real meaning of rest. http://rest.elkstein.org/This is a really concise answer. Can you also describe why the REST is called stateless? – Chaklader Asfak Arefe Feb 12 '19 at 17:15dbr ,REST is using the various HTTP methods (mainly GET/PUT/DELETE) to manipulate data. Rather than using a specific URL to delete a method (say, REST is using the various HTTP methods (mainly GET/PUT/DELETE) to manipulate data. Rather than using a specific URL to delete a method (say, Rather than using a specific URL to delete a method (say, Rather than using a specific URL to delete a method (say,Spencer Ruport ,/user/123/delete), you would send a DELETE request to the/user/[id]URL, to edit a user, to retrieve info on a user you send a GET request to/user/[id]For example, instead a set of URLs which might look like some of the following.. For example, instead a set of URLs which might look like some of the following.. For example, instead a set of URLs which might look like some of the following..GET /delete_user.x?id=123 GET /user/delete GET /new_user.x GET /user/new GET /user?id=1 GET /user/id/1You use the HTTP "verbs" and have.. You use the HTTP "verbs" and have..GET /user/2 DELETE /user/2 PUT /userThat's "using HTTP properly", which is not the same as "restful" (although it's related to it) – Julian Reschke Mar 22 '09 at 15:56Hank Gay ,It's programming where the architecture of your system fits the It's programming where the architecture of your system fits the REST style laid out by Roy Fielding in his thesis . Since this is the architectural style that describes the web (more or less), lots of people are interested in it. Bonus answer: No. Unless you're studying software architecture as an academic or designing web services, there's really no reason to have heard the term. Bonus answer: No. Unless you're studying software architecture as an academic or designing web services, there's really no reason to have heard the term. Bonus answer: No. Unless you're studying software architecture as an academic or designing web services, there's really no reason to have heard the term.moodboom ,but not straight-forward .. makes it more complicated that it needs to be. – hasen Mar 22 '09 at 15:38Only You , 2013-07-12 16:33:02I would say RESTful programming would be about creating systems (API) that follow the REST architectural style. I found this fantastic, short, and easy to understand tutorial about REST by Dr. M. Elkstein and quoting the essential part that would answer your question for the most part: I would say RESTful programming would be about creating systems (API) that follow the REST architectural style. I found this fantastic, short, and easy to understand tutorial about REST by Dr. M. Elkstein and quoting the essential part that would answer your question for the most part: I found this fantastic, short, and easy to understand tutorial about REST by Dr. M. Elkstein and quoting the essential part that would answer your question for the most part: I found this fantastic, short, and easy to understand tutorial about REST by Dr. M. Elkstein and quoting the essential part that would answer your question for the most part: Learn REST: A TutorialOnly You ,REST is an REST is an architecture style for designing networked applications. The idea is that, rather than using complex mechanisms such as CORBA, RPC or SOAP to connect between machines, simple HTTP is used to make calls between machines.I don't think you should feel stupid for not hearing about REST outside Stack Overflow..., I would be in the same situation!; answers to this other SO question on I don't think you should feel stupid for not hearing about REST outside Stack Overflow..., I would be in the same situation!; answers to this other SO question on Why is REST getting big now could ease some feelings.RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations. RESTful applications use HTTP requests to post data (create and/or update), read data (e.g., make queries), and delete data. Thus, REST uses HTTP for all four CRUD (Create/Read/Update/Delete) operations.
- In many ways, the World Wide Web itself, based on HTTP, can be viewed as a REST-based architecture.
This article explains the relationship between HTTP and REST freecodecamp.org/news/ – Only You Sep 21 '19 at 21:32tompark , 2009-03-23 17:11:58I apologize if I'm not answering the question directly, but it's easier to understand all this with more detailed examples. Fielding is not easy to understand due to all the abstraction and terminology. There's a fairly good example here: I apologize if I'm not answering the question directly, but it's easier to understand all this with more detailed examples. Fielding is not easy to understand due to all the abstraction and terminology. There's a fairly good example here: There's a fairly good example here: There's a fairly good example here: Explaining REST and Hypertext: Spam-E the Spam Cleaning Robot And even better, there's a clean explanation with simple examples here (the powerpoint is more comprehensive, but you can get most of it in the html version): And even better, there's a clean explanation with simple examples here (the powerpoint is more comprehensive, but you can get most of it in the html version): And even better, there's a clean explanation with simple examples here (the powerpoint is more comprehensive, but you can get most of it in the html version): http://www.xfront.com/REST.ppt or http://www.xfront.com/REST.html After reading the examples, I could see why Ken is saying that REST is hypertext-driven. I'm not actually sure that he's right though, because that /user/123 is a URI that points to a resource, and it's not clear to me that it's unRESTful just because the client knows about it "out-of-band." That xfront document explains the difference between REST and SOAP, and this is really helpful too. When Fielding says, " After reading the examples, I could see why Ken is saying that REST is hypertext-driven. I'm not actually sure that he's right though, because that /user/123 is a URI that points to a resource, and it's not clear to me that it's unRESTful just because the client knows about it "out-of-band." That xfront document explains the difference between REST and SOAP, and this is really helpful too. When Fielding says, " After reading the examples, I could see why Ken is saying that REST is hypertext-driven. I'm not actually sure that he's right though, because that /user/123 is a URI that points to a resource, and it's not clear to me that it's unRESTful just because the client knows about it "out-of-band." That xfront document explains the difference between REST and SOAP, and this is really helpful too. When Fielding says, " That xfront document explains the difference between REST and SOAP, and this is really helpful too. When Fielding says, " That xfront document explains the difference between REST and SOAP, and this is really helpful too. When Fielding says, " That is RPC. It screams RPC. ", it's clear that RPC is not RESTful, so it's useful to see the exact reasons for this. (SOAP is a type of RPC.)coder_tim ,cool links, thanks. I'm tired of these REST guys that say some example is not "REST-ful", but then refuse to say how to change the example to be REST-ful. – coder_tim Feb 1 '12 at 19:19Suresh Gupta , 2013-07-25 09:05:19What is REST? REST in official words, REST is an architectural style built on certain principles using the current "Web" fundamentals. There are 5 basic fundamentals of web which are leveraged to create REST services. What is REST? REST in official words, REST is an architectural style built on certain principles using the current "Web" fundamentals. There are 5 basic fundamentals of web which are leveraged to create REST services. REST in official words, REST is an architectural style built on certain principles using the current "Web" fundamentals. There are 5 basic fundamentals of web which are leveraged to create REST services. REST in official words, REST is an architectural style built on certain principles using the current "Web" fundamentals. There are 5 basic fundamentals of web which are leveraged to create REST services.mendez7 ,
- Principle 1: Everything is a Resource In the REST architectural style, data and functionality are considered resources and are accessed using Uniform Resource Identifiers (URIs), typically links on the Web.
- Principle 2: Every Resource is Identified by a Unique Identifier (URI)
- Principle 3: Use Simple and Uniform Interfaces
- Principle 4: Communication is Done by Representation
- Principle 5: Be Stateless
What doesKen , 2009-03-22 16:36:31Communication is Done by Representationmean? – mendez7 Mar 10 '19 at 21:59I see a bunch of answers that say putting everything about user 123 at resource "/user/123" is RESTful. Roy Fielding, who coined the term, says I see a bunch of answers that say putting everything about user 123 at resource "/user/123" is RESTful. Roy Fielding, who coined the term, says Roy Fielding, who coined the term, says Roy Fielding, who coined the term, says REST APIs must be hypertext-driven . In particular, "A REST API must not define fixed resource names or hierarchies". So if your "/user/123" path is hardcoded on the client, it's not really RESTful. A good use of HTTP, maybe, maybe not. But not RESTful. It has to come from hypertext. So if your "/user/123" path is hardcoded on the client, it's not really RESTful. A good use of HTTP, maybe, maybe not. But not RESTful. It has to come from hypertext. So if your "/user/123" path is hardcoded on the client, it's not really RESTful. A good use of HTTP, maybe, maybe not. But not RESTful. It has to come from hypertext.MSalters ,so .... how would that example be restful? how would you change the url to make it restful? – hasen Mar 22 '09 at 16:49inf3rno , 2013-11-22 22:49:13The answer is very simple, there is a The answer is very simple, there is a dissertation written by Roy Fielding.] 1 In that dissertation he defines the REST principles. If an application fulfills all of those principles, then that is a REST application. The term RESTful was created because ppl exhausted the word REST by calling their non-REST application as REST. After that the term RESTful was exhausted as well. Nowadays we are talking about Web APIs and Hypermedia APIs , because the most of the so called REST applications did not fulfill the HATEOAS part of the uniform interface constraint. The REST constraints are the following: The REST constraints are the following: The REST constraints are the following:> ,REST constraints result a highly scalable system in where the clients are decoupled from the implementations of the services. So the clients can be reusable, general just like the browsers on the web. The clients and the services share the same standards and vocabs, so they can understand each other despite the fact that the client does not know the implementation details of the service. This makes possible to create automated clients which can find and utilize REST services to achieve their goals. In long term these clients can communicate to each other and trust each other with tasks, just like humans do. If we add learning patterns to such clients, then the result will be one or more AI using the web of machines instead of a single server park. So at the end the dream of Berners Lee: the semantic web and the artificial intelligence will be reality. So in 2030 we end up terminated by the Skynet. Until then ... ;-) REST constraints result a highly scalable system in where the clients are decoupled from the implementations of the services. So the clients can be reusable, general just like the browsers on the web. The clients and the services share the same standards and vocabs, so they can understand each other despite the fact that the client does not know the implementation details of the service. This makes possible to create automated clients which can find and utilize REST services to achieve their goals. In long term these clients can communicate to each other and trust each other with tasks, just like humans do. If we add learning patterns to such clients, then the result will be one or more AI using the web of machines instead of a single server park. So at the end the dream of Berners Lee: the semantic web and the artificial intelligence will be reality. So in 2030 we end up terminated by the Skynet. Until then ... ;-)
- client-server architecture So it does not work with for example PUB/SUB sockets, it is based on REQ/REP. client-server architecture So it does not work with for example PUB/SUB sockets, it is based on REQ/REP. So it does not work with for example PUB/SUB sockets, it is based on REQ/REP. So it does not work with for example PUB/SUB sockets, it is based on REQ/REP.
- stateless communication So the server does not maintain the states of the clients. This means that you cannot use server a side session storage and you have to authenticate every request. Your clients possibly send basic auth headers through an encrypted connection. (By large applications it is hard to maintain many sessions.) stateless communication So the server does not maintain the states of the clients. This means that you cannot use server a side session storage and you have to authenticate every request. Your clients possibly send basic auth headers through an encrypted connection. (By large applications it is hard to maintain many sessions.) So the server does not maintain the states of the clients. This means that you cannot use server a side session storage and you have to authenticate every request. Your clients possibly send basic auth headers through an encrypted connection. (By large applications it is hard to maintain many sessions.) So the server does not maintain the states of the clients. This means that you cannot use server a side session storage and you have to authenticate every request. Your clients possibly send basic auth headers through an encrypted connection. (By large applications it is hard to maintain many sessions.)
- usage of cache if you can So you don't have to serve the same requests again and again. usage of cache if you can So you don't have to serve the same requests again and again. So you don't have to serve the same requests again and again. So you don't have to serve the same requests again and again.
- uniform interface as common contract between client and server The contract between the client and the server is not maintained by the server. In other words the client must be decoupled from the implementation of the service. You can reach this state by using standard solutions, like the IRI (URI) standard to identify resources, the HTTP standard to exchange messages, standard MIME types to describe the body serialization format, metadata (possibly RDF vocabs, microformats, etc.) to describe the semantics of different parts of the message body. To decouple the IRI structure from the client, you have to send hyperlinks to the clients in hypermedia formats like (HTML, JSON-LD, HAL, etc.). So a client can use the metadata (possibly link relations, RDF vocabs) assigned to the hyperlinks to navigate the state machine of the application through the proper state transitions in order to achieve its current goal. For example when a client wants to send an order to a webshop, then it have to check the hyperlinks in the responses sent by the webshop. By checking the links it founds one described with the uniform interface as common contract between client and server The contract between the client and the server is not maintained by the server. In other words the client must be decoupled from the implementation of the service. You can reach this state by using standard solutions, like the IRI (URI) standard to identify resources, the HTTP standard to exchange messages, standard MIME types to describe the body serialization format, metadata (possibly RDF vocabs, microformats, etc.) to describe the semantics of different parts of the message body. To decouple the IRI structure from the client, you have to send hyperlinks to the clients in hypermedia formats like (HTML, JSON-LD, HAL, etc.). So a client can use the metadata (possibly link relations, RDF vocabs) assigned to the hyperlinks to navigate the state machine of the application through the proper state transitions in order to achieve its current goal. For example when a client wants to send an order to a webshop, then it have to check the hyperlinks in the responses sent by the webshop. By checking the links it founds one described with the The contract between the client and the server is not maintained by the server. In other words the client must be decoupled from the implementation of the service. You can reach this state by using standard solutions, like the IRI (URI) standard to identify resources, the HTTP standard to exchange messages, standard MIME types to describe the body serialization format, metadata (possibly RDF vocabs, microformats, etc.) to describe the semantics of different parts of the message body. To decouple the IRI structure from the client, you have to send hyperlinks to the clients in hypermedia formats like (HTML, JSON-LD, HAL, etc.). So a client can use the metadata (possibly link relations, RDF vocabs) assigned to the hyperlinks to navigate the state machine of the application through the proper state transitions in order to achieve its current goal. For example when a client wants to send an order to a webshop, then it have to check the hyperlinks in the responses sent by the webshop. By checking the links it founds one described with the The contract between the client and the server is not maintained by the server. In other words the client must be decoupled from the implementation of the service. You can reach this state by using standard solutions, like the IRI (URI) standard to identify resources, the HTTP standard to exchange messages, standard MIME types to describe the body serialization format, metadata (possibly RDF vocabs, microformats, etc.) to describe the semantics of different parts of the message body. To decouple the IRI structure from the client, you have to send hyperlinks to the clients in hypermedia formats like (HTML, JSON-LD, HAL, etc.). So a client can use the metadata (possibly link relations, RDF vocabs) assigned to the hyperlinks to navigate the state machine of the application through the proper state transitions in order to achieve its current goal. For example when a client wants to send an order to a webshop, then it have to check the hyperlinks in the responses sent by the webshop. By checking the links it founds one described with the For example when a client wants to send an order to a webshop, then it have to check the hyperlinks in the responses sent by the webshop. By checking the links it founds one described with the For example when a client wants to send an order to a webshop, then it have to check the hyperlinks in the responses sent by the webshop. By checking the links it founds one described with the http://schema.org/OrderAction . The client know the schema.org vocab, so it understands that by activating this hyperlink it will send the order. So it activates the hyperlink and sends a
POST https://example.com/api/v1/ordermessage with the proper body. After that the service processes the message and responds with the result having the proper HTTP status header, for example201 - createdby success. To annotate messages with detailed metadata the standard solution to use an RDF format, for example JSON-LD with a REST vocab, for example Hydra and domain specific vocabs like schema.org or any other linked data vocab and maybe a custom application specific vocab if needed. Now this is not easy, that's why most ppl use HAL and other simple formats which usually provide only a REST vocab, but no linked data support.- build a layered system to increase scalability The REST system is composed of hierarchical layers. Each layer contains components which use the services of components which are in the next layer below. So you can add new layers and components effortless. For example there is a client layer which contains the clients and below that there is a service layer which contains a single service. Now you can add a client side cache between them. After that you can add another service instance and a load balancer, and so on... The client code and the service code won't change. build a layered system to increase scalability The REST system is composed of hierarchical layers. Each layer contains components which use the services of components which are in the next layer below. So you can add new layers and components effortless. For example there is a client layer which contains the clients and below that there is a service layer which contains a single service. Now you can add a client side cache between them. After that you can add another service instance and a load balancer, and so on... The client code and the service code won't change. The REST system is composed of hierarchical layers. Each layer contains components which use the services of components which are in the next layer below. So you can add new layers and components effortless. For example there is a client layer which contains the clients and below that there is a service layer which contains a single service. Now you can add a client side cache between them. After that you can add another service instance and a load balancer, and so on... The client code and the service code won't change. The REST system is composed of hierarchical layers. Each layer contains components which use the services of components which are in the next layer below. So you can add new layers and components effortless. For example there is a client layer which contains the clients and below that there is a service layer which contains a single service. Now you can add a client side cache between them. After that you can add another service instance and a load balancer, and so on... The client code and the service code won't change. For example there is a client layer which contains the clients and below that there is a service layer which contains a single service. Now you can add a client side cache between them. After that you can add another service instance and a load balancer, and so on... The client code and the service code won't change. For example there is a client layer which contains the clients and below that there is a service layer which contains a single service. Now you can add a client side cache between them. After that you can add another service instance and a load balancer, and so on... The client code and the service code won't change.
- code on demand to extend client functionality This constraint is optional. For example you can send a parser for a specific media type to the client, and so on... In order to do this you might need a standard plugin loader system in the client, or your client will be coupled to the plugin loader solution. code on demand to extend client functionality This constraint is optional. For example you can send a parser for a specific media type to the client, and so on... In order to do this you might need a standard plugin loader system in the client, or your client will be coupled to the plugin loader solution. This constraint is optional. For example you can send a parser for a specific media type to the client, and so on... In order to do this you might need a standard plugin loader system in the client, or your client will be coupled to the plugin loader solution. This constraint is optional. For example you can send a parser for a specific media type to the client, and so on... In order to do this you might need a standard plugin loader system in the client, or your client will be coupled to the plugin loader solution.
add a commentkenorb , 2014-06-15 19:02:17RESTful (Representational state transfer) API programming is writing web applications in any programming language by following 5 basic software architectural style principles:Nathan Andelin ,In other words you're writing simple point-to-point network applications over HTTP which uses verbs such as GET, POST, PUT or DELETE by implementing RESTful architecture which proposes standardization of the interface each "resource" exposes. It is nothing that using current features of the web in a simple and effective way (highly successful, proven and distributed architecture). It is an alternative to more complex mechanisms like In other words you're writing simple point-to-point network applications over HTTP which uses verbs such as GET, POST, PUT or DELETE by implementing RESTful architecture which proposes standardization of the interface each "resource" exposes. It is nothing that using current features of the web in a simple and effective way (highly successful, proven and distributed architecture). It is an alternative to more complex mechanisms like SOAP , CORBA and RPC . RESTful programming conforms to Web architecture design and, if properly implemented, it allows you to take the full advantage of scalable Web infrastructure. RESTful programming conforms to Web architecture design and, if properly implemented, it allows you to take the full advantage of scalable Web infrastructure. RESTful programming conforms to Web architecture design and, if properly implemented, it allows you to take the full advantage of scalable Web infrastructure.
- Resource (data, information).
- Unique global identifier (all resources are unique identified by URI ).
- Uniform interface - use simple and standard interface (HTTP).
- Representation - all communication is done by representation (e.g. XML / JSON )
- Stateless (every request happens in complete isolation, it's easier to cache and load-balance),
If I had to reduce the original dissertation on REST to just 3 short sentences, I think the following captures its essence: If I had to reduce the original dissertation on REST to just 3 short sentences, I think the following captures its essence:suing , 2012-02-01 21:20:21After that, it's easy to fall into debates about adaptations, coding conventions, and best practices. Interestingly, there is no mention of HTTP POST, GET, DELETE, or PUT operations in the dissertation. That must be someone's later interpretation of a "best practice" for a "uniform interface". When it comes to web services, it seems that we need some way of distinguishing WSDL and SOAP based architectures which add considerable overhead and arguably much unnecessary complexity to the interface. They also require additional frameworks and developer tools in order to implement. I'm not sure if REST is the best term to distinguish between common-sense interfaces and overly engineered interfaces such as WSDL and SOAP. But we need something. After that, it's easy to fall into debates about adaptations, coding conventions, and best practices. Interestingly, there is no mention of HTTP POST, GET, DELETE, or PUT operations in the dissertation. That must be someone's later interpretation of a "best practice" for a "uniform interface". When it comes to web services, it seems that we need some way of distinguishing WSDL and SOAP based architectures which add considerable overhead and arguably much unnecessary complexity to the interface. They also require additional frameworks and developer tools in order to implement. I'm not sure if REST is the best term to distinguish between common-sense interfaces and overly engineered interfaces such as WSDL and SOAP. But we need something. Interestingly, there is no mention of HTTP POST, GET, DELETE, or PUT operations in the dissertation. That must be someone's later interpretation of a "best practice" for a "uniform interface". When it comes to web services, it seems that we need some way of distinguishing WSDL and SOAP based architectures which add considerable overhead and arguably much unnecessary complexity to the interface. They also require additional frameworks and developer tools in order to implement. I'm not sure if REST is the best term to distinguish between common-sense interfaces and overly engineered interfaces such as WSDL and SOAP. But we need something. Interestingly, there is no mention of HTTP POST, GET, DELETE, or PUT operations in the dissertation. That must be someone's later interpretation of a "best practice" for a "uniform interface". When it comes to web services, it seems that we need some way of distinguishing WSDL and SOAP based architectures which add considerable overhead and arguably much unnecessary complexity to the interface. They also require additional frameworks and developer tools in order to implement. I'm not sure if REST is the best term to distinguish between common-sense interfaces and overly engineered interfaces such as WSDL and SOAP. But we need something. When it comes to web services, it seems that we need some way of distinguishing WSDL and SOAP based architectures which add considerable overhead and arguably much unnecessary complexity to the interface. They also require additional frameworks and developer tools in order to implement. I'm not sure if REST is the best term to distinguish between common-sense interfaces and overly engineered interfaces such as WSDL and SOAP. But we need something. When it comes to web services, it seems that we need some way of distinguishing WSDL and SOAP based architectures which add considerable overhead and arguably much unnecessary complexity to the interface. They also require additional frameworks and developer tools in order to implement. I'm not sure if REST is the best term to distinguish between common-sense interfaces and overly engineered interfaces such as WSDL and SOAP. But we need something.
- Resources are requested via URLs.
- Protocols are limited to what you can communicate by using URLs.
- Metadata is passed as name-value pairs (post data and query string parameters).
REST is an architectural pattern and style of writing distributed applications. It is not a programming style in the narrow sense. Saying you use the REST style is similar to saying that you built a house in a particular style: for example Tudor or Victorian. Both REST as an software style and Tudor or Victorian as a home style can be defined by the qualities and constraints that make them up. For example REST must have Client Server separation where messages are self-describing. Tudor style homes have Overlapping gables and Roofs that are steeply pitched with front facing gables. You can read Roy's dissertation to learn more about the constraints and qualities that make up REST. REST unlike home styles has had a tough time being consistently and practically applied. This may have been intentional. Leaving its actual implementation up to the designer. So you are free to do what you want so as long as you meet the constraints set out in the dissertation you are creating REST Systems. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. REST is an architectural pattern and style of writing distributed applications. It is not a programming style in the narrow sense. Saying you use the REST style is similar to saying that you built a house in a particular style: for example Tudor or Victorian. Both REST as an software style and Tudor or Victorian as a home style can be defined by the qualities and constraints that make them up. For example REST must have Client Server separation where messages are self-describing. Tudor style homes have Overlapping gables and Roofs that are steeply pitched with front facing gables. You can read Roy's dissertation to learn more about the constraints and qualities that make up REST. REST unlike home styles has had a tough time being consistently and practically applied. This may have been intentional. Leaving its actual implementation up to the designer. So you are free to do what you want so as long as you meet the constraints set out in the dissertation you are creating REST Systems. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. Saying you use the REST style is similar to saying that you built a house in a particular style: for example Tudor or Victorian. Both REST as an software style and Tudor or Victorian as a home style can be defined by the qualities and constraints that make them up. For example REST must have Client Server separation where messages are self-describing. Tudor style homes have Overlapping gables and Roofs that are steeply pitched with front facing gables. You can read Roy's dissertation to learn more about the constraints and qualities that make up REST. REST unlike home styles has had a tough time being consistently and practically applied. This may have been intentional. Leaving its actual implementation up to the designer. So you are free to do what you want so as long as you meet the constraints set out in the dissertation you are creating REST Systems. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. Saying you use the REST style is similar to saying that you built a house in a particular style: for example Tudor or Victorian. Both REST as an software style and Tudor or Victorian as a home style can be defined by the qualities and constraints that make them up. For example REST must have Client Server separation where messages are self-describing. Tudor style homes have Overlapping gables and Roofs that are steeply pitched with front facing gables. You can read Roy's dissertation to learn more about the constraints and qualities that make up REST. REST unlike home styles has had a tough time being consistently and practically applied. This may have been intentional. Leaving its actual implementation up to the designer. So you are free to do what you want so as long as you meet the constraints set out in the dissertation you are creating REST Systems. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. REST unlike home styles has had a tough time being consistently and practically applied. This may have been intentional. Leaving its actual implementation up to the designer. So you are free to do what you want so as long as you meet the constraints set out in the dissertation you are creating REST Systems. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. REST unlike home styles has had a tough time being consistently and practically applied. This may have been intentional. Leaving its actual implementation up to the designer. So you are free to do what you want so as long as you meet the constraints set out in the dissertation you are creating REST Systems. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. Bonus: The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps. The entire web is based on REST (or REST was based on the web). Therefore as a web developer you might want aware of that although it's not necessary to write good web apps.Kal , 2017-03-31 03:12:53Here is my basic outline of REST. I tried to demonstrate the thinking behind each of the components in a RESTful architecture so that understanding the concept is more intuitive. Hopefully this helps demystify REST for some people! REST (Representational State Transfer) is a design architecture that outlines how networked resources (i.e. nodes that share information) are designed and addressed. In general, a RESTful architecture makes it so that the client (the requesting machine) and the server (the responding machine) can request to read, write, and update data without the client having to know how the server operates and the server can pass it back without needing to know anything about the client. Okay, cool...but how do we do this in practice? Here is my basic outline of REST. I tried to demonstrate the thinking behind each of the components in a RESTful architecture so that understanding the concept is more intuitive. Hopefully this helps demystify REST for some people! REST (Representational State Transfer) is a design architecture that outlines how networked resources (i.e. nodes that share information) are designed and addressed. In general, a RESTful architecture makes it so that the client (the requesting machine) and the server (the responding machine) can request to read, write, and update data without the client having to know how the server operates and the server can pass it back without needing to know anything about the client. Okay, cool...but how do we do this in practice? REST (Representational State Transfer) is a design architecture that outlines how networked resources (i.e. nodes that share information) are designed and addressed. In general, a RESTful architecture makes it so that the client (the requesting machine) and the server (the responding machine) can request to read, write, and update data without the client having to know how the server operates and the server can pass it back without needing to know anything about the client. Okay, cool...but how do we do this in practice? REST (Representational State Transfer) is a design architecture that outlines how networked resources (i.e. nodes that share information) are designed and addressed. In general, a RESTful architecture makes it so that the client (the requesting machine) and the server (the responding machine) can request to read, write, and update data without the client having to know how the server operates and the server can pass it back without needing to know anything about the client. Okay, cool...but how do we do this in practice?> ,But the REST architecture doesn't end there! While the above fulfills the basic needs of what we want, we also want to have an architecture that supports high volume traffic since any given server usually handles responses from a number of clients. Thus, we don't want to overwhelm the server by having it remember information about previous requests. But the REST architecture doesn't end there! While the above fulfills the basic needs of what we want, we also want to have an architecture that supports high volume traffic since any given server usually handles responses from a number of clients. Thus, we don't want to overwhelm the server by having it remember information about previous requests.
- The most obvious requirement is that there needs to be a universal language of some sort so that the server can tell the client what it is trying to do with the request and for the server to respond. The most obvious requirement is that there needs to be a universal language of some sort so that the server can tell the client what it is trying to do with the request and for the server to respond.
- But to find any given resource and then tell the client where that resource lives, there needs to be a universal way of pointing at resources. This is where Universal Resource Identifiers (URIs) come in; they are basically unique addresses to find the resources. But to find any given resource and then tell the client where that resource lives, there needs to be a universal way of pointing at resources. This is where Universal Resource Identifiers (URIs) come in; they are basically unique addresses to find the resources.
Now, if all of this sounds familiar, then great. The Hypertext Transfer Protocol (HTTP), which defines the communication protocol via the World Wide Web is an implementation of the abstract notion of RESTful architecture (or an instance of the REST class if you're an OOP fanatic like me). In this implementation of REST, the client and server interact via GET, POST, PUT, DELETE, etc., which are part of the universal language and the resources can be pointed to using URLs. Now, if all of this sounds familiar, then great. The Hypertext Transfer Protocol (HTTP), which defines the communication protocol via the World Wide Web is an implementation of the abstract notion of RESTful architecture (or an instance of the REST class if you're an OOP fanatic like me). In this implementation of REST, the client and server interact via GET, POST, PUT, DELETE, etc., which are part of the universal language and the resources can be pointed to using URLs.
- Therefore, we impose the restriction that each request-response pair between the client and the server is independent, meaning that the server doesn't have to remember anything about previous requests (previous states of the client-server interaction) to respond to a new request. This means that we want our interactions to be stateless. Therefore, we impose the restriction that each request-response pair between the client and the server is independent, meaning that the server doesn't have to remember anything about previous requests (previous states of the client-server interaction) to respond to a new request. This means that we want our interactions to be stateless.
- To further ease the strain on our server from redoing computations that have already been recently done for a given client, REST also allows caching. Basically, caching means to take a snapshot of the initial response provided to the client. If the client makes the same request again, the server can provide the client with the snapshot rather than redo all of the computations that were necessary to create the initial response. However, since it is a snapshot, if the snapshot has not expired--the server sets an expiration time in advance--and the response has been updated since the initial cache (i.e. the request would give a different answer than the cached response), the client will not see the updates until the cache expires (or the cache is cleared) and the response is rendered from scratch again. To further ease the strain on our server from redoing computations that have already been recently done for a given client, REST also allows caching. Basically, caching means to take a snapshot of the initial response provided to the client. If the client makes the same request again, the server can provide the client with the snapshot rather than redo all of the computations that were necessary to create the initial response. However, since it is a snapshot, if the snapshot has not expired--the server sets an expiration time in advance--and the response has been updated since the initial cache (i.e. the request would give a different answer than the cached response), the client will not see the updates until the cache expires (or the cache is cleared) and the response is rendered from scratch again.
- The last thing that you'll often here about RESTful architectures is that they are layered. We have actually already been implicitly discussing this requirement in our discussion of the interaction between the client and server. Basically, this means that each layer in our system interacts only with adjacent layers. So in our discussion, the client layer interacts with our server layer (and vice versa), but there might be other server layers that help the primary server process a request that the client does not directly communicate with. Rather, the server passes on the request as necessary. The last thing that you'll often here about RESTful architectures is that they are layered. We have actually already been implicitly discussing this requirement in our discussion of the interaction between the client and server. Basically, this means that each layer in our system interacts only with adjacent layers. So in our discussion, the client layer interacts with our server layer (and vice versa), but there might be other server layers that help the primary server process a request that the client does not directly communicate with. Rather, the server passes on the request as necessary.
add a commentminghua ,I think the point of restful is the separation of the statefulness into a higher layer while making use of the internet (protocol) as a stateless transport layer . Most other approaches mix things up. It's been the best practical approach to handle the fundamental changes of programming in internet era. Regarding the fundamental changes, Erik Meijer has a discussion on show here: I think the point of restful is the separation of the statefulness into a higher layer while making use of the internet (protocol) as a stateless transport layer . Most other approaches mix things up. It's been the best practical approach to handle the fundamental changes of programming in internet era. Regarding the fundamental changes, Erik Meijer has a discussion on show here: It's been the best practical approach to handle the fundamental changes of programming in internet era. Regarding the fundamental changes, Erik Meijer has a discussion on show here: It's been the best practical approach to handle the fundamental changes of programming in internet era. Regarding the fundamental changes, Erik Meijer has a discussion on show here: http://www.infoq.com/interviews/erik-meijer-programming-language-design-effects-purity#view_93197 . He summarizes it as the five effects, and presents a solution by designing the solution into a programming language. The solution, could also be achieved in the platform or system level, regardless of the language. The restful could be seen as one of the solutions that has been very successful in the current practice. With restful style, you get and manipulate the state of the application across an unreliable internet. If it fails the current operation to get the correct and current state, it needs the zero-validation principal to help the application to continue. If it fails to manipulate the state, it usually uses multiple stages of confirmation to keep things correct. In this sense, rest is not itself a whole solution, it needs the functions in other part of the web application stack to support its working. Given this view point, the rest style is not really tied to internet or web application. It's a fundamental solution to many of the programming situations. It is not simple either, it just makes the interface really simple, and copes with other technologies amazingly well. Just my 2c. Edit: Two more important aspects: With restful style, you get and manipulate the state of the application across an unreliable internet. If it fails the current operation to get the correct and current state, it needs the zero-validation principal to help the application to continue. If it fails to manipulate the state, it usually uses multiple stages of confirmation to keep things correct. In this sense, rest is not itself a whole solution, it needs the functions in other part of the web application stack to support its working. Given this view point, the rest style is not really tied to internet or web application. It's a fundamental solution to many of the programming situations. It is not simple either, it just makes the interface really simple, and copes with other technologies amazingly well. Just my 2c. Edit: Two more important aspects: With restful style, you get and manipulate the state of the application across an unreliable internet. If it fails the current operation to get the correct and current state, it needs the zero-validation principal to help the application to continue. If it fails to manipulate the state, it usually uses multiple stages of confirmation to keep things correct. In this sense, rest is not itself a whole solution, it needs the functions in other part of the web application stack to support its working. Given this view point, the rest style is not really tied to internet or web application. It's a fundamental solution to many of the programming situations. It is not simple either, it just makes the interface really simple, and copes with other technologies amazingly well. Just my 2c. Edit: Two more important aspects: Given this view point, the rest style is not really tied to internet or web application. It's a fundamental solution to many of the programming situations. It is not simple either, it just makes the interface really simple, and copes with other technologies amazingly well. Just my 2c. Edit: Two more important aspects: Given this view point, the rest style is not really tied to internet or web application. It's a fundamental solution to many of the programming situations. It is not simple either, it just makes the interface really simple, and copes with other technologies amazingly well. Just my 2c. Edit: Two more important aspects: Just my 2c. Edit: Two more important aspects: Just my 2c. Edit: Two more important aspects: Edit: Two more important aspects: Edit: Two more important aspects:minghua ,
- Statelessness is misleading. It is about the restful API, not the application or system. The system needs to be stateful. Restful design is about designing a stateful system based on a stateless API. Some Statelessness is misleading. It is about the restful API, not the application or system. The system needs to be stateful. Restful design is about designing a stateful system based on a stateless API. Some quotes from another QA :
- REST, operates on resource representations, each one identified by an URL. These are typically not data objects, but complex objects abstractions .
- REST stands for "representational state transfer", which means it's all about communicating and modifying the state of some resource in a system.
- Idempotence : Idempotence : An often-overlooked part of REST is the idempotency of most verbs. That leads to robust systems and less interdependency of exact interpretations of the semantics .
A MVC viewpoint: The blog Rest Worst Practices suggested not to conflating models and resources . The book Two Scoops of django suggests that the Rest API is the view, and not to mix business logic into the view. The code for the app should remain in the app. – minghua Jun 25 '15 at 6:20kalin ,This is amazingly long "discussion" and yet quite confusing to say the least. IMO: 1) There is no such a thing as restful programing, without a big joint and lots of beer :) 2) Representational State Transfer (REST) is an architectural style specified in This is amazingly long "discussion" and yet quite confusing to say the least. IMO: 1) There is no such a thing as restful programing, without a big joint and lots of beer :) 2) Representational State Transfer (REST) is an architectural style specified in IMO: 1) There is no such a thing as restful programing, without a big joint and lots of beer :) 2) Representational State Transfer (REST) is an architectural style specified in IMO: 1) There is no such a thing as restful programing, without a big joint and lots of beer :) 2) Representational State Transfer (REST) is an architectural style specified in 1) There is no such a thing as restful programing, without a big joint and lots of beer :) 2) Representational State Transfer (REST) is an architectural style specified in 1) There is no such a thing as restful programing, without a big joint and lots of beer :) 2) Representational State Transfer (REST) is an architectural style specified in 2) Representational State Transfer (REST) is an architectural style specified in 2) Representational State Transfer (REST) is an architectural style specified in the dissertation of Roy Fielding . It has a number of constraints. If your Service/Client respect those then it is RESTful. This is it. You can summarize(significantly) the constraints to : You can summarize(significantly) the constraints to : You can summarize(significantly) the constraints to :> ,There is another There is another very good post which explains things nicely. A lot of answers copy/pasted valid information mixing it and adding some confusion. People talk here about levels, about RESTFul URIs(there is not such a thing!), apply HTTP methods GET,POST,PUT ... REST is not about that or not only about that. For example links - it is nice to have a beautifully looking API but at the end the client/server does not really care of the links you get/send it is the content that matters. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known. A lot of answers copy/pasted valid information mixing it and adding some confusion. People talk here about levels, about RESTFul URIs(there is not such a thing!), apply HTTP methods GET,POST,PUT ... REST is not about that or not only about that. For example links - it is nice to have a beautifully looking API but at the end the client/server does not really care of the links you get/send it is the content that matters. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known. A lot of answers copy/pasted valid information mixing it and adding some confusion. People talk here about levels, about RESTFul URIs(there is not such a thing!), apply HTTP methods GET,POST,PUT ... REST is not about that or not only about that. For example links - it is nice to have a beautifully looking API but at the end the client/server does not really care of the links you get/send it is the content that matters. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known. For example links - it is nice to have a beautifully looking API but at the end the client/server does not really care of the links you get/send it is the content that matters. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known. For example links - it is nice to have a beautifully looking API but at the end the client/server does not really care of the links you get/send it is the content that matters. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known. In the end any RESTful client should be able to consume to any RESTful service as long as the content format is known.
- stateless communication
- respect HTTP specs (if HTTP is used)
- clearly communicates the content formats transmitted
- use hypermedia as the engine of application state
add a commentChris DaMour ,Old question, newish way of answering. There's a lot of misconception out there about this concept. I always try to remember: Old question, newish way of answering. There's a lot of misconception out there about this concept. I always try to remember:> ,I define restful programming as I define restful programming as
- Structured URLs and Http Methods/Verbs are not the definition of restful programming.
- JSON is not restful programming
- RESTful programming is not for APIs
An application is restful if it provides resources (being the combination of data + state transitions controls) in a media type the client understands An application is restful if it provides resources (being the combination of data + state transitions controls) in a media type the client understandsTo be a restful programmer you must be trying to build applications that allow actors to do things. Not just exposing the database. State transition controls only make sense if the client and server agree upon a media type representation of the resource. Otherwise there's no way to know what's a control and what isn't and how to execute a control. IE if browsers didn't know To be a restful programmer you must be trying to build applications that allow actors to do things. Not just exposing the database. State transition controls only make sense if the client and server agree upon a media type representation of the resource. Otherwise there's no way to know what's a control and what isn't and how to execute a control. IE if browsers didn't know State transition controls only make sense if the client and server agree upon a media type representation of the resource. Otherwise there's no way to know what's a control and what isn't and how to execute a control. IE if browsers didn't know State transition controls only make sense if the client and server agree upon a media type representation of the resource. Otherwise there's no way to know what's a control and what isn't and how to execute a control. IE if browsers didn't know<form>tags in html then there'd be nothing for you to submit to transition state in your browser. I'm not looking to self promote, but i expand on these ideas to great depth in my talk I'm not looking to self promote, but i expand on these ideas to great depth in my talk I'm not looking to self promote, but i expand on these ideas to great depth in my talk http://techblog.bodybuilding.com/2016/01/video-what-is-restful-200.html . An excerpt from my talk is about the often referred to richardson maturity model, i don't believe in the levels, you either are RESTful (level 3) or you are not, but what i like to call out about it is what each level does for you on your way to RESTful An excerpt from my talk is about the often referred to richardson maturity model, i don't believe in the levels, you either are RESTful (level 3) or you are not, but what i like to call out about it is what each level does for you on your way to RESTful An excerpt from my talk is about the often referred to richardson maturity model, i don't believe in the levels, you either are RESTful (level 3) or you are not, but what i like to call out about it is what each level does for you on your way to RESTfuladd a commentJaider , 2017-10-02 21:23:50REST defines 6 architectural constraints which make any web service – a true RESTful API . REST defines 6 architectural constraints which make any web service – a true RESTful API .Roman Vottner ,https://restfulapi.net/rest-architectural-constraints/
- Uniform interface
- Client–server
- Stateless
- Cacheable
- Layered system
- Code on demand (optional)
Fielding added some further rules RESTful APIs/clients have to adhere – Roman Vottner Oct 2 '17 at 22:09Imran Ahmad ,djvg ,REST is an architectural style which is based on web-standards and the HTTP protocol (introduced in 2000). REST is an architectural style which is based on web-standards and the HTTP protocol (introduced in 2000).In a REST based architecture, everything is a resource(Users, Orders, Comments). A resource is accessed via a common interface based on the HTTP standard methods(GET, PUT, PATCH, DELETE etc). In a REST based architecture, everything is a resource(Users, Orders, Comments). A resource is accessed via a common interface based on the HTTP standard methods(GET, PUT, PATCH, DELETE etc).In a REST based architecture you have a REST server which provides access to the resources. A REST client can access and modify the REST resources. In a REST based architecture you have a REST server which provides access to the resources. A REST client can access and modify the REST resources.Every resource should support the HTTP common operations. Resources are identified by global IDs (which are typically URIs). REST allows that resources have different representations, e.g., text, XML, JSON etc. The REST client can ask for a specific representation via the HTTP protocol (content negotiation). HTTP methods: The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. Every resource should support the HTTP common operations. Resources are identified by global IDs (which are typically URIs). REST allows that resources have different representations, e.g., text, XML, JSON etc. The REST client can ask for a specific representation via the HTTP protocol (content negotiation). HTTP methods: The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. REST allows that resources have different representations, e.g., text, XML, JSON etc. The REST client can ask for a specific representation via the HTTP protocol (content negotiation). HTTP methods: The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. REST allows that resources have different representations, e.g., text, XML, JSON etc. The REST client can ask for a specific representation via the HTTP protocol (content negotiation). HTTP methods: The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. HTTP methods: The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. HTTP methods: The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations. The PUT, GET, POST and DELETE methods are typical used in REST based architectures. The following table gives an explanation of these operations.
- GET defines a reading access of the resource without side-effects. The resource is never changed via a GET request, e.g., the request has no side effects (idempotent).
- PUT creates a new resource. It must also be idempotent.
- DELETE removes the resources. The operations are idempotent. They can get repeated without leading to different results.
- POST updates an existing resource or creates a new resource.
Several quotes, but not a single source mentioned. Where did you get this? – djvg Dec 13 '18 at 19:02lokesh , 2016-06-03 11:35:49REST === HTTP analogy is not correct until you do not stress to the fact that it "MUST" be REST === HTTP analogy is not correct until you do not stress to the fact that it "MUST" be HATEOAS driven. Roy himself cleared it Roy himself cleared it Roy himself cleared it here . A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). From that point on, all application state transitions must be driven by client selection of server-provided choices that are present in the received representations or implied by the user's manipulation of those representations. The transitions may be determined (or limited by) the client's knowledge of media types and resource communication mechanisms, both of which may be improved on-the-fly (e.g., code-on-demand). [Failure here implies that out-of-band information is driving interaction instead of hypertext.] A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). From that point on, all application state transitions must be driven by client selection of server-provided choices that are present in the received representations or implied by the user's manipulation of those representations. The transitions may be determined (or limited by) the client's knowledge of media types and resource communication mechanisms, both of which may be improved on-the-fly (e.g., code-on-demand). [Failure here implies that out-of-band information is driving interaction instead of hypertext.] A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). From that point on, all application state transitions must be driven by client selection of server-provided choices that are present in the received representations or implied by the user's manipulation of those representations. The transitions may be determined (or limited by) the client's knowledge of media types and resource communication mechanisms, both of which may be improved on-the-fly (e.g., code-on-demand). [Failure here implies that out-of-band information is driving interaction instead of hypertext.] [Failure here implies that out-of-band information is driving interaction instead of hypertext.] [Failure here implies that out-of-band information is driving interaction instead of hypertext.]inf3rno ,doesn't answer the question as wel as the others, but +1 for information that is relevant! – CybeX Oct 2 '17 at 19:06GowriShankar ,REST stands for Representational state transfer . It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is often used in mobile applications, social networking Web sites, mashup tools and automated business processes. The REST style emphasizes that interactions between clients and services is enhanced by having a limited number of operations (verbs). Flexibility is provided by assigning resources (nouns) their own unique universal resource indicators (URIs). REST stands for Representational state transfer . It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is often used in mobile applications, social networking Web sites, mashup tools and automated business processes. The REST style emphasizes that interactions between clients and services is enhanced by having a limited number of operations (verbs). Flexibility is provided by assigning resources (nouns) their own unique universal resource indicators (URIs). It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is often used in mobile applications, social networking Web sites, mashup tools and automated business processes. The REST style emphasizes that interactions between clients and services is enhanced by having a limited number of operations (verbs). Flexibility is provided by assigning resources (nouns) their own unique universal resource indicators (URIs). It relies on a stateless, client-server, cacheable communications protocol -- and in virtually all cases, the HTTP protocol is used. REST is often used in mobile applications, social networking Web sites, mashup tools and automated business processes. The REST style emphasizes that interactions between clients and services is enhanced by having a limited number of operations (verbs). Flexibility is provided by assigning resources (nouns) their own unique universal resource indicators (URIs). REST is often used in mobile applications, social networking Web sites, mashup tools and automated business processes. The REST style emphasizes that interactions between clients and services is enhanced by having a limited number of operations (verbs). Flexibility is provided by assigning resources (nouns) their own unique universal resource indicators (URIs). REST is often used in mobile applications, social networking Web sites, mashup tools and automated business processes. The REST style emphasizes that interactions between clients and services is enhanced by having a limited number of operations (verbs). Flexibility is provided by assigning resources (nouns) their own unique universal resource indicators (URIs). Introduction about Rest> ,add a commentqmckinsey ,Talking is more than simply exchanging information . A Protocol is actually designed so that no talking has to occur. Each party knows what their particular job is because it is specified in the protocol. Protocols allow for pure information exchange at the expense of having any changes in the possible actions. Talking, on the other hand, allows for one party to ask what further actions can be taken from the other party. They can even ask the same question twice and get two different answers, since the State of the other party may have changed in the interim. Talking is RESTful architecture . Fielding's thesis specifies the architecture that one would have to follow if one wanted to allow machines to talk to one another rather than simply communicate .> ,add a commentACV , 2016-08-24 17:57:29There is not such notion as "RESTful programming" per se. It would be better called RESTful paradigm or even better RESTful architecture. It is not a programming language. It is a paradigm. There is not such notion as "RESTful programming" per se. It would be better called RESTful paradigm or even better RESTful architecture. It is not a programming language. It is a paradigm. From Wikipedia :> ,In computing, representational state transfer (REST) is an architectural style used for web development. In computing, representational state transfer (REST) is an architectural style used for web development.add a commentBenoit Essiambre , 2012-02-01 23:52:15The point of rest is that if we agree to use a common language for basic operations (the http verbs), the infrastructure can be configured to understand them and optimize them properly, for example, by making use of caching headers to implement caching at all levels. With a properly implemented restful GET operation, it shouldn't matter if the information comes from your server's DB, your server's memcache, a CDN, a proxy's cache, your browser's cache or your browser's local storage. The fasted, most readily available up to date source can be used. Saying that Rest is just a syntactic change from using GET requests with an action parameter to using the available http verbs makes it look like it has no benefits and is purely cosmetic. The point is to use a language that can be understood and optimized by every part of the chain. If your GET operation has an action with side effects, you have to skip all HTTP caching or you'll end up with inconsistent results. The point of rest is that if we agree to use a common language for basic operations (the http verbs), the infrastructure can be configured to understand them and optimize them properly, for example, by making use of caching headers to implement caching at all levels. With a properly implemented restful GET operation, it shouldn't matter if the information comes from your server's DB, your server's memcache, a CDN, a proxy's cache, your browser's cache or your browser's local storage. The fasted, most readily available up to date source can be used. Saying that Rest is just a syntactic change from using GET requests with an action parameter to using the available http verbs makes it look like it has no benefits and is purely cosmetic. The point is to use a language that can be understood and optimized by every part of the chain. If your GET operation has an action with side effects, you have to skip all HTTP caching or you'll end up with inconsistent results. With a properly implemented restful GET operation, it shouldn't matter if the information comes from your server's DB, your server's memcache, a CDN, a proxy's cache, your browser's cache or your browser's local storage. The fasted, most readily available up to date source can be used. Saying that Rest is just a syntactic change from using GET requests with an action parameter to using the available http verbs makes it look like it has no benefits and is purely cosmetic. The point is to use a language that can be understood and optimized by every part of the chain. If your GET operation has an action with side effects, you have to skip all HTTP caching or you'll end up with inconsistent results. With a properly implemented restful GET operation, it shouldn't matter if the information comes from your server's DB, your server's memcache, a CDN, a proxy's cache, your browser's cache or your browser's local storage. The fasted, most readily available up to date source can be used. Saying that Rest is just a syntactic change from using GET requests with an action parameter to using the available http verbs makes it look like it has no benefits and is purely cosmetic. The point is to use a language that can be understood and optimized by every part of the chain. If your GET operation has an action with side effects, you have to skip all HTTP caching or you'll end up with inconsistent results. Saying that Rest is just a syntactic change from using GET requests with an action parameter to using the available http verbs makes it look like it has no benefits and is purely cosmetic. The point is to use a language that can be understood and optimized by every part of the chain. If your GET operation has an action with side effects, you have to skip all HTTP caching or you'll end up with inconsistent results. Saying that Rest is just a syntactic change from using GET requests with an action parameter to using the available http verbs makes it look like it has no benefits and is purely cosmetic. The point is to use a language that can be understood and optimized by every part of the chain. If your GET operation has an action with side effects, you have to skip all HTTP caching or you'll end up with inconsistent results.osa ,"Saying that Rest is just a syntactic change... makes it look like it has no benefits and is purely cosmetic" --- that's exactly why I am reading answers here on SO. Note that you did not explain, why REST is not purely cosmetic. – osa Oct 8 '13 at 17:14kkashyap1707 , 2016-08-01 06:42:41What is What is API Testing ? API testing utilizes programming to send calls to the API and get the yield. It testing regards the segment under test as a black box. The objective of API testing is to confirm right execution and blunder treatment of the part preceding its coordination into an application. REST API REST: Representational State Transfer. API testing utilizes programming to send calls to the API and get the yield. It testing regards the segment under test as a black box. The objective of API testing is to confirm right execution and blunder treatment of the part preceding its coordination into an application. REST API REST: Representational State Transfer. API testing utilizes programming to send calls to the API and get the yield. It testing regards the segment under test as a black box. The objective of API testing is to confirm right execution and blunder treatment of the part preceding its coordination into an application. REST API REST: Representational State Transfer. REST API REST: Representational State Transfer. REST API REST: Representational State Transfer. REST: Representational State Transfer. REST: Representational State Transfer.therealprashant ,4 Commonly Used API Methods:- 4 Commonly Used API Methods:-
- It's an arrangement of functions on which the testers performs requests and receive responses. In REST API interactions are made via HTTP protocol.
- REST also permits communication between computers with each other over a network.
- For sending and receiving messages, it involves using HTTP methods, and it does not require a strict message definition, unlike Web services.
- REST messages often accepts the form either in form of XML, or JavaScript Object Notation (JSON).
Steps to Test API Manually:- To use API manually, we can use browser based REST API plugins. Steps to Test API Manually:- To use API manually, we can use browser based REST API plugins. To use API manually, we can use browser based REST API plugins. To use API manually, we can use browser based REST API plugins.
- GET: – It provides read only access to a resource.
- POST: – It is used to create or update a new resource.
- PUT: – It is used to update or replace an existing resource or create a new resource.
- DELETE: – It is used to remove a resource.
Steps to Automate REST API
- Install POSTMAN(Chrome) / REST(Firefox) plugin
- Enter the API URL
- Select the REST method
- Select content-Header
- Enter Request JSON (POST)
- Click on send
- It will return output response
this is not even a proper answer – therealprashant Aug 5 '16 at 7:17Krishna Ganeriwal , 2017-08-29 11:55:15This is very less mentioned everywhere but the Richardson's Maturity Model is one of the best methods to actually judge how Restful is one's API. More about it here: This is very less mentioned everywhere but the Richardson's Maturity Model is one of the best methods to actually judge how Restful is one's API. More about it here: Richardson's Maturity ModelRoman Vottner ,If you look at the constraints Fielding put on REST you will clearly see that an API needs to have reached Layer 3 of the RMM in order to be viewed as RESTful, though this is simply not enough actually as there are still enough possibilities to fail the REST idea - the decoupling of clients from server APIs. Sure, Layer 3 fulfills the HATEOAS constraint but it is still easy to break the requirements and to couple clients tightly to a server (i.e. by using typed resources) – Roman Vottner Oct 2 '17 at 22:21Lord , 2020-05-21 11:09:17This answer is for absolute beginners, let's know about most used API architecture today. To understand Restful programming or Restful API. First, you have to understand what API is, on a very high-level API stands for Application Programming Interface, it's basically a piece of software that can be used by another piece of software in order to allow applications to talk to each other. The most widely used type of API in the globe is web APIs while an app that sends data to a client whenever a request comes in. This answer is for absolute beginners, let's know about most used API architecture today. To understand Restful programming or Restful API. First, you have to understand what API is, on a very high-level API stands for Application Programming Interface, it's basically a piece of software that can be used by another piece of software in order to allow applications to talk to each other. The most widely used type of API in the globe is web APIs while an app that sends data to a client whenever a request comes in. To understand Restful programming or Restful API. First, you have to understand what API is, on a very high-level API stands for Application Programming Interface, it's basically a piece of software that can be used by another piece of software in order to allow applications to talk to each other. The most widely used type of API in the globe is web APIs while an app that sends data to a client whenever a request comes in. To understand Restful programming or Restful API. First, you have to understand what API is, on a very high-level API stands for Application Programming Interface, it's basically a piece of software that can be used by another piece of software in order to allow applications to talk to each other. The most widely used type of API in the globe is web APIs while an app that sends data to a client whenever a request comes in. The most widely used type of API in the globe is web APIs while an app that sends data to a client whenever a request comes in. The most widely used type of API in the globe is web APIs while an app that sends data to a client whenever a request comes in. In fact, APIs aren't only used to send data and aren't always related to web development or javascript or python or any programming language or framework. The application in API can actually mean many different things as long as the pice of software is relatively stand-alone. Take for example, the File System or the HTTP Modules we can say that they are small pieces of software and we can use them, we can interact with them by using their API. For example when we use the read file function for a file system module of any programming language, we are actually using the file_system_reading API. Or when we do DOM manipulation in the browser, we're are not really using the JavaScript language itself, but rather, the DOM API that browser exposes to us, so it gives us access to it. Or even another example let's say we create a class in any programming language like Java and then add some public methods or properties to it, these methods will then be the API of each object created from that class because we are giving other pieces of software the possibility of interacting with our initial piece of software, the objects in this case. S0, API has actually a broader meaning than just building web APIs. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. In fact, APIs aren't only used to send data and aren't always related to web development or javascript or python or any programming language or framework. The application in API can actually mean many different things as long as the pice of software is relatively stand-alone. Take for example, the File System or the HTTP Modules we can say that they are small pieces of software and we can use them, we can interact with them by using their API. For example when we use the read file function for a file system module of any programming language, we are actually using the file_system_reading API. Or when we do DOM manipulation in the browser, we're are not really using the JavaScript language itself, but rather, the DOM API that browser exposes to us, so it gives us access to it. Or even another example let's say we create a class in any programming language like Java and then add some public methods or properties to it, these methods will then be the API of each object created from that class because we are giving other pieces of software the possibility of interacting with our initial piece of software, the objects in this case. S0, API has actually a broader meaning than just building web APIs. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. In fact, APIs aren't only used to send data and aren't always related to web development or javascript or python or any programming language or framework. The application in API can actually mean many different things as long as the pice of software is relatively stand-alone. Take for example, the File System or the HTTP Modules we can say that they are small pieces of software and we can use them, we can interact with them by using their API. For example when we use the read file function for a file system module of any programming language, we are actually using the file_system_reading API. Or when we do DOM manipulation in the browser, we're are not really using the JavaScript language itself, but rather, the DOM API that browser exposes to us, so it gives us access to it. Or even another example let's say we create a class in any programming language like Java and then add some public methods or properties to it, these methods will then be the API of each object created from that class because we are giving other pieces of software the possibility of interacting with our initial piece of software, the objects in this case. S0, API has actually a broader meaning than just building web APIs. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. The application in API can actually mean many different things as long as the pice of software is relatively stand-alone. Take for example, the File System or the HTTP Modules we can say that they are small pieces of software and we can use them, we can interact with them by using their API. For example when we use the read file function for a file system module of any programming language, we are actually using the file_system_reading API. Or when we do DOM manipulation in the browser, we're are not really using the JavaScript language itself, but rather, the DOM API that browser exposes to us, so it gives us access to it. Or even another example let's say we create a class in any programming language like Java and then add some public methods or properties to it, these methods will then be the API of each object created from that class because we are giving other pieces of software the possibility of interacting with our initial piece of software, the objects in this case. S0, API has actually a broader meaning than just building web APIs. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. The application in API can actually mean many different things as long as the pice of software is relatively stand-alone. Take for example, the File System or the HTTP Modules we can say that they are small pieces of software and we can use them, we can interact with them by using their API. For example when we use the read file function for a file system module of any programming language, we are actually using the file_system_reading API. Or when we do DOM manipulation in the browser, we're are not really using the JavaScript language itself, but rather, the DOM API that browser exposes to us, so it gives us access to it. Or even another example let's say we create a class in any programming language like Java and then add some public methods or properties to it, these methods will then be the API of each object created from that class because we are giving other pieces of software the possibility of interacting with our initial piece of software, the objects in this case. S0, API has actually a broader meaning than just building web APIs. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. Now let's take a look at the REST Architecture to build APIs. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. REST which stands for Representational State Transfer is basically a way of building web APIs in a logical way, making them easy to consume for ourselves or for others. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. To build Restful APIs following the REST Architecture, we just need to follow a couple of principles. 1. We need to separate our API into logical resources. 2. These resources should then be exposed by using resource-based URLs. 3. To perform different actions on data like reading, creating, or deleting data the API should use the right HTTP methods and not the URL. 4. Now the data that we actually send back to the client or that we received from the client should usually use the JSON data format, were some formatting standard applied to it. 5. Finally, another important principle of EST APIs is that they must be stateless. Separate APIs into logical resources: The key abstraction of information in REST is a resource, and therefore all the data that we wanna share in the API should be divided into logical resources. What actually is a resource? Well, in the context of REST it is an object or a representation of something which has some data associated to it. For example, applications like tour-guide tours, or users, places, or revies are of the example of logical resources. So basically any information that can be named can be a resource. Just has to name, though, not a verb. Separate APIs into logical resources: The key abstraction of information in REST is a resource, and therefore all the data that we wanna share in the API should be divided into logical resources. What actually is a resource? Well, in the context of REST it is an object or a representation of something which has some data associated to it. For example, applications like tour-guide tours, or users, places, or revies are of the example of logical resources. So basically any information that can be named can be a resource. Just has to name, though, not a verb. Separate APIs into logical resources: The key abstraction of information in REST is a resource, and therefore all the data that we wanna share in the API should be divided into logical resources. What actually is a resource? Well, in the context of REST it is an object or a representation of something which has some data associated to it. For example, applications like tour-guide tours, or users, places, or revies are of the example of logical resources. So basically any information that can be named can be a resource. Just has to name, though, not a verb. Expose Structure: Now we need to expose, which means to make available, the data using some structured URLs, that the client can send a request to. For example something like this entire address is called the URL. and this / addNewTour is called and API Endpoint. Expose Structure: Now we need to expose, which means to make available, the data using some structured URLs, that the client can send a request to. For example something like this entire address is called the URL. and this / addNewTour is called and API Endpoint. Expose Structure: Now we need to expose, which means to make available, the data using some structured URLs, that the client can send a request to. For example something like this entire address is called the URL. and this / addNewTour is called and API Endpoint. Our API will have many different endpoints just like bellow Our API will have many different endpoints just like bellow Our API will have many different endpoints just like bellowhttps://www.tourguide.com/addNewTour https://www.tourguide.com/getTour https://www.tourguide.com/updateTour https://www.tourguide.com/deleteTour https://www.tourguide.com/getRoursByUser https://www.tourguide.com/deleteToursByUserEach of these API will send different data back to the client on also perform different actions. Now there is something very wrong with these endpoints here because they really don't follow the third rule which says that we should only use the HTTP methods in order to perform actions on data. So endpoints should only contain our resources and not the actions that we are performed on them because they will quickly become a nightmare to maintain. How should we use these HTTP methods in practice? Well let's see how these endpoints should actually look like starting with /getTour. So this getTour endpoint is to get data about a tour and so we should simply name the endpoint /tours and send the data whenever a get request is made to this endpoint. So in other words, when a client uses a GET HTTP method to access the endpoint, Each of these API will send different data back to the client on also perform different actions. Now there is something very wrong with these endpoints here because they really don't follow the third rule which says that we should only use the HTTP methods in order to perform actions on data. So endpoints should only contain our resources and not the actions that we are performed on them because they will quickly become a nightmare to maintain. How should we use these HTTP methods in practice? Well let's see how these endpoints should actually look like starting with /getTour. So this getTour endpoint is to get data about a tour and so we should simply name the endpoint /tours and send the data whenever a get request is made to this endpoint. So in other words, when a client uses a GET HTTP method to access the endpoint, How should we use these HTTP methods in practice? Well let's see how these endpoints should actually look like starting with /getTour. So this getTour endpoint is to get data about a tour and so we should simply name the endpoint /tours and send the data whenever a get request is made to this endpoint. So in other words, when a client uses a GET HTTP method to access the endpoint, How should we use these HTTP methods in practice? Well let's see how these endpoints should actually look like starting with /getTour. So this getTour endpoint is to get data about a tour and so we should simply name the endpoint /tours and send the data whenever a get request is made to this endpoint. So in other words, when a client uses a GET HTTP method to access the endpoint, (we only have resources in the endpoint or in the URL and no verbs because the verb is now in the HTTP method, right? The common practice to always use the resource name in the plural which is why I wrote /tours nor /tour.) The convention is that when calling endpoint /tours will get back all the tours that are in a database, but if we only want the tour with one ID, let's say seven, we add that seven after another slash(/tours/7) or in a search query (/tours?id=7), And of course, it could also be the name of a tour instead of the ID. HTTP Methods: What's really important here is how the endpoint name is the exact same name for all. (we only have resources in the endpoint or in the URL and no verbs because the verb is now in the HTTP method, right? The common practice to always use the resource name in the plural which is why I wrote /tours nor /tour.) The convention is that when calling endpoint /tours will get back all the tours that are in a database, but if we only want the tour with one ID, let's say seven, we add that seven after another slash(/tours/7) or in a search query (/tours?id=7), And of course, it could also be the name of a tour instead of the ID. HTTP Methods: What's really important here is how the endpoint name is the exact same name for all. (we only have resources in the endpoint or in the URL and no verbs because the verb is now in the HTTP method, right? The common practice to always use the resource name in the plural which is why I wrote /tours nor /tour.) The convention is that when calling endpoint /tours will get back all the tours that are in a database, but if we only want the tour with one ID, let's say seven, we add that seven after another slash(/tours/7) or in a search query (/tours?id=7), And of course, it could also be the name of a tour instead of the ID. HTTP Methods: What's really important here is how the endpoint name is the exact same name for all. HTTP Methods: What's really important here is how the endpoint name is the exact same name for all. HTTP Methods: What's really important here is how the endpoint name is the exact same name for all.GET: (for requesting data from the server.) https://www.tourguide.com/tours/7 POST: (for sending data to the server.) https://www.tourguide.com/tours PUT/PATCH: (for updating requests for data to the server.) https://www.tourguide.com/tours/7 DELETE: (for deleting request for data to the server.) https://www.tourguide.com/tours/7The difference between PUT and PATCH-> By using PUT, the client is supposed to send the entire updated object, while with PATCH it is supposed to send only the part of the object that has been changed. By using HTTP methods users can perform basic four CRUD operations, CRUD stands for Create, Read, Update, and Delete. Now there could be a situation like a bellow: The difference between PUT and PATCH-> By using PUT, the client is supposed to send the entire updated object, while with PATCH it is supposed to send only the part of the object that has been changed. By using HTTP methods users can perform basic four CRUD operations, CRUD stands for Create, Read, Update, and Delete. Now there could be a situation like a bellow: By using HTTP methods users can perform basic four CRUD operations, CRUD stands for Create, Read, Update, and Delete. Now there could be a situation like a bellow: By using HTTP methods users can perform basic four CRUD operations, CRUD stands for Create, Read, Update, and Delete. Now there could be a situation like a bellow: Now there could be a situation like a bellow: Now there could be a situation like a bellow: So, /getToursByUser can simply be translated to /users/tours, for user number 3 end point will be like /users/3/tours. if we want to delete a particular tour of a particular user then the URL should be like /users/3/tours/7, here user id:3 and tour id: 7. So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: So, /getToursByUser can simply be translated to /users/tours, for user number 3 end point will be like /users/3/tours. if we want to delete a particular tour of a particular user then the URL should be like /users/3/tours/7, here user id:3 and tour id: 7. So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: So, /getToursByUser can simply be translated to /users/tours, for user number 3 end point will be like /users/3/tours. if we want to delete a particular tour of a particular user then the URL should be like /users/3/tours/7, here user id:3 and tour id: 7. So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: if we want to delete a particular tour of a particular user then the URL should be like /users/3/tours/7, here user id:3 and tour id: 7. So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: if we want to delete a particular tour of a particular user then the URL should be like /users/3/tours/7, here user id:3 and tour id: 7. So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: So there really are tons of possibilities of combining resources like this. Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: Send data as JSON: Now about data that the client actually receives, or that the server receives from the client, usually we use the JSON Data Format. A typical JSON might look like below: Before sending JSON Data we usually do some simple response formatting, there are a couple of standards for this, but one of the very simple ones called Jsend. We simply create a new object, then add a status message to it in order to inform the client whether the request was a success, fail, or error. And then we put our original data into a new object called Data. Wrapping the data into an additional object like we did here is called Enveloping, and it's a common practice to mitigate some security issues and other problems. Restful API should always be stateless: Finally a RESTful API should always be stateless meaning that, in a stateless RESTful API all state is handled on the client side no on the server. And state simply refers to a piece of data in the application that might change over time. For example, whether a certain user is logged in or on a page with a list with several pages what the current page is? Now the fact that the state should be handled on the client means that each request must contain all the information that is necessary to process a certain request on the server. So the server should never ever have to remember the previous request in order to process the current request. Wrapping the data into an additional object like we did here is called Enveloping, and it's a common practice to mitigate some security issues and other problems. Restful API should always be stateless: Finally a RESTful API should always be stateless meaning that, in a stateless RESTful API all state is handled on the client side no on the server. And state simply refers to a piece of data in the application that might change over time. For example, whether a certain user is logged in or on a page with a list with several pages what the current page is? Now the fact that the state should be handled on the client means that each request must contain all the information that is necessary to process a certain request on the server. So the server should never ever have to remember the previous request in order to process the current request. Wrapping the data into an additional object like we did here is called Enveloping, and it's a common practice to mitigate some security issues and other problems. Restful API should always be stateless: Finally a RESTful API should always be stateless meaning that, in a stateless RESTful API all state is handled on the client side no on the server. And state simply refers to a piece of data in the application that might change over time. For example, whether a certain user is logged in or on a page with a list with several pages what the current page is? Now the fact that the state should be handled on the client means that each request must contain all the information that is necessary to process a certain request on the server. So the server should never ever have to remember the previous request in order to process the current request. Restful API should always be stateless: Finally a RESTful API should always be stateless meaning that, in a stateless RESTful API all state is handled on the client side no on the server. And state simply refers to a piece of data in the application that might change over time. For example, whether a certain user is logged in or on a page with a list with several pages what the current page is? Now the fact that the state should be handled on the client means that each request must contain all the information that is necessary to process a certain request on the server. So the server should never ever have to remember the previous request in order to process the current request. Restful API should always be stateless: Finally a RESTful API should always be stateless meaning that, in a stateless RESTful API all state is handled on the client side no on the server. And state simply refers to a piece of data in the application that might change over time. For example, whether a certain user is logged in or on a page with a list with several pages what the current page is? Now the fact that the state should be handled on the client means that each request must contain all the information that is necessary to process a certain request on the server. So the server should never ever have to remember the previous request in order to process the current request. Let's say that currently we are on page five and we want to move forward to page six. Sow we could have a simple endpoint called /tours/nextPage and submit a request to server, but the server would then have to figure out what the current page is, and based on that server will send the next page to the client. In other words, the server would have to remember the previous request. This is what exactly we want to avoid in RESTful APIs. Instead of this case, we should create a /tours/page endpoint and paste the number six to it in order to request page number six /tours/page/6 . So the server doesn't have to remember anything in, all it has to do is to send back data for page number six as we requested. Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general Let's say that currently we are on page five and we want to move forward to page six. Sow we could have a simple endpoint called /tours/nextPage and submit a request to server, but the server would then have to figure out what the current page is, and based on that server will send the next page to the client. In other words, the server would have to remember the previous request. This is what exactly we want to avoid in RESTful APIs. Instead of this case, we should create a /tours/page endpoint and paste the number six to it in order to request page number six /tours/page/6 . So the server doesn't have to remember anything in, all it has to do is to send back data for page number six as we requested. Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general Let's say that currently we are on page five and we want to move forward to page six. Sow we could have a simple endpoint called /tours/nextPage and submit a request to server, but the server would then have to figure out what the current page is, and based on that server will send the next page to the client. In other words, the server would have to remember the previous request. This is what exactly we want to avoid in RESTful APIs. Instead of this case, we should create a /tours/page endpoint and paste the number six to it in order to request page number six /tours/page/6 . So the server doesn't have to remember anything in, all it has to do is to send back data for page number six as we requested. Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general Instead of this case, we should create a /tours/page endpoint and paste the number six to it in order to request page number six /tours/page/6 . So the server doesn't have to remember anything in, all it has to do is to send back data for page number six as we requested. Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general Instead of this case, we should create a /tours/page endpoint and paste the number six to it in order to request page number six /tours/page/6 . So the server doesn't have to remember anything in, all it has to do is to send back data for page number six as we requested. Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general Statelessness and Statefulness which is the opposite are very important concepts in computer science and applications in general
Jul 14, 2020 | www.zdnet.com
Do you need really serious software-defined storage to handle petabytes of data? Then, Red Hat , with the latest edition of Red Hat Ceph Storage (RHCS) , has the technology you need.
STORAGE The 3 biggest storage advances of the 2010s Tiny 8TB SanDisk SSD: It's 'world's highest capacity' pocket-sized portable drive Samsung fingerprint-protected T7 Touch portable SSD Top ways to manage cloud complexity (ZDNet YouTube) Best Storage Devices (CNET) Flash storage: A guide for IT pros (TechRepublic)RHCS is based on the Nautilus version of the Ceph open-source storage project. It's designed to work on commercial off-the-shelf (COTS) hardware. But, with its ability to handle petabytes of data, you're most likely to use it on data-farms, data-centers, and clouds.
For example, you can use it to deploy petabyte-scale, Amazon Simplified Storage Service (S3) -compatible object storage. Red Hat claims that, in recent internal testing, RHCS 4 "delivered over a two-time performance boost for write-intensive workloads, making it even better-suited to fulfill the performance needs of today's data-intensive applications."
It's also been DevOps -optimized, so you can use RHCS 4 to move from storage-centric to service-centric operational models. To do this, it relies on improved Ansible DevOps integration .
This helps RHCS with self-managing and self-healing. This, in turn, makes automated backup, recovery, and provisioning easier and -- what's perhaps even more important -- more reliable. Red Hat states this will help enterprises looking for business continuity "always-on" service level agreements (SLA).
Red Hat Ceph Storage 4 includes four significant new features. These are:
A simplified installer experience, which enables standard installations that can be performed in less than 10 minutes. A new management dashboard for a unified, "heads up" view of operations at all times, helping teams to identify and resolve problems more quickly. A new quality of service (QoS)monitoring feature, which helps verify storage QoS for applications in a multi-tenant, hosted cloud environment. Integrated bucket notifications to support Kubernetes-native serverless architectures, which enable automated data pipelines.Its parent open-source parent project, Ceph , is a distributed object store and file system. It's designed from the get-go to provide excellent big data performance, reliability, and scalability. It supports object, block, and file storage.
Quick Guide: Lock Down the IT Department
Safeguarding your company's systems and information assets requires vigilance on many fronts, but it's difficult to stay on top of every vulnerability. That's where Quick Guide: Lock Down the IT Department can help. This valuable reference offers... eBooks provided by TechRepublic Premium
Amita Potnis, the IDC research director for Infrastructure Systems, likes this new release.
In a statement, Pontis said: "The massive growth of data and emerging workloads are challenges faced by many organizations. Red Hat Ceph Storage 4 can enable businesses to efficiently scale and support ever-growing data and workload requirements while providing simplified installation and management."
RHCS 4 is available today.
Oct 08, 2019 | www.reddit.com
4 points · 13 hours agoOnARedditDiet Windows Admin 4 points · 14 hours agoRAID 5 stripes the data over N disks with an additional stripe containing the parity, basically the XOR of all the other disks. RAID 6 use the same parity as RAID 5 but also use a different type of parity on an extra disk. So RAID 5 requires N+1 disks and RAID 6 requires N+2 disks. So in theory you can just add another disk and fill it with the different parity bit and you have a RAID 6, however it is not that simple. The parity disks on both RAID 5 and 6 rotates for each stripe. So if the parity is stored on disk 1 for the first stripe it is stored on disk 2 on the second and so forth. So if you add an additional disk all the stripes needs to be rewritten in the new schema. Some RAID controllers have this fuctionality. The tricky thing is that you need to track how far you have gone so that in the case of a power failure you can still retrieve the data. In any case it does require another disk.
Dry_Soda 6 points · 12 hours agohttp://www.ewams.net/?date=2013/05/02&view=Converting_RAID5_to_RAID6_in_mdadm
You're going to put your RAID in degraded mode so you're basically causing it to be in a one drive failed scenario and then asking it to rewrite every disk. Is that something you want to do? level 2
25cmshlong OCP DBA 12c, OCE 12c, OCP Solaris 11, RHCE, NCSE ONTAP, CCNA R&S 1 point · 9 hours agoWhat could possibly go wrong? #YOLO level 3
OnARedditDiet Windows Admin 1 point · 9 hours agoNot much. It is adding another parity disk so worst case array will be left in initial state - single parity (RAID5).
(Ofc truly worst case is that reading all the drives will overload power supply and fry whole disk subsystem. But it is better not to think about it since RAID6 will not help there either :) level 4
25cmshlong OCP DBA 12c, OCE 12c, OCP Solaris 11, RHCE, NCSE ONTAP, CCNA R&S 1 point · 8 hours agoIt's very well known that a full read/write pass that comes from rebuilding a degraded RAID can potentially crash the RAID by exposing existing hard drive issues. In this case nothing has failed but you could crash the RAID by fixing a non fault situation. level 5
· edited 5 hours agodrbluetongue Drunk while on-call 1 point · 5 hours agoEDIT: Oops, I remembered that in most implementations of RAID (ie, not ZFS & WAFL) there is no dedicated parity/dparity drives, but instead rotating parity. So there will definitely reading and rewriting on all disks of the array.
So text below is incorrect for most RAID subsystems
That's true but not a concern during adding parity disk. If some latent stripes appears they can be recovered using original parity. All writes during conversion will go to the new parity disks, original data on drives stays intact level 5
I don't know why you were downvoted - the most likely time you will get a disk failure is during a rebuild of an array. I've had one fail during rebuild that was from the same batch as the already failed disk in a RAID 6, thank god it was RAID 6...
Nowdays, at least at my old job, we made sure to ask the vendor for disks for the SAN's to be randomised
Aug 31, 2019 | books.slashdot.org
73 "Michael Kerrisk has been the maintainer of the Linux Man Pages collection (man 7) for more than five years now, and it is safe to say that he has contributed to the Linux documentation available in the online manual more than any other author before. For this reason he has been the recipient a few years back of a Linux Foundation fellowship meant to allow him to devote his full time to the furthering this endeavor. His book is entirely focused on the system interface and environment Linux (and, to some extent, any *NIX system) provides to a programmer. My most obvious choice for a comparison of the same caliber is Michael K. Johnson and Eric W. Troan's venerable Linux Application Development , the second edition of which was released in 2004 and is somewhat in need of a refresh, lamentably because it is an awesome book that belongs on any programmer's shelf. While Johnson and Troan have introduced a whole lot of programmers to the pleasure of coding to Linux's APIs, their approach is that of a nicely flowing tutorial, not necessarily complete, but unusually captivating and very suitable to academic use. Michael's book is a different kind of beast: while the older tome selects exquisite material, it is nowhere as complete as his -- everything relating to the subject that I could reasonably think of is in the book, in a very thorough and maniacally complete yet enjoyably readable way -- I did find one humorous exception, more on that later. Keep reading for the rest of Federico's review.
This book is an unusual, if not altogether unique, entry into the Linux programming library: for one, it is a work of encyclopedic breadth and depth, spanning in great detail concepts usually spread in a multitude of medium-sized books, but by this yardstick the book is actually rather concise, as it is neatly segmented in 64 nearly self-contained chapters that work very nicely as short, deep-dive technical guides. I have collected an extremely complete technical library over the years, and pretty much any book of significance that came out of the Linux and Bell Labs communities is in it -- it is about 4 shelves, and it is far from portable. It is very nice to be able to reach out and pick the definitive work on IPC, POSIX threads, or one of several socket programming guides -- not least because having read them, I know what and where to pick from them. But for those out there who have not invested so much time, money, and sweat moving so many books around, Kerrisk's work is priceless: any subject be it timers, UNIX signals, memory allocation or the most classical of topics (file I/O) gets its deserved 15-30 page treatment, and you can pick just what you need, in any order.
The Linux Programming Interface author Michael Kerrisk pages 1552 publisher No Starch Press rating 8/10 reviewer Federico Lucifredi ISBN 9781593272203 summary The definitive guide to the Linux and UNIX programming interface Weighing in at 1552 pages, this book is second only to Charles Kozierok's mighty TCP/IP Guide in length in the No Starch Press catalog. Anyone who has heard me comment about books knows I usually look askance at anything beyond the 500-page mark, regarding it as something defective in structure that fails the "I have no time to read all that" test. In the case of Kerrisk's work, however, just as in the case of Kozierok's, actually, I am happy to waive my own rule, as these heavyweights in the publisher's catalog are really encyclopedias, and despite my bigger library I will like to keep this single tome within easy reach of my desk to avoid having to fetch the other tomes for quick lookups -- yes, I still have lazy programmer blood in my veins.
There is another perspective to this: while writing, I took a break and while wandering around I found myself in Miguel's office (don't tell him ;-), and there spotted a Bell Labs book lying on his shelf that (incredibly) I have never heard of. After a quick visit to AbeBooks to take care of this embarrassing matter, I am back here writing to use this incident as a valuable example: the classic system programming books, albeit timeless in their own way, show their rust when it comes to newer and more esoteric Linux system calls (mmap and inotify are fair examples) and even entire subsystems in some cases -- and that's another place where this book shines: it is not only very complete, it is really up to date, a combination I cannot think of a credible alternative to in today's available book offerings.
One more specialized but particularly unique property of this book is that it can be quite helpful in navigating what belongs to what standard, be it POSIX, X/Open, SUS, LSB, FHS, and what not. Perhaps it is not entirely complete in this, but it is more helpful than anything else I have seen released since Donald Lewine's ancient POSIX Programmers Guide (O'Reilly). Standards conformance is a painful topic, but one you inevitably stumble into when writing code meant to compile and run not only on Linux but to cross over to the BSDs or farther yet to other *NIX variants. If you have to deal with that kind of divine punishment, this book, together with the Glibc documentation, is a helpful palliative as it will let you know what is not available on other platforms, and sometimes even what alternatives you may have, for example, on the BSDs.
If you are considering the purchase, head over to Amazon and check out the table of contents, you will be impressed. The Linux Programming Encyclopedia would have been a perfectly adequate title for it in my opinion. In closing, I mentioned that after thinking for a good while I found one thing to be missing in this book: next to the appendixes on tracing, casting the null pointer, parsing command-line options, and building a kernel configuration, a tutorial on writing man pages was sorely and direly missing! Michael, what were you thinking?
Federico Lucifredi is the maintainer of man (1) and a Product Manager for the SUSE Linux Enterprise and openSUSE distributions.
You can purchase The Linux Programming Interface from amazon.com . Slashdot welcomes readers' book reviews -- to see your own review here, read the book review guidelines , then visit the submission page .
Dec 20, 2008 | developerWorks
Linux is a very dynamic system with constantly changing computing needs. The representation of the computational needs of Linux centers around the common abstraction of the process. Processes can be short-lived (a command executed from the command line) or long-lived (a network service). For this reason, the general management of processes and their scheduling is very important.
From user-space, processes are represented by process identifiers (PIDs). From the user's perspective, a PID is a numeric value that uniquely identifies the process. A PID doesn't change during the life of a process, but PIDs can be reused after a process dies, so it's not always ideal to cache them.
In user-space, you can create processes in any of several ways. You can execute a program (which results in the creation of a new process) or, within a program, you can invoke a
forkorexecsystem call. Theforkcall results in the creation of a child process, while anexeccall replaces the current process context with the new program. I discuss each of these methods to understand how they work.For this article, I build the description of processes by first showing the kernel representation of processes and how they're managed in the kernel, then review the various means by which processes are created and scheduled on one or more processors, and finally, what happens if they die.
23 October 2009 | Daring Fireball
Conformity is a powerful instinct. There's safety in numbers. You have to be different to be better, but different is scary.
So of course there's some degree of herd mentality in every industry. But I think it's more pronounced, to a pathological degree, in the PC hardware industry. It was at the root of long-standing punditry holding that Apple should license the Mac OS to other PC makers, or that Apple should dump Mac OS and make Windows PCs. On the surface, those two old canards seem contradictory - one arguing that Apple should be a hardware company, the other arguing that it should be a software company. But at their root they're the same argument: that Apple should stop being different, and either act just like other PC makers (and sell computers running Windows) or else act just like Microsoft (and sell licenses to its OS).
No one argues those two points any more. But it's the same herd mentality that led to the rash of Apple needs to get in the "netbook" game punditry that I claim-checked earlier this week. I could have linked to a dozen others. The argument, though, is the same: everyone else is making netbooks, so Apple should, too. Why? Because everyone else is.
I think there's a simple reason why the herd mentality is worse in the PC industry: Microsoft. In fact, I think it used to be worse. A decade ago the entire computing industry - all facets of it - was dominated by a herd mentality that boiled down to Get behind Microsoft and follow their lead, or else you'll get stomped. That's no longer true in application software. The web, and Google in particular, have put an end to that.
But the one area where Microsoft still reigns supreme is in PC operating systems. PC hardware makers are crippled. They can't stand apart from the herd even if they want to. Their OS choices are: (a) the same version of Windows that every other PC maker includes; or (b) the same open source Linux distributions that every other PC maker could include but which no customers want to buy.1
Apple's ability to produce innovative hardware is inextricably intertwined with its ability to produce innovative software. The iPhone is an even better example than the Mac.
It's not just that Apple is different among computer makers. It's that Apple is the only one that even can be different, because it's the only one that has its own OS. Part of the industry-wide herd mentality is an assumption that no one else can make a computer OS - that anyone can make a computer but only Microsoft can make an OS. It should be embarrassing to companies like Dell and Sony, with deep pockets and strong brand names, that they're stuck selling computers with the same copy of Windows installed as the no-name brands.
And then there's HP, a company with one of the best names and proudest histories in the industry. Apple made news this week for the design and tech specs of its all-new iMacs, which start at $1199. HP made news this week for unveiling a Windows 7 launch bundle at Best Buy that includes a desktop PC and two laptops, all for $1199. That might be great for Microsoft, but how is it good for HP that their brand now stands for bargain basement prices?
Operating systems aren't mere components like RAM or CPUs; they're the single most important part of the computing experience. Other than Apple, there's not a single PC maker that controls the most important aspect of its computers. Imagine how much better the industry would be if there were more than one computer maker trying to move the state of the art forward.
- And, perhaps soon, the same version of Google Chrome OS that's available to every other PC maker. Chrome OS might help PC makers break free of Microsoft, but it won't help them break free from each other.
Linux Magazine OnlineModern filesystems make forensic file recovery much more difficult. Tools like Foremost and Scalpel identify data structures and carve files from a hard disk image.
IT experts and investigators have many reasons for reconstructing deleted files. Whether an intruder has deleted a log to conceal an attack or a user has destroyed a digital photo collection with an accidental rm ‑rf, you might someday face the need to recover deleted data. In the past, recovery experts could easily retrieve a lost file because an earlier generation of filesystems simply deleted the directory entry. The meta information that described the physical location of the data on the disk was preserved, and tools like The Coroner's Toolkit (TCT [1]) and The Sleuth Kit (TSK [2]) could uncover the information necessary for restoring the file. Today, many filesystems delete the full set of meta information, leaving the data blocks. Putting these pieces together correctly is called file carving – forensic experts carve the raw data off the disk and reconstruct the files from it. The more fragmented the filesystem, the harder this task become.
On UNIX® systems, each system and end-user task is contained within a process. The system creates new processes all the time and processes die when a task finishes or something unexpected happens. Here, learn how to control processes and use a number of commands to peer into your system.At a recent street fair, I was mesmerized by the one-man band. Yes, I am easily amused, but I was impressed nonetheless. Combining harmonica, banjo, cymbals, and a kick drum -- at mouth, lap, knees, and foot, respectively -- the veritable solo symphony gave a rousing performance of the Led Zeppelin classic "Stairway to Heaven" and a moving interpretation of Beethoven's Fifth Symphony. By comparison, I'm lucky if I can pat my head and rub my tummy in tandem. (Or is it pat my tummy and rub my head?)
Lucky for you, the UNIX® operating system is much more like the one-man band than your clumsy columnist. UNIX is exceptional at juggling many tasks at once, all the while orchestrating access to the system's finite resources (memory, devices, and CPUs). In lay terms, UNIX can readily walk and chew gum at the same time.
This month, let's probe a little deeper than usual to examine how UNIX manages to do so many things simultaneously. While spelunking, let's also glimpse the internals of your shell to see how job-control commands, such as Control-C (terminate) and Control-Z (suspend), are implemented. Headlamps on! To the bat cave!
Re:wishfull thinking(Score:5, Informative)by TheNetAvenger (624455) on Monday October 17, @02:08AM (#13807631)
Win32 subsystem is TOO much tied to NT kernel and closely coupled to achieve the performance it has today.
That is why NT 3.51/3.53 was more robust than NT 4,0 which moved major parts of the UI code to kernel mode.Please actually read Inside Windows NT 3.51 by Helen Custer and THEN read Inside Windows NT 4.0 to know the difference.
Sorry, hun, read both and even had this discussion with a key kernel developer at Microsoft a few years ago. (1997 in fact, as we were starting to work with Beta 1 of Windows 2000)
NT 4.0 ONLY moved video to a lower ring. It had NOTHING to do with moving the Win32 subsystem INTO NT - that did not happen.
That is why Windows NT Embedded exists, and also why even the WinCE is a version of the NT kernel with NO Win32 ties.
Microsoft can STILL produce NT without any Win32, and just throw a *nix subsystem on it if they wanted to, but yet have the robustness of NT. Win32 is the just the default interface because of the common API and success of Windows applications.
I think you are confusing Ring dropping of the video driver with something completely different.
NT is a client/server kernel... Go look up what that means, please for the love of God.
Win32 is a subsystem, plain and simple. Yes it is a subsystem that has tools to control the NT kernel under it, but that is just because that is the default subsystem interface. You could build these control tools in any subsystem you want to stack on NT. PERIOD.
Microsoft Research has released part of a report on the "Singularity" kernel they've been working on as part of their planned shift to network computing. The report includes some performance comparisons that show Singularity beating everything else on a 1.8Ghz AMD Athlon-based machine.
What's noteworthy about it is that Microsoft compared Singularity to FreeBSD and Linux as well as Windows/XP - and almost every result shows Windows losing to the two Unix variants.
For example, they show the number of CPU cycles needed to "create and start a process" as 1,032,000 for FreeBSD, 719,000 for Linux, and 5,376,000 for Windows/XP. Similarly they provide four graphs comparing raw disk I/O and show the Unix variants beating Windows/XP in three (and a half) of the four cases.
Oddly, however, it's the cases in which they report Windows/XP as beating Unix that are the most interesting. There are three examples of this: one in which they count the CPU cycles needed for a "thread yield" as 911 for FreeBSD, 906 for Linux, and 753 for Windows XP; one in which they count CPU cycles for a "2 thread wait-set ping pong" as 4,707 for FreeBSD, 4,041 for Linux, and 1,658 for Windows/XP; and, one in which they report that "for the sequential read operations, Windows XP performed significantly better than the other systems for block sizes less than 8 kilobytes."
So how did they get these results?
The sequential tests read or wrote 512MB of data from the same portion of the hard disk. The random read and write tests performed 1000 operations on the same sequences of blocks on the disk. The tests were single threaded and performed synchronous raw I/O. Each test was run seven times and the results averaged.
umm…
The Unix thread tests ran on user-space scheduled pthreads. Kernel scheduled threads performed significantly worse. The "wait-set ping pong" test measured the cost of switching between two threads in the same process through a synchronization object. The "2 message ping pong" measured the cost of sending a 1-byte message from one process to another and then back to the original process. On Unix, we used sockets, on Windows, a named pipe, and on Singularity, a channel.
So why is this interesting? Because their test methods reflect Windows internals, not Unix kernel design. There are better, faster, ways of doing these things in Unix, but these guys - among the best and brightest programmers working at Microsoft- either didn't know or didn't care.
If all the basics are the same, what has changed? Well, these things:
- Number of system calls
- Languages we use
- Subsystems we program
- Need for portability
- Relevance of UNIX standards
More System Calls
The number of system calls has quadrupled, more or less, depending on what you mean by "system call." The first edition of Advanced UNIX Programming focused on only about 70 genuine kernel system calls-for example, open, read, and write; but not library calls like fopen, fread, and fwrite. The second edition includes about 300. (There are about 1,100 standard function calls in all, but many of those are part of the Standard C Library or are obviously not kernel facilities.) Today's UNIX has threads, real-time signals, asynchronous I/O, and new interprocess-communication features (POSIX IPC), none of which existed 20 years ago. This has caused, or been caused by, the evolution of UNIX from an educational and research system to a universal operating system. It shows up in embedded systems (parking meters, digital video recorders); inside Macintoshes; on a few million web servers; and is even becoming a desktop system for the masses. All of these uses were unanticipated in 1984.
More Languages
In 1984, UNIX applications were usually programmed in C, occasionally mixed with shell scripts, Awk, and Fortran. C++ was just emerging; it was implemented as a front end to the C compiler. Today, C is no longer the principal UNIX application language, although it's still important for low-level programming and as a reference language. (All the examples in both books are written in C.) C++ is efficient enough to have replaced C when the application requirements justify the extra effort, but many projects use Java instead, and I've never met a programmer who didn't prefer it over C++. Computers are fast enough so that interpretive scripting languages have become important, too, led by Perl and Python. Then there are the web languages: HTML, JavaScript, and the various XML languages, such as XSLT.
Even if you're working in one of these modern languages, though, you still need to know what going on "down below," because UNIX still defines-and, to a degree, limits-what the higher-level languages can do. This is a challenge for many students who want to learn UNIX, but don't want to learn C. And for their teachers, who tire of debugging memory problems and explaining the distinction between declarations and definitions.
TIP
To enable students to learn UNIX without first learning C, I developed a Java-to-UNIX system-call interface that I call Jtux. It allows almost all of the UNIX system calls to be executed from Java, using the same arguments and datatypes as the official C calls. You can find out more about Jtux and download its source code from http://basepath.com/aup/.
More Subsystems
The third area of change is that UNIX is both more visible than ever (sold by Wal-Mart!) and more hidden, underneath subsystems like J2EE and web servers, Apache, Oracle, and desktops such as KDE or GNOME. Many application programmers are programming for these subsystems, rather than for UNIX directly. What's more, the subsystems themselves are usually insulated from UNIX by a thin portability layer that has different implementations for different operating systems. Thus, many UNIX system programmers these days are working on middleware, rather than on the end-user applications that are several layers higher up.
More Portability
The fourth change is the requirement for portability between UNIX systems, including Linux and the BSD-derivatives, one of which is the Macintosh OS X kernel (Darwin). Portability was of some interest in 1984, but today it's essential. No developer wants to be locked into a commercial version of UNIX without the possibility of moving to Linux or BSD, and no Linux developer wants to be locked into only one distribution. Platforms like Java help a lot, but only serious attention to the kernel APIs, along with careful testing, will ensure that the code is really portable. Indeed, you almost never hear a developer say that he or she is writing for XYZ's UNIX. It's much more common to hear "UNIX and Linux," implying that the vendor choice will be made later. (The three biggest proprietary UNIX hardware companies-Sun, HP, and IBM-are all strong supporters of Linux.)
More Complete Standards
The requirement for portability is connected with the fifth area of change, the role of standards. In 1984, a UNIX standards effort was just starting. The IEEE's POSIX group hadn't yet been formed. Its first standard, which emerged in 1988, was a tremendous effort of exceptional quality and rigor, but it was of very little use to real-world developers because it left out too many APIs, such as those for interprocess communication and networking. That minimalist approach to standards changed dramatically when The Open Group was formed from the merger of X/Open and the Open Software Foundation in 1996. Its objective was to include all the APIs that the important applications were using, and to specify them as well as time allowed-which meant less precisely than POSIX did. They even named one of their standards Spec 1170, the number being the total of 926 APIs, 70 headers, and 174 commands. Quantity over quality, maybe, but the result meant that for the first time programmers would find in the standard the APIs they really needed. Today, The Open Group's Single UNIX Specification is the best guide for UNIX programmers who need to write portably.
The following tutorial describes various common methods for reading and writing files and directories on a Unix system. Part of the information is common C knowledge, and is repeated here for completeness. Other information is Unix-specific, although DOS programmers will find some of it similar to what they saw in various DOS compilers. If you are a proficient C programmer, and know everything about the standard I/O functions, its buffering operations, and know functions such as
fseek()orfread(), you may skip the standard C library I/O functions section. If in doubt, at least skim through this section, to catch up on things you might not be familiar with, and at least look at the standard C library examples.This document is copyright (c) 1998-2002 by guy keren. The material in this document is provided AS IS, without any expressed or implied warranty, or claim of fitness for a particular purpose. Neither the author nor any contributers shell be liable for any damages incured directly or indirectly by using the material contained in this document.
permission to copy this document (electronically or on paper, for personal or organization internal use) or publish it on-line is hereby granted, provided that the document is copied as-is, this copyright notice is preserved, and a link to the original document is written in the document's body, or in the page linking to the copy of this document.
Permission to make translations of this document is also granted, under these terms - assuming the translation preserves the meaning of the text, the copyright notice is preserved as-is, and a link to the original document is written in the document's body, or in the page linking to the copy of this document.
For any questions about the document and its license, please contact the author.
Contents
This web site compares and contrasts operating systems. It originally started out on a small server in the engineering department of Ohio State University to answer a single question: "On technical considerations only, how does Rhapsody (also known as
Mac OS X Server) stack up as a server operating system (especially in comparison to Windows NT)?" The web site now compares and contrasts server operating systems and will in the near future expand to compare other kinds of operating systems.
For non-technical persons: A general overview of operating systems for non-technical people is located at: kinds of operating systems. Brief summaries of operating systems are located at: summaries of operating systems. There is an entire section of pages on individual operating systems, all formatted in the same order for easy comparison. The holistic area looks at operating systems from a holistic point of view and particular subjects in that presentation may be useful for comparison. Some of the charts and tables may also be useful for specific comparisons.
For technical persons: The system components area goes into detail about the inner workings of an operating system and the individual operating systems pages provide some technical information.
This site is organized as an unbalanced tree structure, with cyclic graph hyperlinks and a sequential traversal path through the tree.
A long time ago, my undergraduate operating-systems class required that we cross-compile a small, standalone system and upload it to a PDP-11 minicomputer. We could do some limited debugging at the console if the program didn't crash. The development environment was poor; it was painful and time-consuming to get things working, but the experience was an overall confidence builder. I feel there is a huge advantage for a student to control the operations of a computer directly.
Another approach for teaching operating systems is to provide a controlled runtime and development environment using a simulator. Several universities teach operating-system concepts using the Nachos simulator (<http://www.cs.washington.edu/homes/tom/nachos>). The advantage is that the instructor can easily control much of the environment for assignments, and the students don't waste time with crashes, kernel builds, and rebooting. These kinds of systems can be very simplistic and lack realism.
As a private pilot, I know that aviation simulation goes only so far. You need to spend some time in the sky, in the air-traffic-control system, in the weather, and with the attendant dangers, to absorb and appreciate the training fully. A two-hour actual flight lesson is often fatiguing and draining; but the same amount of time in a simulator is more like a classroom experience. Similarly, students sense the difference between working in a safe simulator environment and working on a real kernel. Lessons with the latter seem more dramatic.
Like any time-sharing system, Linux achieves the magical effect of an apparent simultaneous execution of multiple processes by switching from one process to another in a very short time frame. Process switch itself was discussed in Chapter 3, Processes; this chapter deals with scheduling, which is concerned with when to switch and which process to choose.
The chapter consists of three parts. The section "Scheduling Policy" introduces the choices made by Linux to schedule processes in the abstract. The section "The Scheduling Algorithm" discusses the data structures used to implement scheduling and the corresponding algorithm. Finally, the section "System Calls Related to Scheduling" describes the system calls that affect process scheduling.
VMware enables you to run a Virtual Machine, which is VMware's version of an emulated state of Windows, Linux, or FreeBSD. You heard me right-on VMware, not only can you do Windows, but also Linux and FreeBSD. That means if you need to test out that new version of Linux, but you don't want to format your drive just to test it out, VMware can just create a virtual drive and you're on your way to seeing what the latest version of your favorite distribution has to offer.
To date, VMware has been pretty much a development product, but thanks to demand for a stable, versatile operating environment, VMware has upped the ante and created their best version of VMware yet-2.0.2.
If you've used a package like Connectix VirtualPC for the Macintosh PowerPC, you'll notice many likenesses it shares with VMware. The website may really hype VMware up and make it sound like there is no loss of performance, but the simple fact is that you do lose clock speed, RAM and hard disk speed, just like you would with any piece of emulation software.
In fact, you can tell both VMware and VirtualPC are designed along the same lines. The configuration is much the same, except one is obviously more PC-fied, while one is more Mac-centric.
Although, what it comes down to is compatibility. VMware does a much better job at emulating x86 hardware, probably since it's operating on top of x86 hardware. That's a logical assumption, right? Enough with guesswork, let's take a look at what's really going on.
Here we see how it really works. A typical PC works like we see on the left. I think the diagram oversimplifies things in a way, but it will do the job.Essentially, VMware interfaces directly with most your system hardware, which is one way it achieves pretty good performance even on low-end machines. Don't get me wrong, you still won't get the full speed of your PC out of VMware, this happens because things like the hard disk access (where it looks to be hurting the most) are still done through the operating system.
This is how it all happens. This diagram shows you the devices which need VMware still needs to call through the OS-disk, memory and CPU.
Once again, VMware has a few tricks up its sleeve. One great thing about VMware is that you can utilize your local network to get access to your Windows or Linux filesystem. In fact, you can even use a regular network along with your local network at the same time, so you don't need to sacrifice anything with the networking setup.
sysctl the Command and the SubroutineComing from a hybrid Sys V and BSD system, the first time I began maintaining a BSD system I was immediately plunged into making system level changes and finding out very specific information about the system. There is a tool for just such a task,
sysctl. Along with that, however, I had come across an unusual program that needed access to such information as well. The program needed the information "hard coded", something I did not like. Luckily, thesysctlcalls are easily (and extraordinarily well documented) accessible via a simple system subroutine. This article will cover two aspects ofsysctl:
- Some examples using the
sysctlcommand.- Examples with sample code on using the
sysctlsubroutines.Note: Examples were drawn from all three free BSDs (I have run all three of them at one time or another): NetBSD, FreeBSD and OpenBSD.
The
sysctlCommand (Facility)It might be more correct to call
sysctla facility or utility rather than just a command. The official short definition is:
- sysctl get or set kernel state
In reality (typical to BSD design - which is a good thing)
sysctlhas been extended to a great many things and show all sorts of great information. I say this because judging by the short definition, one would thing all you can do with it is examine kernel parameters and perhaps modify others . . . well, that and:
- get specific hardware information
- get and set a wide variety of kernel level network parameters
- get and set dependancy information
- . . . and the list goes on
Really, the well documented man page of
man 8 sysctlhas all the information you need. Let us take a look at some sample usages:First, how about the OS type:
$ sysctl kern.ostype kern.ostype = NetBSDHere is a sample looking at the clockrate:
$ sysctl kern.clocktrate kern.clockrate = tick = 10000, tickadj = 40, hz = 100, profhz = 100, stathz = 100A very important (and often modified parameter on systems) ye olde ip forwarding (where 1 is on and 0 is off):
$ sysctl net.inet.ip.forwarding net.inet.ip.forwarding = 0Now some real quick hardware gathering examples that show us the following information respectfully:
- machine type
- specific model information
- number of processors
$ sysctl kern.hw.machine hw.machine = sparc $sysctl hw.model hw.model = SUNW,SPARCstation-5, MB86904 @ 110 MHz, on-chip FPU $ sysctl hw.ncpu hw.ncpu = 1Another quick note: all of the examples were done in userland.
We have seen the ease of use of the
sysctlcommand, but the subroutine offers great access at a low level to even more information.Using the
sysctlSubroutine(s)Note: The next section requires a basic understanding the C programming language.
The
sysctlfunction allows programmatic access to a wide array of information about the system itself, the kernel and network information, in this respect it is very similar in nature to it's command counterpart. It should also be quite obvious that this is in fact the function that thesysctlprimarily uses (duh). This begs the question, why is this important to know or understand? The name of the game is understanding, seeing how to directly access thesysctlfunction is one of the many steps to systems programming emlightenment. In short order, what it is you do when you might use thesysctlcommand. Additionally, using the function can help develop or extend utilities. The reasonsysctlis so wonderful at this is how it is so linked to the core operating system. Again, I must reiterate the BSD philosophy of extension versus new. It is better to extend a pre-existing piece of software rather than encourage the development of a completely new one, nevertheless, thesysctlfunction could be useful for (and is no doubt in employed in many other pieces of existing programs) building new utilities.Well let us get to it shall we? For the sake of simplicity, the code examples will follow some of the examples shown in the command section of this article. The best way to illustrate a usage is a case study, so. let us create one, for posterity, we will acknowledge the great forecoders by using the example that comes from the BSD Programmer's Manual and an additional one that does not:
We have a program that, for some odd reason, needs to know the following information:
- the number pf processes allowed on the system (the one from the manual)
- the number of cpus (perhaps 3rd party licensing software :) )
Getting the Number of Processes
One thing I believe in is paying due respect, and as such, we will peruse one of the examples in the BSD documentation, how to snag the number of processes allowed on the system:
. . . #include. . . int get_processes_max { int mib[2], maxproc; size_t len; mib[0] = CTL_KERN; mib[1] = KERN_MAXPROC; len = sizeof(maxproc); sysctl(mib, 2, &maxproc, &len, NULL, 0); return maxproc; } It is important, at this point, to understand what it is we are accessing and how it is done. To think in C terms, we are looking at this (again, noted in the man page):
int sysctl(int *name, y_int namelen, void *oldp, size_t *oldlenp, void *newp, size_t newlen);If you look carefully across the function prototype for
sysctlyou will see where all of the arguments specified satisy the function.Again, for the next value, our function really would not have to look much different:
. . . #include. . . int get_processes_max { int mib[2], num_cpu; size_t len; mib[0] = CTL_HW; mib[1] = HW_NCPU; len = sizeof(num_cpu); sysctl(mib, 2, &num_cpu, &len, NULL, 0); return num_cpu; } Basically what we are looking at is access to data structures, nothing more really. The great thing about it is the ease of access, quite simpler than endless routine writing for endless direct file level access, instead, using this function, we can get a great deal of information about the system with a minimal and safe level of exertion.
This Is Just The Beginning
Doubtless if this article was something new to you, then the door that lie before you is a great one indeed. BSD presents an unparalled opportunity to delve into the inner workings of BSD and UNIX itself. Continue on and look to programming guides and documentation to lead the way, you will not be disappointed. As for my material, I will also open the door, and we shall see in the long run what lie on the other side.
What About
sysctlfor LinuxTo the best_of_my_knowledge system parms associated with
sysctlcan be viewed and modified under/proc/sys(for the most part) on Linux systems. When programmatic access is required it is recommended to use/procas well.
"POSIX (Portable Operating System Interface) threads are a great way to increase the responsiveness and performance of your code."
The title is really just a fancy way of saying that I am going to attempt to describe the whole VM enchilada, hopefully in a way that everyone can follow. For the last year I have concentrated on a number of major kernel subsystems within FreeBSD, with the VM and Swap subsystems being the most interesting and NFS being 'a necessary chore'. I rewrote only small portions of the code. In the VM arena the only major rewrite I have done is to the swap subsystem. Most of my work was cleanup and maintenance, with only moderate code rewriting and no major algorithmic adjustments within the VM subsystem. The bulk of the VM subsystem's theoretical base remains unchanged and a lot of the credit for the modernization effort in the last few years belongs to John Dyson and David Greenman. Not being a historian like Kirk I will not attempt to tag all the various features with peoples names, since I will invariably get it wrong.
Before moving along to the actual design let's spend a little time on the necessity of maintaining and modernizing any long-living codebase. In the programming world, algorithms tend to be more important than code and it is precisely due to BSD's academic roots that a great deal of attention was paid to algorithm design from the beginning. More attention paid to the design generally leads to a clean and flexible codebase that can be fairly easily modified, extended, or replaced over time. While BSD is considered an 'old' operating system by some people, those of us who work on it tend to view it more as a 'mature' codebase which has various components modified, extended, or replaced with modern code. It has evolved, and FreeBSD is at the bleeding edge no matter how old some of the code might be. This is an important distinction to make and one that is unfortunately lost to many people. The biggest error a programmer can make is to not learn from history, and this is precisely the error that many other modern operating systems have made. NT is the best example of this, and the consequences have been dire. Linux also makes this mistake to some degree -- enough that we BSD folk can make small jokes about it every once in a while, anyway (grin). Linux's problem is simply one of a lack of experience and history to compare ideas against, a problem that is easily and rapidly being addressed by the Linux community in the same way it has been addressed in the BSD community -- by continuous code development. The NT folk, on the other hand, repeatedly make the same mistakes solved by UNIX decades ago and then spend years fixing them. Over and over again. They have a severe case of 'not designed here' and 'we are always right because our marketing department says so'. I have little tolerance for anyone who cannot learn from history.
Much of the apparent complexity of the FreeBSD design, especially in the VM/Swap subsystem, is a direct result of having to solve serious performance issues that occur under various conditions. These issues are not due to bad algorithmic design but instead rise from environmental factors. In any direct comparison between platforms, these issues become most apparent when system resources begin to get stressed. As I describe FreeBSD's VM/Swap subsystem the reader should always keep two points in mind. First, the most important aspect of performance design is what is known as "Optimizing the Critical Path". It is often the case that performance optimizations add a little bloat to the code in order to make the critical path perform better. Second, a solid, generalized design outperforms a heavily-optimized design over the long run. While a generalized design may end up being slower than an heavily-optimized design when they are first implemented, the generalized design tends to be easier to adapt to changing conditions and the heavily-optimized design winds up having to be thrown away. Any codebase that will survive and be maintainable for years must therefore be designed properly from the beginning even if it costs some performance. Twenty years ago people were still arguing that programming in assembly was better than programming in a high-level language because it produced code that was ten times as fast. Today, the fallibility of that argument is obvious -- as are the parallels to algorithmic design and code generalization.
In This Article • Process Scheduling In Linux
• Tangled In The Threads
• Two Paths
• Kernel Pre-emption And User Pre-emption
Last month, we started a new series of Linux kernel internals. In that first part, we looked at how Linux manages processes and why in many ways Linux is better at creating and maintaining processes than many commercials Unixes.
This series on Linux internals is by the way the fruit of a tight collaboration with some of the most experienced kernel hackers in the Linux project. Without the contribution of people like Andrea Arcangeli in Italy (VM contributor and SuSE employee), Ingo Molnar (scheduler contributor) and many others, this series wouldn't be possible. Many thanks to all of them, but especially to Andrea Arcangeli who has shown a lot of patience in answering many of my questions.
Rawn Shah checks out VMware's latest system emulator, version 1.1. It promises to let you run a Linux host OS, then switch -- without rebooting -- among up to four other guest OSs that operate inside virtual hardware created by VMware. (2,100 words)
[July 25, 1999] Welcome to VMware Inc. - Virtual Platform Technology VMware software initially comes in two flavors, depending on the user's host operating system: VMware for Linux, and VMware for Windows NT. VMware for Linux (time-limited demo) -- run DOS-, FreeBSD-, Windows 3.x, 9x and NT 4.0-applications easily under Linux. VMware is included in SuSE distribution: http://linuxpr.com/releases/176.html
Experience of on of the users who has Celeron 450 MHz, 256MB RAM and had given virtual machine 64M was quite positive. He used NT driver SVGA from vmware, and after than it started to work with the screen noticeably faster and supported modes more than 800x600. (vmware recommend X 3.3.3.2). in this configuration Visio is working satisfactory (redrawing of screen is a little bit slow in non-full screen mode), but generally is OK. The fact that it's now possible to work on a single computer instead of two overweight the small inconveniences described.
[May 27, 1999] Linux Memory Management subsystem; main page
[March 2,1999] Linux Kernel Mailing List, Archive by Week by thread
[Feb.12,1999] www8.pair.com -- the ultimate OS
Uniform Driver Interface (UDI)
Kernel Traffic (http://www.kt.opensrc.org/) -- information of new kernel developments
Google matched content |
General info:
| Tutorials | ||||||||
Many useful papers are collected in the Operating Systems Articles
A useful site is Server Operating Systems Technical Comparison
Sigma Design & Development AB Realtime systems -- a lot of links on the subject.
Operating systems - Links (from Finland)
| Introduction | History | Architecture | |||||
| Linux Modules |
See also University Courses
Linux Documentation Project Guides(see also Linux Guides):
The Linux Kernel Hackers' Guide, freely redistributable collection of documents; version 0.7 by Michael K. Johnson is available in HTML and HTML (tared and gziped).
The Linux Kernel, freely redistributable book by David A. Rusling. Version 0.8-2is available in HTML, HTML (tared and gziped), DVI, LaTeX source, PDF, and PostScript.
The Linux Programmer's Guide, version 0.4 by B. Scott Burkett, Sven Goldt, John D. Harper, Sven van der Meer and Matt Welsh, is available in HTML, HTML (tared and gziped), LaTeX source, PDF and PostScript.
Operating Systems -- introduction to OS by Sharon Heimansohn, [email protected]. see also other modules from Department of Computer and Information Science of IUPU (Indiana University / Purdue University Indianapolis):
The Mythical Man-Month. Essays on Software Engineering by Frederick Brooks Jr. Anniversary Edition. Contain a fascinating account on the creation of OS/360 -- real classic.
Ch.6 Linux Interprocess Communications from Linux Programmer Guide
Other synchronization primitives
Ada Tasking
Java
Atomic Transactions
Bankers algorithm
Dining Philosophers
Lecture Notes
Distributed case and databases
Etc.
Deadlock... The Deadly Embrace (Millersville University) Dr. Roger W. Webster (contains the picture from SG)
Paging vs. Segmentation, Multilevel Page Tables, Paging Along with Segmentation
Capability Addressing, Protection Capabilities, Single Virtual Address Space, & Protection Rings
Distributed Shared Memory, & The Mach VM
Memory Consistency, & Consistency Models Requiring & Not Requiring Synchronization Operations
NUMA vs NORMA, Replication Of Memory, Achieving Sequential Consistency, & Synchronization in DSM Systems
Management of Available Storage, Swapping and Paging, & Inverted Page Tables
Performance of Demand Paging, Replacement Strategies, Stack Algorithms and Priority Lists, Approximations to LRU Replacement, Page vs. Segment Replacement, & Page Replacement in DSM Systems
Locality of Reference, User-Level Memory Managers,The Working Set Model, Load Control in UNIX, & Performance of Paging Algorithms
SunWorld Online - January - CacheFS and Solstice AutoClient
IMPLEMENTING LOADABLE KERNEL MODULES FOR LINUX -- Matt Welsh
See also Linux for a limited hardware (installations of FAT disk drives):
Advanced systems programming and realtime systems Realtime operating systems and device programming
Windows NT Architecture, Part 1
Inside the Windows 2000 Kernel
Windows NT File System Internals A Developer's Guide Chapter 4. The NT I-O Manager
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: November 22, 2020