|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
|
|
|
|
Pipes rank alongside the hierarchical file system and regular expressions as one of the three most powerful contributions of Unix to operating systems design. They appeared in Unix around 1972-1973, almost simultaneously with rewriting the kernel in C. This is an elegant implementation of coroutines in operating system as well as shell notation that allow to use them in shell programming.
Pipes are notation for specifying coroutines in such a way that any regular program that accepts input and produces based on it output can act as a coroutine under the supervision of the OS, using so called I/O redirection.
Coroutines are classic programming-in-the-large methodology that most know via pipes concept which was brought to mainstream by Unix.
The term "coroutine" was coined by Melvin Conway in 1958, when he invented the concept and applied it to the construction of a compiler ( see his classic 1963 paper Design of a Separable Transition-Diagram Compiler, publish in Communications of the ACM)
Figure 4 presents the coroutine structure of the Cobol compiler designed at Case. The program is separable under the condition that the two pairs of module^ which share tables are considered to be a single coroutine.The reader is asked to understand that the present treatment is concerned more with exposition than completeness. A more thorough treatment would not ignore copy, pictures, and literals, for example. Let it suffice to say that these features can be accommodated without any significant design changes over what is presented here.
In Figure 4 solid arrows are communication paths between coroutines; dashed arrows show access to tables. When the dashed arrow points to a table the latter is being built; when the dashed arrow points away the table is supplying values to the using coroutine. The specific operations performed by the coroutines will be discussed in the following four sections.
... ... ...
...The chief purpose of a compiler-writing technique is to reduce the labor which follows analysis and which is necessary for the production of the actual compiler. There are other ways to create a cheap compiler than simply to use a compiler as a programming aid. This article attempts to suggest one such way.
If a fast compiler is desired more can be said. The front end of any fast, one pass compiler will be written with an assembler; that’s a corollary of the Seventy-five Percent Rule and some common sense about efficiency of compiler-generated code. Furthermore, the really fast compilers will have only one pass; that’s the result of an analysis of how much extra work must be done by a multi-pass compiler. Notice that a corollary of these two statements is that really fast compilers can be written only for source languages which permit one-pass compilation. This proposition ought to be taken into account by language designers.
Our experience in the development of the prototype suggests that one analyst-programmer, with one or two understanding individuals around to talk to occasionally, can produce a Cobol compiler (sans library and object-program I-0 control system) in a year or less, if he is provided with an assembler which permits incorporating all the special formats he will need into the assembly language.
He is mostly known for formulation of so called Conway Law (first published in Datamation in 1968 and popularized by F. Books in The Mythical Man-Month) and Think Pascal debugger
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.
The fate of coroutine concept was much more difficult then the fate of Conway Law, which instantly found almost universal recognition. Like often happens with innovative concepts, Conway has difficulties in publishing his paper and that happened much later in Conway's article 'Design of a Separable Transition-Diagram Compiler', CACM 6 (1963), 396-408. In this paper Melvin Convey considered coroutines as a natural compiler writing paradigm, which was tremendous breakthrough in compiler design for the time: you can write multipass compiler and debug it using intermediate files one stage at the time (as output of previous stage can just be saved). Then you can integrate all passes using coroutines achieving much greater efficiency and eliminating and writing to the disk except by the final stage of the compiler.
But the concept itself was discovered much earlier and probably by multiple people. A primitive form of coroutine linkage had already been noted briefly as a 'programming tip' in an early UNIVAC publication Coroutines were independently studied by J. Erdwinn and J. Merner, at about the same time as Conway. The first academic discussion was in the first volume of the Art of Computer programming by Donald Knuth (1968).
Simula 67 was the first language that implement coroutines as language constructs. Here is explanatiuon of this concept from OOSC 2 28.9 EXAMPLES
Coroutines emulate concurrency on a sequential computer. They provide a form of functional program unit ("functional" as opposed to "object-oriented") that, although similar to the traditional notion of routine, provides a more symmetric form of communication. With a routine call, there is a master and a slave: the caller starts a routine, waits for its termination, and picks up where it left; the routine, however, always starts from the beginning. The caller calls; the routine returns. With coroutines, the relationship is between peers: coroutine a gets stuck in its work and calls coroutine b for help; b restarts where it last left, and continues until it is its turn to get stuck or it has proceeded as far as needed for the moment; then a picks up its computation. Instead of separate call and return mechanisms, there is a single operation, resume c, meaning: restart coroutine c where it was last interrupted; I will wait until someone e
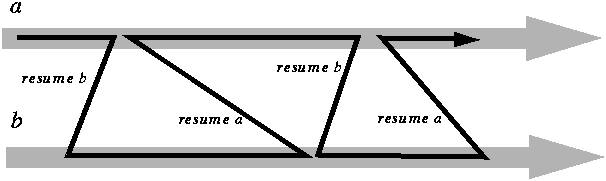
This is all strictly sequential and meant to be executed on a single process (task) of a single computer. But the ideas are clearly drawn from concurrent computation; in fact, an operating system that provide such schemes as time-sharing, multitasking (as in Unix) and multithreading, mentioned at the beginning of this chapter as providing the appearance of concurrency on a single computer, will internally implement them through a coroutine-like mechanism.
Coroutines may be viewed as a boundary case of concurrency: the poor man's substitute to concurrent computation when only one thread of control is available. It is always a good idea to check that a general-purpose mechanism degrades gracefully to boundary cases; so let us see how we can represent coroutines. The following two classes will achieve this goal.
Later it was desribed with several interesting examples in the influential 1972 book Structured Programming by Edsger W Dijkstra, C. A. R. Hoare, and Ole-Johan Dahl
Coroutines is a natural programming technique for assembler programmers. Actually in some ways more natural then subroutines.
Pipes were first suggested by M. Doug McIlroy, when he was a department head in the Computing Science Research Center at Bell Labs, the research arm of AT&T (American Telephone and Telegraph Company), the former U.S. telecommunications monopoly. McIlroy had been working on macros since the latter part of the 1950s, and he was a ceaseless advocate of linking macros together as a more efficient alternative to series of discrete commands. A macro is a series of commands (or keyboard and mouse actions) that is performed automatically when a certain command is entered or key(s) pressed.
McIlroy's persistence led Ken Thompson, who developed the original UNIX at Bell Labs in 1969, to rewrite portions of his operating system in 1973 to include pipes. This implementation of pipes was not only extremely useful in itself, but it also made possible a central part of the Unix philosophy, the most basic concept of which is modularity (i.e., a whole that is created from independent, replaceable parts that work together efficiently).
Let me state it again: the pipe is the the most elegant and powerful features of UNIX. In The Creation of the UNIX Operating System /Connecting streams like a garden hose the authors wrote:
Another innovation of UNIX was the development of pipes, which gave programmers the ability to string together a number of processes for a specific output.
Doug McIlroy, then a department head in the Computing Science Research Center, is credited for the concept of pipes at Bell Labs, and Thompson gets the credit for actually doing it.
McIlroy had been working on macros in the later 1950s, and was always theorizing to anyone who would listen about linking macros together to eliminate the need to make a series of discrete commands to obtain an end result.
"If you think about macros," McIlroy explained, "they mainly involve switching data streams. I mean, you're taking input and you suddenly come to a macro call, and that says, 'Stop taking input from here and go take it from there.'
"Somewhere at that time I talked of a macro as a 'switchyard for data streams,' and there's a paper hanging in Brian Kernighan's office, which he dredged up from somewhere, where I talked about screwing together streams like a garden hose. So this idea had been banging around in my head for a long time."
... ... ... ...
While Thompson and Ritchie were at the chalkboard sketching out a file system, McIlroy was at his own chalkboard trying to sketch out how to connect processes together and to work out a prefix notation language to do it.
It wasn't easy. "It's very easy to say 'cat into grep into...,' or 'who into cat into grep,'" McIlroy explained. "But there are all these side parameters that these commands have; they just don't have input and output arguments, but they have all these options."
"Syntactically, it was not clear how to stick the options into this chain of things written in prefix notation, cat of grep of who [i.e. cat(grep(who))]," he said. "Syntactic blinders: I didn't see how to do it."
Although stymied, McIlroy didn't drop the idea. "And over a period from 1970 to 1972, I'd from time to time say, 'How about making something like this?', and I'd put up another proposal, another proposal, another proposal. And one day I came up with a syntax for the shell that went along with the piping, and Ken said, 'I'm going to do it!'"
"He was tired of hearing this stuff," McIlroy explained. "He didn't do exactly what I had proposed for the pipe system call. He invented a slightly better one that finally got changed once more to what we have today. He did use my clumsy syntax."
"Thompson saw that file arguments weren't going to fit with this scheme of things and he went in and changed all those programs in the same night. I don't know how...and the next morning we had this orgy of one-liners."
"He put pipes into UNIX, he put this notation into shell, all in one night," McElroy said in wonder.
Next: Creating a programming philosophy from pipes and a tool box
Here is how Dennis M. Ritchie in his paper Early Unix history and evolution describes how pipes were introduced in Unix:
One of the most widely admired contributions of Unix to the culture of operating systems and command languages is the pipe, as used in a pipeline of commands. Of course, the fundamental idea was by no means new; the pipeline is merely a specific form of coroutine. Even the implementation was not unprecedented, although we didn't know it at the time; the `communication files' of the Dartmouth Time-Sharing System [10] did very nearly what Unix pipes do, though they seem not to have been exploited so fully.
Pipes appeared in Unix in 1972, well after the PDP-11 version of the system was in operation, at the suggestion (or perhaps insistence) of M. D. McIlroy, a long-time advocate of the non-hierarchical control flow that characterizes coroutines. Some years before pipes were implemented, he suggested that commands should be thought of as binary operators, whose left and right operand specified the input and output files. Thus a `copy' utility would be commanded by
To make a pipeline, command operators could be stacked up. Thus, to sort input, paginate it neatly, and print the result off-line, one would write
In today's system, this would correspond to
The idea, explained one afternoon on a blackboard, intrigued us but failed to ignite any immediate action. There were several objections to the idea as put: the infix notation seemed too radical (we were too accustomed to typing `cp x y' to copy x to y); and we were unable to see how to distinguish command parameters from the input or output files. Also, the one-input one-output model of command execution seemed too confining. What a failure of imagination!
Some time later, thanks to McIlroy's persistence, pipes were finally installed in the operating system (a relatively simple job), and a new notation was introduced. It used the same characters as for I/O redirection. For example, the pipeline above might have been written
The idea is that following a `>' may be either a file, to specify redirection of output to that file, or a command into which the output of the preceding command is directed as input. The trailing `>' was needed in the example to specify that the (nonexistent) output of opr should be directed to the console; otherwise the command opr would not have been executed at all; instead a file opr would have been created.
The new facility was enthusiastically received, and the term `filter' was soon coined. Many commands were changed to make them usable in pipelines. For example, no one had imagined that anyone would want the sort or pr utility to sort or print its standard input if given no explicit arguments.
Soon some problems with the notation became evident. Most annoying was a silly lexical problem: the string after `>' was delimited by blanks, so, to give a parameter to pr in the example, one had to quote:
Second, in attempt to give generality, the pipe notation accepted `<' as an input redirection in a way corresponding to `>'; this meant that the notation was not unique. One could also write, for example,
or even
The pipe notation using `<' and `>' survived only a couple of months; it was replaced by the present one that uses a unique operator to separate components of a pipeline. Although the old notation had a certain charm and inner consistency, the new one is certainly superior. Of course, it too has limitations. It is unabashedly linear, though there are situations in which multiple redirected inputs and outputs are called for. For example, what is the best way to compare the outputs of two programs? What is the appropriate notation for invoking a program with two parallel output streams?
I mentioned above in the section on IO redirection that Multics provided a mechanism by which IO streams could be directed through processing modules on the way to (or from) the device or file serving as source or sink. Thus it might seem that stream-splicing in Multics was the direct precursor of Unix pipes, as Multics IO redirection certainly was for its Unix version. In fact I do not think this is true, or is true only in a weak sense. Not only were coroutines well-known already, but their embodiment as Multics spliceable IO modules required that the modules be specially coded in such a way that they could be used for no other purpose. The genius of the Unix pipeline is precisely that it is constructed from the very same commands used constantly in simplex fashion. The mental leap needed to see this possibility and to invent the notation is large indeed.
Dartmouth Time Sharing System or DTSS for short, was the first large-scale time-sharing system to be implemented successfully
DTSS was inspired by a PDP-1-based time-sharing system at Bolt, Beranek and Newman. In 1962, John Kemeny and Thomas Kurtz at Dartmouth College submitted a grant for the development of a new time-sharing system to NSF (funded in 1964).[1] Its implementation began in 1963 by a student team [2] under the direction of Kemeny and Kurtz with the aim of providing easy access to computing facilities for all members of the college.[3] On May 1, 1964, at 4:00 a.m., the system began operations. It remained in operation until the end of 1999.[4][5] DTSS was originally implemented to run on a GE-200 series computer with a GE Datanet 30 as a terminal processor that also managed the 235. Later, DTSS was reimplemented on the GE 635,[1] still using the Datanet 30 for terminal control. The 635 version provided interactive time-sharing to up to nearly 300 simultaneous users in the 1970s, a very large number at the time.
Because of the educational aims, ease of use was a priority in DTSS design.
DTSS implemented the world's first Integrated Design Environment: a command-based system implementing the following commands.
- NEW — to name and begin writing a program
- OLD — to retrieve a previously named program
- LIST — to display the current program
- SAVE — to save the current program
- RUN — to execute the current program
These commands were often believed to be part of the Dartmouth BASIC language by users but in fact they were part of the time sharing system and were also used when preparing ALGOL[6] or FORTRAN programs via the DTSS terminals.
Any line typed in by the user, and beginning with a line number, was added to the program, replacing any previously stored line with the same number; anything else was immediately compiled and executed. Lines which consisted solely of a line number weren't stored but did remove any previously stored line with the same number. This method of editing provided a simple and easy to use service that allowed large numbers of teleprinters as the terminal units for the Dartmouth Timesharing system.
By 1968 and into the mid-1970s, the nascent network included users at other schools and institutions around the East Coast (including Goddard College, Phillips Andover and the U.S. Naval Academy), connected with Teletype Model 33 machines and modems. The system allowed email-type messages to be passed between users and real-time chat via a precursor to the Unix talk program.
In 2000 a project to recreate the DTSS system on a simulator was undertaken and as a result DTSS is now available for Microsoft Windows systems and for the Apple Macintosh computer.[7]
According to Dennis M. Ritchie (Early Unix history and evolution), "communication files" of the Dartmouth Time-Sharing System did very nearly what Unix pipes do, though they seem not to have been exploited so fully. They were developed by Ken Lochner in the 1960s (DTSS.doc)
Ken Lochner continually pushed the "right" abstractions Probably a major reason for the success of the second system Inventer of "communication files" that later became UNIX pipes
In early 1990 pipes were re-implemented in CMS by John P. Hartmann (IBM Denmark). In his implementation it was possible to merge different pipe streams making pipelines more complex. The same was possible with Unix named pipes but in less consistent way. A very interesting feature was that they were available from REXX which is a more powerful and elegant scripting language then Borne shell. That make the whole concept more powerful as in REXX allow writing more complex filters. In his Share paper CMS Pipelines Enhancements for Shared File System Byte File System published in 1995 he described the concept in the following way:
CMS Pipelines implements the dataflow model of programming. It passes records through programs in a multistream topology. This allows for selective processing of records based on their contents, or based on the previous history of input data.
VM/ESA Version 2 Release 1 contains many enhancements to CMS Pipelines. This session describes enhancements to:
Access files that are stored in a Shared File System filepool without needing to access the directory as a minidisk.
- Manage and access files residing in the OpenEdition file system.
A good introduction to CMS pipes can be found in Melinda Varian article PLUNGING INTO PIPES written in 1992 (V4617004.TXT):
The pipeline concept has not been integrated into command parsing in
CMS, as it has in UNIX. Instead, CMS Pipelines adds the new CMS
command, PIPE:
pipe pipeline-specification
The argument to PIPE is a "pipeline specification". A pipeline
specification is a string listing the stages to be run. The stages are
separated by the "stage separator character", which is usually a
vertical bar ("|"):
pipe stage-1 | stage-2 | stage-3 | stage-4
When CMS sees this PIPE command (whether in an EXEC or typed on the
command line), it passes control to the PIPE module, which interprets
the argument string as a pipeline containing four stages. The pipeline
parser locates the four programs and checks for correct syntax in the
invocations of any that are built-in programs. If all the stages are
specified correctly, the pipeline is executed; otherwise, the pipeline
parser issues useful error messages and exits.
Device Drivers
In UNIX, a program can do I/O to a device in exactly the same way it
does I/O to a file. Under the covers, the system has "device drivers"
to make this work. Because CMS does not provide such device
transparency, CMS Pipelines has its own device drivers, pipeline stages
that connect the pipeline to host interfaces, thus allowing other
pipeline stages to be completely independent of host interfaces.
CMS Pipelines provides a large number of device drivers. A very simple
pipeline might contain only device drivers. We may as well be
traditional and start with this one:
pipe literal Hello, World! | console
Here, the device driver literal inserts a record containing the phrase
"Hello, World! " into the pipeline. The device driver console then
receives that record and displays it on the console.
This pipeline reads lines from the console and writes them to the punch:
pipe console | punch
(It continues reading from the console and writing to the punch until it
reaches end-of-file, i.e., until it receives a null line as input.)
Plunging into Pipes page 4
========================================================================
As the use of console in these two examples shows, some device drivers
can be used for either reading or writing. If they are the first stage
in the pipeline, they read from the host interface. If they come later
in the pipeline, they write to the host interface. This pipeline
performs a simple echo operation:
pipe console | console
It just reads lines from the console and writes them back to the
console. A similar pipeline performs a more useful task; it copies a
file from one tape to another:
pipe tape | tape tap2 wtm
The first tape stage knows to read, because it can sense that it is the
first stage in the pipeline; the second tape stage knows to write,
because it can sense that it is not the first stage in the pipeline.
tap2 and wtm are arguments to the second tape stage. When the pipeline
dispatcher invokes the second tape stage, it passes along those
arguments, which tape recognizes as instructions to use the CMS device
TAP2 and to write a tapemark at the end of the data.
There are several device drivers to read and write CMS files. Some of
them will look familiar to you if you know UNIX, but may look rather
strange if you do not:
* The < ("disk read") device driver reads a CMS file and inserts
the records from the file into the pipeline. Thus, this
pipeline copies a file from disk to tape:
pipe < fn ft fm | tape
* > ("disk replace") writes records from the pipeline to the CMS
file specified by its arguments, replacing any existing file of
the same name, so this pipeline copies a file from tape to disk:
pipe tape | > fn ft fm
* >> ("disk append") is the same as >, except that it appends an
existing file of the specified name, if any, rather than
replacing it. Thus, this pipeline also copies a file from tape
to disk, but if the named file already exists, it is appended,
not replaced:
pipe tape | >> fn ft fm
(Note that although <, >, and >> look like the UNIX redirection
operators, they are actually the names of programs; like other CMS
program names, they must be delimited by a blank.)
An output device driver is not necessarily the last stage of a pipeline.
Output device drivers write the records they receive from the pipeline
Plunging into Pipes page 5
========================================================================
to their host interface, but they also pass those records back to the
pipeline, which then presents them as input to the following stage, if
there is one. For example, this pipeline reads a CMS file and writes
the records to a CMS file, to the console, to the punch, and to a tape:
pipe < fn ft fm | > outfn outft
outfm | console | punch | tape wtm
If you wanted to include that PIPE command in a REXX EXEC, you would
need to keep in mind that the entire command is a string, only portions
of which should have variables substituted. Thus, in an EXEC you would
write that PIPE command something like this:
'PIPE <' infn inft infm '| >' outfn outft
outfm '| console | punch | tape wtm'
That is, you would quote the parts that are not variable, while allowing
REXX to substitute the correct values for the variable fields, the
filenames.
As PIPE commands grow longer, using the linear form in EXECs becomes
somewhat awkward. Most experienced "plumbers" prefer to put longer
pipelines into "portrait format", with one stage per line, thus:
+-------------------------------------------------+
| |
| 'PIPE (name DRIVERS)', |
| '<' infn inft infm '|', |
| '>' outfn outft outfm '|', |
| 'console |', |
| 'punch |', |
| 'tape wtm' |
| |
+-------------------------------------------------+
You can use the FMTP XEDIT macro, which comes with CMS Pipelines, to
reformat a PIPE command into portrait format. Note the commas at the
ends of the lines; those are REXX continuation characters. This
pipeline specification will still be a single string once REXX has
interpreted it.
Note also the "global option" name in parentheses immediately following
the PIPE command. This gives the pipeline a name by which it can be
referenced in a traceback, should an error occur while the pipe is
running. (There are a number of other global options, but this is the
only one we will meet in this session.)
Once you have the pipeline in portrait format, you can key in comments
on each line and then invoke the SC XEDIT macro, which comes with CMS
Pipelines, to line them up nicely for you:
Plunging into Pipes page 6
========================================================================
+----------------------------------------------------------------------+
| |
| 'PIPE (name DRIVERS)', /* Name for tracing */ |
| '<' infn inft infm '|', /* Read CMS file */ |
| '>' outfn outft outfm '|', /* Copy to CMS file */ |
| 'console |', /* And to console */ |
| 'punch |', /* And to punch */ |
| 'tape wtm' /* And to tape */ |
| |
+----------------------------------------------------------------------+
You will notice that all the device drivers observe the rule that a
program that runs in a pipeline should be able to connect to any other
program. Although the device drivers are specialized on the side that
connects to the host, they are standard on the side that connects to the
pipeline.
There are four very useful device drivers to connect a pipeline to the
REXX environment:
* var, which reads a REXX variable into the pipeline or sets a
variable to the contents of the first record in the pipeline;
* stem, which retrieves or sets the values in a REXX stemmed
array;
* rexxvars, which retrieves the names and values of REXX
variables; and
* varload, which sets the values of the REXX variables whose names
and values are defined by the records in the pipeline.
All four of these stages allow you to specify which REXX environment is
to be accessed. If you do not specify the environment, then the
variables you set or retrieve are from the EXEC that contains your PIPE
command. But you may instead specify that the variables are to be set
in or retrieved from the EXEC that called the EXEC that contains your
PIPE command or another EXEC further up the chain, to any depth. For
example, this pipeline:
'PIPE stem parms. 1 | stem parms.'
retrieves the stemmed array "parms" from the environment one level back
(that is, from the EXEC that called this EXEC) and stores it in the
stemmed array "parms" in this EXEC. (If these two stages are reversed,
then the array is copied in the opposite direction.)
rexxvars retrieves the names and values of all exposed REXX variables
from the specified REXX environment and writes them into the pipeline,
starting with the source string:
Plunging into Pipes page 7
========================================================================
+----------------------------------------------------------------------+
| |
| 'PIPE rexxvars 1 | var source1' /* Get caller's source. */ |
| 'PIPE rexxvars 2 | var source2' /* And his caller's. */ |
| |
| Parse Var source1 . . . fn1 . |
| Parse Var source2 . . . fn2 . |
| |
| Say 'I was called from' fn1', which was called from' fn2'.' |
| |
+----------------------------------------------------------------------+
In this example, rexxvars is used twice, once to retrieve the variables
from the EXEC that called this one and once to retrieve the variables
from the EXEC that called that one. In each case, a var stage is then
used to store the first record produced by rexxvars (the source string)
in a variable in this EXEC, where it can be used like any other REXX
variable.
Another very useful group of stages issue host commands and route the
responses into the pipeline. Among these "host command processors" are:
* cp, which issues CP commands;
* cms, which issues CMS commands with full command resolution
through the CMS subcommand environment, just as REXX does for
the Address CMS instruction; and
* command, which issues CMS commands using a program call with an
extended parameter list, just as REXX does for the Address
Command instruction.
Each of these stages issues its argument string as a command and then
reads any records from its input stream and issues those as commands,
too. The command responses are captured, and each response line becomes
a record in the pipeline. For example, in this pipeline:
'PIPE cp query dasd | stem dasd.'
the cp stage issues a CP QUERY DASD command and writes the response into
the pipeline, where the stem stage receives it and writes it into the
stemmed array "DASD", setting "DASD.0" to the count of the lines in the
response.
There are a great variety of other device drivers, for example:
* xedit, which writes records from an XEDIT session to the
pipeline or vice versa;
* stack, which reads or writes the CMS program stack;
* sql and ispf, which interface to SQL and ISPF;
* qsam, which reads MVS files (and writes them under MVS);
* storage, which reads or writes virtual machine storage; and
* subcom, which sends commands to a subcommand environment.
The list of device drivers goes on and on, and it continues to grow.
Plunging into Pipes page 8
========================================================================
Other Built-in Programs
Pipelines built only of device drivers do not really show the power of
CMS Pipelines (although they may be quite useful, especially as they
often out-perform the equivalent native CMS commands). There are dozens
of other CMS Pipelines built-in programs. Most of these are "filters",
programs that can be put into a pipeline to perform some transformation
on the records flowing through the pipeline.
Using Pipeline Filters: A simple pipeline consisting of a couple of
device drivers wrapped around a few filter stages provides an instant
enhancement to the CMS command set. Once you have had some practice,
you will find yourself typing lots of little "throwaway" pipes right on
the command line.
Many CMS Pipelines filters are self-explanatory (especially as many of
them behave just like the XEDIT subcommand of the same name). For
example, this pipeline displays the DIRECTORY statement from a CP
directory:
pipe < user direct | find DIRECTORY | console
The find filter selects records using the same logic as the XEDIT FIND
subcommand.
This pipeline displays all the occurrences of the string "GCS" in the
CMS Pipelines help library:
pipe < pipeline helpin | unpack | locate /GCS/ | console
The unpack filter checks whether its input is a packed file and, if it
is, does the same unpack operation that the CMS COPYFILE and XEDIT
commands do. The locate filter selects records using the same logic as
the XEDIT LOCATE subcommand.
This pipeline tells you how many words there are in one of your CMS
files:
pipe < plunge script a | count words | console
A slightly more elaborate pipeline tells you how many different words
there are in that same file:
pipe < plunge script a | split | sort unique | count lines | console
split writes one output record for every blank-delimited word in its
input; sort unique then sorts those one-word records and discards the
duplicates, passing the unique records on to count lines to count.
count writes a single record containing the count to its output stream.
console reads that record and displays it on the console.
Plunging into Pipes page 9
========================================================================
This pipeline writes a CMS file containing fixed-format, 80-byte records
to a tape, blocking it in a format suitable to be read by other systems:
pipe < gqopt fortran a | block 16000 | tape
This pipeline writes a list of the commands used with "SMART" (RTM) to a
CMS file:
pipe literal next| vmc smart help| strip trailing | > smart commands a
literal writes a record containing the word "next". The vmc device
driver sends a help command to the SMART service machine via VMCF and
writes the response to the pipeline. It then reads the single record
from its input and sends a next command to the SMART service machine,
again writing the response to the pipeline. strip trailing removes
trailing blanks from the records that pass through it, thus turning the
blank lines in the response from SMART into null records. > reads
records from its input, discards those that are null, and writes the
others to the file SMART COMMANDS A.
And here is a pipeline I especially like; it would be typed on the XEDIT
command line:
pipe cms query search | change //INPUT / | subcom xedit
In this pipeline, the cms device driver issues the CMS QUERY SEARCH
command and routes the response into the pipeline; the change filter
(which works like the XEDIT CHANGE subcommand) changes each line of the
response into an XEDIT INPUT subcommand; and then subcom sends each line
to XEDIT, which executes it as a command. This is a very easy way to
incorporate the response from a command into the text of a file you are
editing.
The Specs Filter: Now, let's look at one of the less obvious filters,
specs. specs selects pieces of an input record and puts them into an
output record. It is very useful and not really as complex as it looks
at first. Its syntax was derived from the syntax for the SPECS option
of the CMS COPYFILE command, but it has long since expanded far beyond
the capabilities of that option:
* The basic syntax of specs is:
specs input-location output-location
with as many input/output pairs as you need.
* The input location may be a column range, such as "10-14".
"10.5" means the same thing as "10-14". "1-*" means the whole
record. "words 1-4" means the first four blank-delimited words.
The input may also be a literal field, expressed as a delimited
string, such as "/MSG/", or it may be "number", to get a record
number.
Plunging into Pipes page 10
========================================================================
* The output location may be a starting column number, or "next",
which means the next column, or "nextword", which leaves one
blank before the output field.
* A conversion routine, such as "c2d", may be specified between
the input location and the output location. The specs
conversion routines are similar to the REXX conversion functions
and are applied to the value from the input field before it is
moved into the output field.
* A placement option, "left", "center", or "right", may be
specified following the output location; for example, "number
76.4 right" puts a 4-digit record number right-aligned starting
in column 76.
+----------------------------------------------------------------------+
| |
| /* PIPEDS EXEC: Find lrecl of an OS dataset */ |
| |
| Parse Upper Arg dsname fm |
| |
| 'PIPE (name PIPEDS)', |
| 'command LISTDS' fm '( FORMAT |', /* Issue LISTDS. */ |
| 'locate /' dsname '/ |', /* Locate file we want. */ |
| 'specs word 2 1 |', /* Lrecl is second word. */ |
| 'console' /* Display lrecl. */ |
| |
+----------------------------------------------------------------------+
PIPEDS EXEC is a simple example of using specs. PIPEDS displays the
logical record length of an OS dataset. The command stage issues a CMS
LISTDS command with the FORMAT option and routes the response into the
pipeline, where locate selects the line that describes the specified
dataset, e.g.:
U 6447 PO 02/25/80 RES342 B SYS5.SNOBOL
specs selects only the second word of that line, the logical record
length ("6447"), and moves it to column 1 of its output record, which
console then reads and displays.
pipe < cms exec a | specs 1-27 1 8-27 nextword | > cms exec a
This is another simple example of using specs. The arguments to specs
here are two pairs of input-output specifications. The first
input-output pair ("1-27 1") copies the data from columns 1-27 of the
input record to columns 1-27 of the output record. The second
input-output pair ("8-27 nextword") copies the data from columns 8-27 of
the input record to columns 29-48 of the output record; that is, a blank
is left between the first output field and the second output field. So,
this pipeline would be used to duplicate the filenames in a CMS EXEC
created by the EXEC option of the CMS LISTFILE command. (This pipeline
Plunging into Pipes page 11
========================================================================
is almost 500 times as fast as the XEDIT macro I used to use to do this
same thing.)
Augmenting REXX: People often start in gradually using CMS Pipelines in
EXECs, first just taking advantage of the built-in programs that supply
function that is missing or awkward in REXX. Here is a function that
has been implemented a zillion times in REXX or Assembler:
'PIPE stem bananas. | sort | stem bunch.'
That sorts the values in the stemmed array "bananas" and puts them into
the array "bunch".
Here is an example of using specs to augment REXX (which has no "c2f"
function):
'PIPE var cpu2busy | specs 1-* c2f 1 | var cpu2busy'
The device driver var picks up the REXX variable "cpu2busy", which
contains a floating-point number stored in the System/370 internal
representation (e.g., '4419B600'x), and writes it to the pipeline.
specs reads the record passed from var and converts it to the external
representation of the floating-point number (6.582E+03), and then the
second var stage stores the new representation back into the same REXX
variable, allowing it to be used in arithmetic operations.
Another function CMS Pipelines brings to REXX programmers is an easy way
to process all the variables that have a given stem. In the example
below, rexxvars writes two records into the pipeline for each exposed
variable. One record starts with "n " and contains the variable's name;
the other starts with "v " and contains its value. The find stage
selects only the name records for variables with the stem "THINGS".
specs removes the "n ", and stem puts the names of the "THINGS"
variables into the stemmed array "vars", where they can be accessed with
a numeric index. (The buffer stage prevents the stem stage from
creating new variables while rexxvars is still loading the existing
variables.)
+----------------------------------------------------------------------+
| |
| 'PIPE', /* Discover stemmed variables: */ |
| 'rexxvars |', /* Get all variables. */ |
| 'find n THINGS.|', /* Select names of THINGS. */ |
| 'specs 3-* 1 |', /* Remove record type prefix. */ |
| 'buffer |', /* Hold all records. */ |
| 'stem vars.' /* Names of THINGS into stem. */ |
| |
| Do i = 1 to vars.0 |
| Say vars.i '=' Value(vars.i) |
| End |
| |
+----------------------------------------------------------------------+
Plunging into Pipes page 12
========================================================================
Replacing EXECIO: EXECIO is usually the first thing to go when one
learns CMS Pipelines. Anything that can be done with EXECIO can be done
with CMS Pipelines, generally faster and always more straightforwardly.
(And replacing EXECIO with a pipeline makes it easier to port an EXEC
between CMS and MVS.) Let's look at a few EXECIO examples from various
IBM manuals, along with the equivalent pipelines:
* These both read the first three records of a CMS file into the
stemmed array "X" and set the value of "X.0" to 3:
'EXECIO 3 DISKR MYFILE DATA * 1 ( STEM X.'
'PIPE < myfile data * | take 3 | stem x.'
* These both issue a CP QUERY USER command in order to set a
return code (without saving the response):
'EXECIO 0 CP ( STRING QUERY USER GLORP'
+++ RC(1045) +++
'PIPE cp query user glorp'
+++ RC(45) +++
* These both put a blank-delimited list of the user's virtual disk
addresses into the REXX variable "used":
Signal Off Error
'MAKEBUF'
Signal On Error
theirs = Queued()
'EXECIO * CP ( STRING Q DASD'
used = ''
Do While Queued() > theirs
Pull . cuu .
used = used cuu
End
'DROPBUF'
'PIPE cp q dasd | specs word 2 1 | join * / / | var used'
The EXECIO case comes from the REXX User's Guide. Admittedly,
it is rather old-fashioned code; nevertheless, its eleven lines
make up an all too familiar example of manipulating the CMS
stack. In the pipeline, the cp device driver issues the CP
QUERY DASD command and routes the response into the pipeline.
specs selects the second word from each input record and makes
it the first (and only) word in an output record. join * joins
all these records together into one record, inserting the
delimited string in its argument (a blank) between the values
from the individual input records. And var stores this single
record into the variable "used".
Plunging into Pipes page 13
========================================================================
Pipeline Programs: After a while, you will find yourself not just
augmenting your EXECs with small pipes, but also writing EXECs that are
predominantly pipes, such as REACCMSG EXEC:
+----------------------------------------------------------------------+
| |
| /* REACCMSG EXEC: Notify users to re-ACCESS a changed disk */ |
| |
| Parse Arg vaddr . |
| |
| 'PIPE (name REACCMSG)', |
| 'cp query links' vaddr '|', /* Issue CP QUERY LINKS. */ |
| 'split at , |', /* Get one user per line. */ |
| 'strip |', /* Remove leading blanks. */ |
| 'sort unique 1-8 |', /* Discard duplicates. */ |
| 'specs /MSG/ 1', /* Make into MSG commands. */ |
| 'word 1 nextword', /* Fill in userid. */ |
| '/Please re-ACCESS your/ nextword', |
| 'word 2 nextword', /* Fill in virtual address.*/ |
| '/disk./ nextword |', |
| 'cp' /* Issue MSG commands. */ |
| |
+----------------------------------------------------------------------+
REACCMSG is used to send a message to all the users linked to a
particular CMS disk to let them know that they should re-ACCESS the disk
because it has been changed. It uses built-in programs we have seen
before, but in a slightly more sophisticated manner: split receives the
response from the CP QUERY LINKS command:
PIPMAINT 320 R/O, MAINT 420 R/O, TDTRUE 113 R/O, Q0606 320 R/O
Q0606 113 R/O, SERGE 420 R/O
and splits those records into multiple records by breaking them up at
the commas between items; strip removes the leading blanks; and sort
unique sorts the records on the userid field in the first eight columns
and discards any duplicates, so that each user will be sent only one
message. This example shows a more elaborate use of specs than before,
but it is not difficult to understand if you keep in mind that specs's
arguments are always pairs of definitions for input and output. This
specs stage has been written in portrait format with each input-output
pair on a separate line. You will note that the input definitions in
three of the five pairs here are for literals. The first input-output
pair puts the literal "MSG" into columns 1-3 of the output record; the
second pair puts the userid from the first word of the input record
("word 1") into columns 5-12 of the output record; and so on. Then as
each record flows from the specs stage to the cp stage, cp issues it as
a CP MSG command.
The next example is a simple service machine that uses the starmsg
device driver to connect to the CP *ACCOUNT system service, so that it
can monitor attempts to LOGON to the system with an invalid password.
Plunging into Pipes page 14
========================================================================
Each time CP produces an accounting record, this starmsg stage receives
that record via IUCV and writes it to the pipeline (prefacing it with an
8-byte header). The locate stage discards all but the "Type 4" records,
which are the ones that CP produces when the limit of invalid LOGON
passwords is reached. specs formats a message containing a literal and
three fields from the accounting record, which console then displays.
(Note the stage separators on the left side here. This is a widely used
alternative portrait format.)
This pipeline runs until you stop it by using the haccount immediate
command, which CMS Pipelines sets up for you when it establishes the
connection to the *ACCOUNT system service. starmsg can also be used to
connect to several other CP system services, including *MSG and *MSGALL.
+----------------------------------------------------------------------+
| |
| /* HACKER EXEC: Display Type 4 Accounting Records. */ |
| |
| 'PIPE (name STARMSG)', |
| '| starmsg *account CP RECORDING ACCOUNT ON LIMIT 20', |
| '| locate 88 /4/', /* Only Type 4 records. */ |
| '| specs', /* Format warning message: */ |
| ' /Hacker afoot? / 1', /* literal, */ |
| ' 9.8 next', /* ACOUSER, */ |
| ' 37.4 nextword', /* ACOTERM@, */ |
| ' 79.8 nextword', /* ACOLUNAM. */ |
| '| console' /* Display on console. */ |
| |
| If Userid() <> 'OPERACCT' |
| Then 'CP RECORDING ACCOUNT OFF PURGE QID' Userid() |
| |
+----------------------------------------------------------------------+
The next example may be a bit arcane, but it can be very useful; it
reads a file containing textual material of arbitrary content and record
length and produces a file containing the same text formatted as
Assembler DC instructions for use, say, as messages:
Plunging into Pipes page 15
========================================================================
+----------------------------------------------------------------------+
| |
| /* MAKEDC EXEC: Reformat text into Assembler DC statements */ |
| |
| Parse Arg fn ft fm . /* File to be processed. */ |
| |
| "PIPE (name MAKEDC)", |
| "<" fn ft fm "|", /* Read the file. */ |
| "change /&/&&/ |", /* Double the ampersands. */ |
| "change /'/''/ |", /* Double the single quotes. */ |
| "specs", /* Reformat to DC statement: */ |
| " /DC/ 10", /* literal "DC" in col 10; */ |
| " /C'/ 16", /* literal "C'" in col 16; */ |
| " 1-* next", /* entire record next; and */ |
| " /'/ next |", /* terminate with quote. */ |
| "asmxpnd |", /* Split to continuations. */ |
| ">" fn "assemble a" /* Write the new file. */ |
| |
+----------------------------------------------------------------------+
The two change filters double any ampersands or quotes in the text. For
each input record, specs builds an output record that has "DC" in column
10 and "C" in column 16, followed by the input record enclosed in single
quotes. asmxpnd then examines each record to determine whether it
extends beyond column 71; if so, it breaks the record up into two or
more records formatted in accordance with the Assembler's rules for
continuations. And finally, > writes the reformatted records to a CMS
file. Thus, if the input file were to contain the line:
The PACKAGE file records have ' &1 &2 ' in columns 1-7 and a filename,
then these two records would appear in the output file:
DC C'The PACKAGE file records have '' &&1 &&2 '' in columns*
1-7 and a filename,'
Selection Filters: There are many more CMS Pipelines filters to learn,
but I want to mention one class in particular, the selection filters:
between frlabel nfind outside unique
drop inside nlocate take whilelab
find locate notinside tolabel
The selection filters are used to select certain records from among
those passing through the pipeline, while discarding all others. A
cascade of selection filters can quickly select the desired subset of
even a very large file. I routinely use pipelines to filter files
containing tens (or even hundreds) of thousands of records to select the
records I need for some purpose.
One simple example is a filter I use with the NETSTAT CLIENTS command.
NETSTAT CLIENTS produces hundreds of lines of output, several lines for
Plunging into Pipes page 16
========================================================================
each user who has used TCP/IP since the last IPL. The first line of the
response for each user begins with the string "Client:" followed by the
userid; and one of the other lines begins with the string "Last
Touched:". Usually, when I issue a NETSTAT CLIENTS command, I need to
see only these two lines for each of four servers. The eight lines I
want are easily isolated using two selection filters:
+----------------------------------------------------------------------+
| |
| /* STATPIPE EXEC: Display "Last Touched" for BITFTPn. */ |
| |
| 'PIPE', |
| 'command NETSTAT CLIENTS |', |
| 'between /Client: BITFTP/ /Last Touched:/ |', |
| 'notinside /Client: BITFTP/ /Last Touched:/ |', |
| 'console' |
| |
+----------------------------------------------------------------------+
The command stage issues a NETSTAT CLIENTS command and routes the
response into the pipeline. The between filter selects groups of
records; its arguments are two delimited strings, describing the first
and last records to be selected for each group. So, the between stage
here selects groups of records that begin with a record that begins
"Client: BITFTP" and that end with a record that begins "Last Touched:".
notinside then further refines the data by selecting only those records
that are not between a record that begins with "Client: BITFTP" and a
record that begins with "Last Touched:". That leaves us with only those
two lines for each client I am interested in, the ones whose userids
start "BITFTP".
You will likely find that many of your pipelines process the output of
CP or CMS commands or CMS or MVS programs. The output from UNIX
commands and programs is generally designed to be processed by a pipe,
so it tends to be essentially "pure data", with few headers and
trailers. With CP, CMS, and MVS output, however, you generally need to
winnow out the chaff to get down to the data. Although I cannot go over
the selection filters in detail today, they are easy to use and quite
powerful, so you should not hesitate to process listing files that were
designed to be read by humans and that have complicated headers and
trailers and carriage control. It is very easy to write a pipe that
reads such a file and pares it down to the bare data.
LIST2SRC EXEC is an example of really using the selection filters; I
will leave the detailed interpretation of LIST2SRC as an exercise for
you. Basically, LIST2SRC reads a LISTING file produced by Assembler H
and passes it through a series of selection filters, winnowing out the
chaff in order to reconstruct the original source file. Although this
is a "quick & dirty" program (and not quite complete), it is a good
example of "pipethink", of solving a complex problem by breaking it up
into simple steps:
Plunging into Pipes page 17
========================================================================
+----------------------------------------------------------------------+
| |
| /* LIST2SRC EXEC: Re-create the source from a LISTING file */ |
| Signal On Novalue |
| |
| Parse Arg fn . |
| |
| 'PIPE (name LIST2SRC)', |
| '| <' fn 'listing *', /* Read the LISTING file */ |
| '| mctoasa', /* Machine carriage ctl => ASA */ |
| '| frlabel - LOC', /* Discard to start of program */ |
| '| drop 1', /* Drop that '- LOC' line too */ |
| '| tolabel - POS.ID', /* Keep only up to relocation */ |
| '| tolabel -SYMBOL', /* dictionary or cross-ref */ |
| '| tolabel 0THE FOLLOWING STATEMENTS', /* or diagnostics */ |
| '| outside /1/ 2', /* Drop 1st 2 lines on each pg */ |
| '| nlocate 5-7 /IEV/', /* Discard error messages */ |
| '| nlocate 41 /+/', /* Discard macro expansions */ |
| '| nlocate 40 / /', /* Discard blank lines */ |
| '| specs 42.80 1', /* Pick out source "card" */ |
| '| >' fn 'assemble a fixed' /* Write new source (RECFM F) */ |
| |
+----------------------------------------------------------------------+
Subroutine Pipelines
Once you have been using CMS Pipelines for a while, you may find that
there are some sequences of stages that you use often:
pipe stage-a | stage-b | stage-c | stage-d | stage-e
pipe stage-x | stage-b | stage-c | stage-d | stage-y
In that case, it is time to move those stages into a subroutine
pipeline, polish them a bit, generalize them a bit, and create your own
little gem:
+------------------------------------------------------------------+
| |
| /* MYSUB REXX */ |
| |
| 'CALLPIPE *: | stage-b | stage-c | stage-d | *:' |
| |
+------------------------------------------------------------------+
Then whenever you need the function performed by your subroutine, you
simply use its name as a stage name ("mysub" in this case):
pipe stage-a | mysub | stage-e
pipe stage-x | mysub | stage-y
Plunging into Pipes page 18
========================================================================
The subroutine may look a bit mysterious, but it is simply a pipeline
stage written in REXX. If we look at it again in portrait format, it
can be demystified quickly:
+----------------------------------------------------------------------+
| |
| /* MYSUB REXX: Generic subroutine pipeline */ |
| |
| 'callpipe', /* Invoke pipeline */ |
| '*: |', /* Connect input stream */ |
| 'stage-b |', |
| 'stage-c |', |
| 'stage-d |', |
| '*:' /* Connect output stream */ |
| |
| Exit RC |
| |
+----------------------------------------------------------------------+
There are just a few things one needs to understand about subroutine
pipelines:
1. The CMS Pipelines command callpipe says to run a subroutine
pipeline; callpipe has the same syntax and the same options as the
PIPE command itself.
2. Those "*:" sequences are called "connectors". The connector at
the beginning tells the pipeline dispatcher to connect the output from
the previous stage of the calling pipeline to the input of the first
stage of this subroutine pipeline, stage-b. The connector at the end
says to connect the output from the last stage of this subroutine
pipeline, stage-d, to the input of the next stage in the calling
pipeline.
3. When you use REXX to write an XEDIT subroutine, the default
subcommand environment is XEDIT. Similarly, when you use REXX to
write a CMS Pipelines subroutine, the default subcommand environment
executes CMS Pipelines commands. Thus, if you wish to issue CP or CMS
commands in your subroutine, you will need to use the REXX Address
instruction.
4. When you use REXX to write an XEDIT subroutine, the subroutine has
a filetype of XEDIT, but when you use REXX to write a CMS Pipelines
subroutine, the filetype is not PIPE. It is REXX.
5. Arguments passed to a subroutine are available to the REXX Parse
Arg instruction.
Let's look at an example of a real subroutine pipeline, HEXSORT, which
sorts hexadecimal numbers. An ordinary sort does not work for
hexadecimal numbers (i.e., base 16 numbers, expressed with the
"numerals" 0-9, A-F), because the EBCDIC collating sequence sorts A-F
Plunging into Pipes page 19
========================================================================
before 0-9. This handy little subroutine pipeline sorts hexadecimal
data correctly by using the trick of temporarily translating A-F to
characters higher in the collating sequence than 0-9 (which are F0-F9 in
hexadecimal):
+----------------------------------------------------------------------+
| |
| /* HEXSORT REXX: Hexadecimal sort, 0123456789ABCDEF */ |
| |
| Parse Arg sortparms /* Get parms, if any */ |
| |
| 'callpipe (name HEXSORT)', /* Invoke pipeline */ |
| '*: |', /* Connect input stream */ |
| 'xlate 1-* A-F fa-ff fa-ff A-F |', /* Transform for sort */ |
| 'sort' sortparms '|', /* Sort w/caller's parms */ |
| 'xlate 1-* A-F fa-ff fa-ff A-F |', /* Restore */ |
| '*:' /* Connect output stream */ |
| |
| Exit RC |
| |
+----------------------------------------------------------------------+
The arguments to the xlate stages here are a column range, "1-*", which
means the entire record, followed by pairs of character ranges
specifying "to" and "from" translations. Records flow in from the
calling pipeline through the beginning connector; they are processed
through the xlate, sort, and xlate stages; and then they flow out
through the end connector back into the calling pipeline. If the caller
specifies an argument, that argument is passed to the sort stage to
define a non-default sort operation. Here is a typical invocation:
'PIPE stem mdisk. | hexsort 7.3 | stem mdisk.'
That sorts an array of minidisk records from a CP directory into device
address order. (The device addresses are hexadecimal numbers in columns
7-9 of the minidisk records.)
Of course, it is not necessary to put these operations into a
subroutine. You could simply use the xlate-sort-xlate sequence in all
your pipelines, whenever you need to do a hexadecimal sort, but it is
much better to hide such complexity. Once you have this subroutine
built, you can invoke it by name from any number of pipelines and need
never think about the problem again.
Furthermore, by building the subroutine with a simple, well-defined
interface and at the same time making its function as generic as
possible, you create a piece of code that can be used over and over
again. Here is another example of invoking HEXSORT:
'PIPE cp q nss map | drop 1 | hexsort 33-44 | > nss map a'
Plunging into Pipes page 20
========================================================================
That issues a CP QUERY NSS command, drops the header line from the
response, and sorts the remaining lines to produce a list of saved
systems in memory address order. (The virtual memory addresses are
hexadecimal numbers starting in column 33 of the response lines.)
A subroutine pipeline is often the cleanest way to package a function
that you have implemented with CMS Pipelines. If you make it a
subroutine pipeline, then the people you give it to can easily invoke it
from their own pipes.
Writing REXX Filters
The time will come when you have a problem that cannot be solved by any
reasonable combination of CMS Pipelines built-in programs. You will
need to write a filter of your own, preferably in REXX. A REXX filter
is similar to the simple subroutine pipelines we have just been looking
at. It has a filetype of REXX; its subcommand environment executes CMS
Pipelines commands; it is invoked by using its name as a stage in a
pipeline; and it can receive passed arguments.
You will find writing your own pipeline filters in REXX to be very easy
once you understand the basics. When I am writing a filter, I always
start with this dummy filter that does nothing at all except pass
records through unchanged:
+----------------------------------------------------------------------+
| |
| /* NULL REXX: Dummy pipeline filter */ |
| Signal On Error |
| |
| Do Forever /* Do until EOF */ |
| 'readto record' /* Read from pipe */ |
| 'output' record /* Write to pipe */ |
| End |
| |
| Error: Exit RC*(RC<>12) /* RC = 0 if EOF */ |
+----------------------------------------------------------------------+
There are only a few new things one needs to learn to understand this
REXX filter:
1. The CMS Pipelines command readto reads the next record from the
pipeline into the specified REXX variable ("record" in this case).
2. The CMS Pipelines command output writes a record to the pipeline.
The contents of the record are the results of evaluating the
expression following the output command (again, in this case, the
value of the REXX variable "record").
Plunging into Pipes page 21
========================================================================
3. The pipeline dispatcher sets return code 12 to indicate
end-of-file. A readto command completes with a return code of 12 when
the stage before it in the pipeline has no more records to pass on to
it. An output command completes with a return code of 12 when the
stage following it in the pipeline has decided to accept no more input
records.
So, this filter, NULL, reads a record from the pipeline and writes it
back to the pipeline unchanged. It keeps on doing that until an error
is signalled, i.e., until a non-zero return code is set. That causes a
transfer to the label "Error" in the last line of the EXEC. The most
likely non-zero return code would be a return code 12 from the readto
command, which would indicate end-of-file on the input stream, but the
output command could get return code 12 instead, or there could be a
real error. If the return code is 12, then before exiting the filter
sets its own return code to 0 to indicate normal completion. Any other
return code is passed back to the caller.
The effect of including the NULL filter in a pipeline:
pipe stage-a | null | stage-b | stage-c
is simply to make the pipeline run a bit slower. But once you
understand NULL, you can quickly go on to writing useful filters, such
as REVERSE, which reverses the contents of the records that pass through
it:
+----------------------------------------------------------------------+
| |
| /* REVERSE REXX: Filter that reverses records */ |
| Signal On Error |
| |
| Do Forever /* Do until EOF */ |
| 'readto record' /* Read from pipe */ |
| 'output' Reverse(record) /* Write to pipe */ |
| End |
| |
| Error: Exit RC*(RC<>12) /* RC = 0 if EOF */ |
| |
+----------------------------------------------------------------------+
We can make that example slightly more complex, to illustrate one more
concept that you will need when writing filters. This filter reverses
only the even-numbered lines passing through it:
Plunging into Pipes page 22
========================================================================
+----------------------------------------------------------------------+
| |
| /* BOUSTRO REXX: Filter that writes records boustrophedon */ |
| Signal On Error |
| |
| Do recno = 1 by 1 /* Do until EOF */ |
| 'readto record' /* Read from pipe */ |
| If recno // 2 = 0 /* If even-numbered */ |
| Then record = Reverse(record) /* line, reverse */ |
| 'output' record /* Write to pipe */ |
| End |
| |
| Error: Exit RC*(RC<>12) /* RC = 0 if EOF */ |
| |
+----------------------------------------------------------------------+
Each stage in a pipeline runs as a "co-routine", which means that it
runs concurrently with the other stages in the pipeline. It is invoked
once, when the pipeline is initiated, and remains resident. So, when
BOUSTRO is ready for another record, it calls upon the pipeline
dispatcher by doing a readto. The dispatcher may then decide to
dispatch some other co-routine, but it will eventually return control to
this one, which will continue reading and writing records until an error
is signalled. Thus, when you are writing a CMS Pipelines filter, you
need not worry (as I did at first) about where to save local variables,
such as "recno" here, between "calls" to your filter. Your filter is
called only once and then runs concurrently with the other stages in the
pipeline. There is nothing special that your filter needs to do in
order to run concurrently with the other stages; the pipeline dispatcher
takes care of all that for you.
I would like to show one more example of a simple REXX filter, AVERAGE,
which illustrates the point that your filter can decide not to write a
record back to the pipeline for every record it reads from the pipeline.
AVERAGE first reads all the input records; then, when it gets
end-of-file on its input, it calculates the contents of a single output
record and writes that to the pipeline:
Plunging into Pipes page 23
========================================================================
+----------------------------------------------------------------------+
| |
| /* AVERAGE REXX: Filter that averages input */ |
| Signal On Error |
| |
| acum = 0 /* Initialize */ |
| |
| Do nobs = 0 by 1 /* Do until EOF */ |
| 'readto record' /* Read from pipe */ |
| Parse Var record number . /* Get number */ |
| acum = acum + number /* Accumulate */ |
| End |
| |
| Error: If RC = 12 /* If EOF, then */ |
| Then 'output' Format(acum/nobs,,2) /* write average */ |
| Exit RC*(RC<>12) /* RC = 0 if EOF */ |
| |
+----------------------------------------------------------------------+
Differences from UNIX Pipes
That is as many examples of using pipelines in CMS as we have time for
right now. I have pointed out some of the differences between the UNIX
and CMS implementations of pipelines. You may have noticed some of the
others:
* As you would expect, CMS Pipelines is record-oriented, rather than
character-oriented.
* CMS Pipelines implements asynchronous input, immediate commands, and
dynamic reconfiguration of pipeline topology.
* CMS Pipelines implements multi-stream pipelines. These networks of
interconnected pipelines allow selection filters to split a file into
streams that are processed in different ways. The streams can then be
recombined for further processing.
* Most CMS Pipelines stages run unbuffered; that is, they process each
input record as soon as it is received and pass it on to the following
stage immediately. (Of course, some pipeline stages, such as sort,
must, by their nature, be buffered.) Running the stages unbuffered is
necessary to allow records flowing through a multi-stream pipeline to
arrive at the end in a predictable order. It can have the advantage
of greatly reducing the virtual memory requirements. Thus, CMS
Pipelines can often be used to perform operations that cannot be done
with XEDIT because of virtual memory constraints.
* CMS Pipelines runs a pipeline only after all its stages have been
specified correctly.
Plunging into Pipes page 24
========================================================================
* CMS Pipelines programs can co-ordinate their progress via "commit
levels" and can stop the pipeline when a program encounters an error.
* When the CMS Pipelines PIPE command completes, it sets its return code
to the worst of the return codes set by the stages in the pipeline.
To sum up the differences between UNIX pipes and CMS Pipelines, let me
quote a colleague of mine who said recently, "You know what I really
miss in UNIX? CMS Pipelines!"
Advanced Topics
I have had time to give you only a flavor of CMS Pipelines. I have
barely alluded to multi-stream pipelines, a very powerful extension to
the basic pipeline concept with which you will want to become familiar.
I also have not mentioned that CMS Pipelines can be run under GCS, TSO,
and MUSIC. CMS Pipelines can now be ordered with MUSIC, and although it
is not officially supported for TSO and GCS, it contains device drivers
developed specifically for those environments. The Program Directory
for the PRPQ has an appendix that discusses installing and using CMS
Pipelines with all three of these systems.
See also
CMS Pipelines Explained, PDF format (117K), revised 2007-09-10
CMS Pipelines Enhancements for Shared File System and Byte File System, LIST3820 format, packed (24K); PDF format (44K)
Writing Assembler Filters for Use with CMS Pipelines, LIST3820 format, packed (104K); PDF format (92K) Note that the information in this paper is to a large extent obsolete.
PIPE Command Programming Interface, LIST3820 format, packed (196K), revised 05/20/97
CMS Pipelines Procedures Macro Language, LIST3820 format, packed (360K) PDF format (449K) Note that while the PDF file shows a formatting date of July 18 2006, the contents are unchanged from the 1997 edition. In particular, the paper makes no mention of the current location of things, such as FPLGPI and FPLOM MACLIBs
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: March, 12, 2019