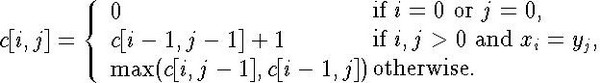|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| Softpanorama: Algorithms and Data Structures | Recommended Books | Recommended Links | Pattern Matching | Searching Algorithms | Regular expressions | Humor | Etc |
|
|
The longest common substring problem is to find the longest string (or strings) that is a substring (or are substrings) of two or more strings. It should not be confused with the longest common subsequence problem. (For an explanation of the difference between a substring and a subsequence, see Substring vs. subsequence).
|
|
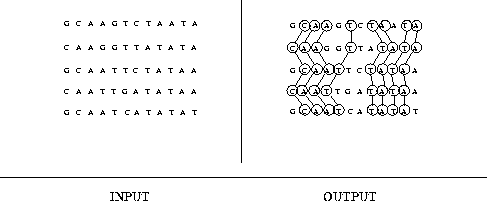
For example, The longest common substrings of the strings "ABAB", "BABA" and "ABBA" are the strings "AB" and "BA" of length 2. Other common substrings are "A", "B" and the empty string "".
ABAB ||| BABA || ABBA
A good lecture notes by Professor David Eppstein (Longest Common Subsequences, dated 09 Feb 2002,) is available on the Web:
In this lecture we examine another string matching problem, of finding the longest common subsequence of two strings.This is a good example of the technique of dynamic programming, which is the following very simple idea: start with a recursive algorithm for the problem, which may be inefficient because it calls itself repeatedly on a small number of subproblems. Simply remember the solution to each subproblem the first time you compute it, then after that look it up instead of recomputing it. The overall time bound then becomes (typically) proportional to the number of distinct subproblems rather than the larger number of recursive calls. We already saw this idea briefly in the first lecture.
As we'll see, there are two ways of doing dynamic programming, top down and bottom-up. The top down (memoizing) method is closer to the original recursive algorithm, so easier to understand, but the bottom up method is usually a little more efficient.
Excerpt from The Algorithm Design Manual: The problem of longest common subsequence arises whenever we search for similarities across multiple texts. A particularly important application is in finding a consensus among DNA sequences. The genes for building particular proteins evolve with time, but the functional regions must remain consistent in order to work correctly. By finding the longest common subsequence of the same gene in different species, we learn what has been conserved over time.
The longest common substring problem is a special case of edit distance, when substitutions are forbidden and only exact character match, insert, and delete are allowable edit operations. Under these conditions, the edit distance between p and t is n+m-2 |lcs(p,t)|, since we can delete the missing characters from p to the lcs(p,t) and insert the missing characters from $t$ to transform p to t. This is particularly interesting because the longest common subsequence can be faster to compute than edit distance.
http://www.nist.gov/dads/HTML/longestCommonSubstring.html
See also longest common subsequence, shortest common superstring.
Note: The longest common substring is contiguous, while the longest common subsequence need not be.
Dan Hirschberg's pseudocode as an example of dynamic programming.
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
This short article describes an extension of the Longest Common Sub-string (LCS) problem with maximal consecutive. Personally I used this algorithm in computing the gloss overlaps (Lesk algorithm) for finding the number of shared common words between two strings (it means gloss here).Some applications of the LCS problem include:
- Searching for proteins with similar DNA sequences: DNA sequences (genes) can be represented as sequences of four letters ACGT, corresponding to the four submolecules forming DNA. When biologists find a new sequence, they typically want to know what other sequences it is most similar to. One way of computing how similar two sequences are is to find the length of their longest common subsequence.
- Approximate string matching like spell checkers.
- File comparison (used in diff, CVS, source comparer, cheater finder, plagiarism detection).
Preparing the ground
The original LCS problem
Let us start with a simple approach, given are two strings: short string (sentence) and long string (text), as in the string matching problem. You want to know if all the words of the sentence appear in order (but possibly separated) in the text. If they do, we say that the sentence is a subsequence of the text. That is the "longest common" is the subsequence of "the longest shared common between two strings". If they do not occur in the text, it still makes sense to find the longest subsequence that occurs both in the sentence and in the text. This is the longest common subsequence problem:
- Given two strings/sequences X and Y. Each string is composed by a list of words or abbreviations. We denote m to be the length of X and n to be the length of Y.
- Z is called as common subsequence, if it is subsequence of both X and Y.
- The requirement is finding the common subsequence which has the maximum length among all the possible common subsequences of X and Y.
Basic solution
How would we solve this problem? Can we find the overlapping sub-problems such that the optimal solution to the LCS problem consists of optimal solutions to the sub-problems?
Dynamic programming gives us a way of making the solution more efficient but the idea does not tell us how to find this:
- Think of "optimal substructure'' property (break into optimal subproblems).
- Think of a recursive solution.
There are two ways to implement dynamic programming: first is top-down (memoization) and second is bottom-up. The top down method is closer to the original recursive algorithm, the bottom up method is usually a little more efficient.
Optimal substructure
Let
and
be sequences (xi is from prefix to i), and let
be any LCS of X and Y.
- If
, then
and
are LCS of
and
.
- If
, then
implies that Z is an LCS of
- If
implies that Z is an LCS of X and
Recursive Formulation
The major idea of the dynamic programming solution is to check whenever we want to solve a sub-problem, whether we've already done it before. Each time we need the solution to a sub-problem, we first look up if that one's already in the array table, and return right away if it is. Otherwise we will perform the computation and store the result.
We define an array to store the sub-problem results of the previous step: C[i, j] = k to be the length of the LCS of X[1.. i] and Y[1.. j], where 1 <= i <= m and 1 <= j <= n.
Question is: Would the optimal solution for C[i, j] consist of optimal solutions for C[i', j'], where i' <= i and j' <= j?
There is one thing we have to worry about, and that is when we fill in a cell C[i, j], we need to already know the values it depends on, which in this case are C[i-1, j-1], C[i , j-1], and C[i-1, j]. Due to this reason we'll traverse the array forwards, from the first row working up to the last and from the first column working up to the last.
I am looking for a module to solve (or appoximately solve) the longest common substring problem.
I found two modules on CPAN: String-LCSS-0.10 and String-Ediff-0.01.
... ... ...
Hi, all. Thanks for the help. After spending some time with Algorithm::Diff, I've realized that Alg::Diff's LCS(Longest Common SubSequence) is not the same as String-LCSS (Longest Common Substring). Just wanted to share that (perhaps obvious) observation. LCSS does what I need, and is working fine for me...thanks!
Input description: A set S of strings
.
Problem description: What is the longest string S' such that for each
,
, the characters of S appear as a subsequence of
Discussion: The problem of longest common subsequence arises whenever we search for similarities across multiple texts. A particularly important application is in finding a consensus among DNA sequences. The genes for building particular proteins evolve with time, but the functional regions must remain consistent in order to work correctly. By finding the longest common subsequence of the same gene in different species, we learn what has been conserved over time.
The longest common substring problem is a special case of edit distance (see Section
), when substitutions are forbidden and only exact character match, insert, and delete are allowable edit operations. Under these conditions, the edit distance between p and t is n+m-2 |lcs(p,t)|, since we can delete the missing characters from p to the lcs(p,t) and insert the missing characters from t to transform p to t. This is particularly interesting because the longest common subsequence can be faster to compute than edit distance.
Issues arising include:
- Are you looking for a common substring or scattered subsequence? - In detecting plagiarism or attempting to identify the authors of anonymous works, we might need to find the longest phrases shared between several documents. Since phrases are strings of consecutive characters, we need the longest common substring between the texts.
The longest common substring of a set of strings can be identified in linear time using suffix trees, discussed in Section
For the rest of this discussion, we will restrict attention to finding common scattered subsequences. Dynamic programming can be used to find the longest common subsequence of two strings, S and T, of n and m characters each. This algorithm is a special case of the edit-distance computation of Section
and
. In general, if
, there is no way the last pair of characters could match, so
. If S[i] = T[j], we have the option to select this character for our substring, so
. This gives a recurrence that computes M, and thus finds the length of the longest common subsequence in O(nm) time. We can reconstruct the actual common substring by walking backward from M[n,m] and establishing which characters were actually matched along the way.
- What if there are relatively few sets of matching characters? - For strings that do not contain too many copies of the same character, there is a faster algorithm. Let r be the number of pairs of positions (i,j) such that
. Thus r can be as large as mn if both strings consist entirely of the same character, but r = n if the two strings are permutations of
. This technique treats the pairs of r as defining points in the plane.
The complete set of r such points can be found in O(n + m + r) time by bucketing techniques. For each string, we create a bucket for each letter of the alphabet and then partition all of its characters into the appropriate buckets. For each letter c of the alphabet, create a point (,t) from every pair
and
, where
and
are buckets for c.
A common substring represents a path through these points that moves only up and to the right, never down or to the left. Given these points, the longest such path can be found in
time. We will sort the points in order of increasing x-coordinate (breaking ties in favor of increasing y-coordinate. We will insert these points one by one in this order, and for each k,
, maintain the minimum y-coordinate of any path going through exactly k points. Inserting a new point will change exactly one of these paths by reducing the y-coordinate of the path whose last point is barely greater than the new point.
- What if the strings are permutations? - If the strings are permutations, then there are exactly n pairs of matching characters, and the above algorithm runs in
time. A particularly important case of this occurs in finding the longest increasing subsequence of a sequence of numbers. Sorting this sequence and then replacing each number by its rank in the total order gives us a permutation p. The longest common subsequence of p and
gives the longest increasing subsequence.
- What if we have more than two strings to align? - The basic dynamic programming algorithm can be generalized to k strings, taking
time, where n is the length of the longest string. This algorithm is exponential in the number of strings k, and so it will likely be too expensive for more than 3 to 4 strings. Further, the problem is NP-complete, so no better exact algorithm is destined to come along.
This problem of multiple sequence alignment has received considerable attention, and numerous heuristics have been proposed. Many heuristics begin by computing the pairwise alignment between each of the
pairs of strings, and then work to merge these alignments. One approach is to build a graph with a vertex for each character of each string. There will be an edge between
if the corresponding characters are matched in the alignment between S and T. Any k-clique (see Section
Although these cliques will define a common subsequence, there is no reason to believe that it will be the longest such substring. Appropriately weakening the clique requirement provides a way to increase it, but still there can be no promises.
Implementations: MAP (Multiple Alignment Program) [Hua94] by Xiaoqiu Huang is a C language program that computes a global multiple alignment of sequences using an iterative pairwise method. Certain parameters will need to be tweaked to make it accommodate non-DNA data. It is available by anonymous ftp from cs.mtu.edu in the pub/huang directory.
Combinatorica [Ski90] provides a Mathematica implementation of an algorithm to construct the longest increasing subsequence of a permutation, which is a special case of longest common subsequence. This algorithm is based on Young tableaux rather than dynamic programming. See Section
Notes: Good expositions on longest common subsequence include [AHU83, CLR90]. A survey of algorithmic results appears in [GBY91]. The algorithm for the case where all the characters in each sequence are distinct or infrequent is due to Hunt and Szymanski [HS77]. Expositions of this algorithm include [Aho90, Man89]. Multiple sequence alignment for computational biology is treated in [Wat95].
Certain problems on strings become easier when we assume a constant-sized alphabet. Masek and Paterson [MP80] solve longest common subsequence in
for constant-sized alphabets, using the four Russians technique.
Related Problems: Approximate string matching (see page
Google matched content |
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: March 12, 2019