|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| Any intelligent fool can make things bigger and more complex... It takes a touch of genius - and a lot of courage to move
in the opposite direction.
Albert Einstein |
|
| "featuritis" -- the tendency to add feature after feature with each new software
release -- probably has more to do with code bloat than any other single factor. The benefits of Free software, free candy and new features are all meaningless, if the user isn't in control. |
|
|
KISS, an acronym for "keep it simple, stupid", is a design principle noted by the US Navy in 1960. It is intrinsically connected with the notion of Conceptual Integrity. The KISS principle states that most systems work best if they are kept simple rather than made complicated; therefore, simplicity should be a key goal in design, and unnecessary complexity should be avoided. The phrase has been associated with Kelly Johnson, lead engineer at the Lockheed Skunk Works (creators of the Lockheed U-2 and SR-71 Blackbird spy planes) . The principle is best exemplified by the challenge of the military jet designers: that the jet aircraft they were designing must be repairable by an average mechanic in the field under combat conditions with only these tools. Hence, the "stupid" in KISS acronym refers to the relationship between the way things break and the sophistication/expertise available to repair them. The term "KISS principle" was in popular use by 1970. Minimalism is implicit in the Unix philosophies of "everything is a text stream" and "do one thing and do it well", although modern Unix/Linux distributions do not adhere to this philosophy.]
In computer programming, code bloat is the production of program code (source code or machine code) that is perceived as unnecessarily long, slow, or otherwise wasteful of resources. Often this is due to the customers' ignorance and unability to decide what is essential versus and what is nice-to-have". Enhanced user convenience and functionality supposedly justify the increased size of software, but Wirth argues that people are increasingly misinterpreting complexity as sophistication, that "these details are cute but not essential, and they have a hidden cost."
Code bloat can be caused by the programming language in which the code is written, or the programmer writing it or more commonly by wrong architecture of the software system adopted in order to make it more generic then necessary.
Typically code bloat refers to source code size (as produced by the programmer). IBut it is equally applicable to the generated code size and inefficiencies of the run time (Python runtime performance is a good example here).
Software bloat can be caused not only by feature creep but by adoption of too many abstraction layers, which is a typical disease in projects that use OO languages ("lasagna code").
Complex software systems definitely can be build and have thier place (as the success of Windows, RHEL, Python and Perl signify), but never can be fully comprehended, or debugged. For users complex software systems it is typical to use a very small part of functionality provided. Everybody is useing some kind of the subset, not the full language of full capabilities of the OS.
It is difficult to design system with the main goal of simplicity and conceptual integrity, as it often contradicts both the stricture of organization that develops software and the complexity of environment in which particular system needs to operate. In this sense complex non-orthogonal languages like Python or Perl are by product of the complexity of environment in which they operate.
Theoretically, by breaking a project down into manageable parts can we hope to implement software in an effective manner. But "the road to hell is paved with good intentions." Much depends on our level of understanding of requirements (which typically shift during the implementation). In this sense, Software Prototyping is vital for designing complex software project and can help to avoid Featuritis, as in this case you have a user feedback and observe how user interact with your prototype. That allows you more confidently decide what matters and what is not.
For already existing complex software system another problem arise of somebody attempt to simplify and streamline the code base: inertia against changes. It can be made less severe if the system consists of well defined component interacting in a documented manner, but this is easier said then done. Often attempt to change codebase of a complex system open a can of worms as component interact between each other in a hidden ways that you initially do not understand and often do not suspect that such interaction exist. In this sense Software renovation is more complex than designing anew system from scratch. Probably by several orders of magnitude.
Other things equal simpler solution to the problem has advantages. This idea was expressed in different ways in such popular quotes as Ockham’s razor, Einstein’s statement about the simplicity of theories or simply reciting the KISS (Keep It Simple Stupid) mantra. But independently of what quote about the value of simplicity we prefer, reducing complexity to a more meaningful level and reducing featuritis is of paramount importance in software. It is not always possible as complex software often reflects complex environment in which it operated and, especially, the structure or the organization which created it ( Conway Law )
Here is how "software bloat" is defined in famous Jargon File:
software bloat
<jargon, abuse> The result of adding new features to a program or system to the point where the benefit of the new features is outweighed by the extra resources consumed (RAM, disk space or performance) and complexity of use. Software bloat is an instance of Parkinson's Law: resource requirements expand to consume the resources available. Causes of software bloat include second-system effect and creeping featuritis. Commonly cited examples include Unix's "ls(1)" command, the X Window System, BSD, Missed'em-five, OS/2 and any Microsoft product.
creeping featurism, with its own spoonerization: `feeping creaturitis'. Some people like to reserve this form for the disease as it actually manifests in software or hardware, as opposed to the lurking general tendency in designers' minds. (After all, -ism means `condition' or `pursuit of', whereas -itis usually means `inflammation of'.)
Jargon File
Fighting featuritis is known to be a tremendously difficult task that requires a lot of innovation and self-discipline. One fruitful approach is raising the level of your implementation language and using scripting language along with lower level language instead of using just one.
Also adding features until you convert your product into a Christmas tree is easy and natural strategy, almost irresistible... Actually that's why I value scripting languages so highly: they provide a novel way to reduce (actually not exactly reduce, but at least hide) the complexity permitting the developer to operate at the higher level of abstractions. And it permit creating more complex and powerful systems that have shorter and thus more maintainable code.
Some very good analogies are used to explain the principles, with my favorite being the broken window tale. The basic story is simple: abandoned buildings (or automobiles on the street) remain untouched until a window is broken. Left un-repaired, this sends a message that the object is fair game so within a very short time, vandals destroy the rest. The same thing happens in software development. Once a sub par feature is passed as acceptable, the signal to everyone is clear, and the quality of the remaining work suffers.
This is especially true for general purpose libraries. Once they became "too generally purpose" they became useless. Good example is glib 2.x vs glib 1.x: glib-1.2.10 is 1/2 of uclibc in size. glib-2.2.2 is 2 times uclibc. For times growth with very little useful functionality premium. Here is an interesting post on this topic from Tim Hockin:
On Sun, Oct 31, 2004 at 01:11:07AM +0300, Denis Vlasenko wrote:
> I am not a code genius, but want to help.
>
> Hmm probably some bloat-detection tools would be helpful,
> like "show me source_lines/object_size ratios of fonctions in
> this ELF object file". Those with low ratio are suspects of
> excessive inlining etc.The problem with apps of this sort is the multiple layers of abstraction.
Xlib, GLib, GTK, GNOME, Pango, XML, etc.
No one wants to duplicate effort (rightly so). Each of these libs tries to do EVERY POSSIBLE thing. They all end up bloated. Then you have to link them all in. You end up bloated. Then it is very easy to rely on
those libs for EVERYTHING, rather thank actually thinking.So you end up with the mindset of, for example, "if it's text it's XML". You have to parse everything as XML, when simple parsers would be tons faster and simpler and smaller.
Bloat is cause by feature creep at every layer, not just the app.
Youck.
Over the history of software development (or at least since advent of IBM mainframes) bigger software was often equated with being better software. Commercial companies like Adobe (Acrobat is really horrible bloatware, probably the champion of the field), IBM (Webshere, Tivoli, you name it), Microsoft (Windows 10; although it can be trimmed to barebones) and Oracle have a stake in producing big complex software. At the same time products like Excel 2003 while big are surprisingly flexible and robust. I would not call Excel 2003 bloatware but it definitely several times bigger then, say, Excel 97 which has approximately 80% of Excel 2003 functionality.
Linux suffered from the same disease (especially in Red Hat and Suse distributions) and the level of bloat Linux is now pretty close to Windows.
Regarding the eternal vicious circle of bloated software faster processors -> even more bloated software -> even faster processors, do any of you honestly suspect there might be some kind of liason between the parties concerned in order to perpetuate these largely unnecessary upgrades :-)
There may be a conspiracy between the hardware manufactures and software designers in order to design software to use up these CPU cycles and eat RAM like there's no tomorrow :-)
| A delicate balance is necessary between sticking with the things you know and can rely upon, and exploring things which have
the potential to be better. Assuming that either of these strategies is the one true way is silly.
-- Graydon Hoare |
There is no free lunch. Many factors and pressures tend to make programs more complicated (and therefore more expensive and buggy). One is technical machismo. Programmers are bright people who are (justly) proud of their ability to handle complexity and juggle abstractions. Often they compete with their peers to see who can build the most intricate and beautiful complexities. Just as often, their ability to design outstrips their ability to implement and debug, and the result is an expensive failure.
Often (at least in the commercial software world) excessive complexity comes from project requirements that are based on the marketing fad of the month rather than the reality of what customers want or software can actually deliver. Also complexity in commercial products is a time-tested defense against competitors. Many a good design has been smothered under marketing's pile of “check-list features” — features which, few customers benefit from. But here you can trap competition pretty nicely: usually competitors feel that they has to compete with chrome by adding more chrome. They forget that chrome tend to benefit the first comer. And that along tend to protect you from all, but the most talented competitors who can transcend this "more chrome" strategy and concentrate on better functionality and compatibility. For everybody else massive bloat naturally diminishes compatibility and leads to incompatibilities that segment the field; your former competitor suddenly moves into a different niche or just die because he does not have the same resources as you. Look at Quattro Pro and Word Perfect as two interesting examples.
The only way to avoid these traps is to encourage a software culture that actively resists bloat and complexity — an engineering tradition that puts a high value on simple solutions, looks for ways to break program systems up into small cooperating pieces, and reflexively fights attempts to gussy up programs with a lot of chrome (or, even worse, to design programs around the chrome). This tradition is associated with Unix and we need a conscious efforts to preserve it despite many Windows-emulators that now operated in Linux world.
Dr. Nikolai Bezroukov
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
Jun 02, 2021 | www.reddit.com
Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new features.
By now, and to be frank in the last 30 years too, this is complete and utter bollocks. Feature creep is everywhere, typical shell tools are choke-full of spurious additions, from formatting to "side" features, all half-assed and barely, if at all, consistent.
Nothing can resist feature creep. not_perfect_yet 3 years ago
name_censored_ 3 years agoIt's still a good idea. It's become very rare though. Many problems we have today are a result of not following it.
· edited 3 years agobadsectoracula 3 years ago
By now, and to be frank in the last 30 years too, this is complete and utter bollocks.
There is not one single other idea in computing that is as unbastardised as the unix philosophy - given that it's been around fifty years. Heck, Microsoft only just developed PowerShell - and if that's not Microsoft's take on the Unix philosophy, I don't know what is.
In that same time, we've vacillated between thick and thin computing (mainframes, thin clients, PCs, cloud). We've rebelled against at least four major schools of program design thought (structured, procedural, symbolic, dynamic). We've had three different database revolutions (RDBMS, NoSQL, NewSQL). We've gone from grassroots movements to corporate dominance on countless occasions (notably - the internet, IBM PCs/Wintel, Linux/FOSS, video gaming). In public perception, we've run the gamut from clerks ('60s-'70s) to boffins ('80s) to hackers ('90s) to professionals ('00s post-dotcom) to entrepreneurs/hipsters/bros ('10s "startup culture").
It's a small miracle that
iproute2only has formatting options and grep only has--color. If they feature-crept anywhere near the same pace as the rest of the computing world, they would probably be a RESTful SaaS microservice with ML-powered autosuggestions.This is because adding a new features is actually easier than trying to figure out how to do it the Unix way - often you already have the data structures in memory and the functions to manipulate them at hand, so adding a
--frobparameter that does something special with that feels trivial.GNU and their stance to ignore the Unix philosophy (AFAIK Stallman said at some point he didn't care about it) while becoming the most available set of tools for Unix systems didn't help either.
ILikeBumblebees 3 years ago
level 2· edited 3 years agoFeature creep is everywhere
No, it certainly isn't. There are tons of well-designed, single-purpose tools available for all sorts of purposes. If you live in the world of heavy, bloated GUI apps, well, that's your prerogative, and I don't begrudge you it, but just because you're not aware of alternatives doesn't mean they don't exist.
typical shell tools are choke-full of spurious additions,
What does "feature creep" even mean with respect to shell tools? If they have lots of features, but each function is well-defined and invoked separately, and still conforms to conventional syntax, uses stdio in the expected way, etc., does that make it un-Unixy? Is BusyBox bloatware because it has lots of discrete shell tools bundled into a single binary? nirreskeya 3 years ago
icantthinkofone -34 points· 3 years agoZawinski's Law :) 1 Share Report Save
More than 1 childwaivek 3 years agoThe (anti) foreword by Dennis Ritchie -
I have succumbed to the temptation you offered in your preface: I do write you off as envious malcontents and romantic keepers of memories. The systems you remember so fondly (TOPS-20, ITS, Multics, Lisp Machine, Cedar/Mesa, the Dorado) are not just out to pasture, they are fertilizing it from below.
Your judgments are not keen, they are intoxicated by metaphor. In the Preface you suffer first from heat, lice, and malnourishment, then become prisoners in a Gulag. In Chapter 1 you are in turn infected by a virus, racked by drug addiction, and addled by puffiness of the genome.
Yet your prison without coherent design continues to imprison you. How can this be, if it has no strong places? The rational prisoner exploits the weak places, creates order from chaos: instead, collectives like the FSF vindicate their jailers by building cells almost compatible with the existing ones, albeit with more features. The journalist with three undergraduate degrees from MIT, the researcher at Microsoft, and the senior scientist at Apple might volunteer a few words about the regulations of the prisons to which they have been transferred.
Your sense of the possible is in no sense pure: sometimes you want the same thing you have, but wish you had done it yourselves; other times you want something different, but can't seem to get people to use it; sometimes one wonders why you just don't shut up and tell people to buy a PC with Windows or a Mac. No Gulag or lice, just a future whose intellectual tone and interaction style is set by Sonic the Hedgehog. You claim to seek progress, but you succeed mainly in whining.
Here is my metaphor: your book is a pudding stuffed with apposite observations, many well-conceived. Like excrement, it contains enough undigested nuggets of nutrition to sustain life for some. But it is not a tasty pie: it reeks too much of contempt and of envy.
Bon appetit!
May 27, 2020 | techrights.org
...it was developed along lines that are not entirely different from Microsoft's EEE tactics -- which today I will offer a new acronym and description for:
1. Steal
2. Add Bloat
3. Original TrashedIt's difficult conceptually to "steal" Free software, because it (sort of, effectively) belongs to everyone. It's not always Public Domain -- copyleft is meant to prevent that. The only way you can "steal" free software is by taking it from everyone and restricting it again. That's like "stealing" the ocean or the sky, and putting it somewhere that people can't get to it. But this is what non-free software does. (You could also simply go against the license terms, but I doubt Stallman would go for the word "stealing" or "theft" as a first choice to describe non-compliance).
... ... ...
Again and again, Microsoft "Steals" or "Steers" the development process itself so it can gain control (pronounced: "ownership") of the software. It is a gradual process, where Microsoft has more and more influence until they dominate the project and with it, the user. This is similar to the process where cults (or drug addiction) take over people's lives, and similar to the process where narcissists interfere in the lives of others -- by staking a claim and gradually dominating the person or project.
Then they Add Bloat -- more features. GitHub is friendly to use, you don't have to care about how Git works to use it (this is true of many GitHub clones as well, as even I do not really care how Git works very much. It took a long time for someone to even drag me towards GitHub for code hosting, until they were acquired and I stopped using it) and due to its GLOBAL size, nobody can or ought to reproduce its network effects.
I understand the draw of network effects. That's why larger federated instances of code hosts are going to be more popular than smaller instances. We really need a mix -- smaller instances to be easy to host and autonomous, larger instances to draw people away from even more gigantic code silos. We can't get away from network effects (just like the War on Drugs will never work) but we can make them easier and less troublesome (or safer) to deal with.
Finally, the Original is trashed, and the SABOTage is complete. This has happened with Python against Python 2, despite protests from seasoned and professional developers, it was deliberately attempted with Systemd against not just sysvinit but ALL alternatives -- Free software acts like proprietary software when it treats the existence of alternatives as a problem to be solved. I personally never trust a project with developers as arrogant as that.
... ... ...
There's a meme about creepy vans with "FREE CANDY" painted on the side, which I took one of the photos from and edited it so that it said "FEATURES" instead. This is more or less how I feel about new features in general, given my experience with their abuse in development, marketing and the takeover of formerly good software projects.
People then accuse me of being against features, of course. As with the Dijkstra article, the real problem isn't Basic itself. The problem isn't features per se (though they do play a very key role in this problem) and I'm not really against features -- or candy, for that matter.
I'm against these things being used as bait, to entrap people in an unpleasant situation that makes escape difficult. You know, "lock-in". Don't get in the van -- don't even go NEAR the van.
Candy is nice, and some features are nice too. But we would all be better off if we could get the candy safely, and delete the creepy horrible van that comes with it. That's true whether the creepy van is GitHub, or surveillance by GIAFAM, or a Leviathan "init" system, or just breaking decades of perfectly good Python code, to try to force people to develop differently because Google or Microsoft (who both have had heavy influence over newer Python development) want to try to force you to -- all while using "free" software.
If all that makes free software "free" is the license -- (yes, it's the primary and key part, it's a necessary ingredient) then putting "free" software on GitHub shouldn't be a problem, right? Not if you're running LibreJS, at least.
In practice, "Free in license only" ignores the fact that if software is effectively free, the user is also effectively free. If free software development gets dragged into doing the bidding of non-free software companies and starts creating lock-in for the user, even if it's external or peripheral, then they simply found an effective way around the true goal of the license. They did it with Tivoisation, so we know that it's possible. They've done this in a number of ways, and they're doing it now.
If people are trying to make the user less free, and they're effectively making the user less free, maybe the license isn't an effective monolithic solution. The cost of freedom is eternal vigilance. They never said "The cost of freedom is slapping a free license on things", as far as I know. (Of course it helps). This really isn't a straw man, so much as a rebuttal to the extremely glib take on software freedom in general that permeates development communities these days.
But the benefits of Free software, free candy and new features are all meaningless, if the user isn't in control.
Don't get in the van.
"The freedom to NOT run the software, to be free to avoid vendor lock-in through appropriate modularization/encapsulation and minimized dependencies; meaning any free software can be replaced with a user's preferred alternatives (freedom 4)." – Peter Boughton
... ... ...
Sep 07, 2019 | archive.computerhistory.org
Dijkstra said he was proud to be a programmer. Unfortunately he changed his attitude completely, and I think he wrote his last computer program in the 1980s. At this conference I went to in 1967 about simulation language, Chris Strachey was going around asking everybody at the conference what was the last computer program you wrote. This was 1967. Some of the people said, "I've never written a computer program." Others would say, "Oh yeah, here's what I did last week." I asked Edsger this question when I visited him in Texas in the 90s and he said, "Don, I write programs now with pencil and paper, and I execute them in my head." He finds that a good enough discipline.
I think he was mistaken on that. He taught me a lot of things, but I really think that if he had continued... One of Dijkstra's greatest strengths was that he felt a strong sense of aesthetics, and he didn't want to compromise his notions of beauty. They were so intense that when he visited me in the 1960s, I had just come to Stanford. I remember the conversation we had. It was in the first apartment, our little rented house, before we had electricity in the house.
We were sitting there in the dark, and he was telling me how he had just learned about the specifications of the IBM System/360, and it made him so ill that his heart was actually starting to flutter.
He intensely disliked things that he didn't consider clean to work with. So I can see that he would have distaste for the languages that he had to work with on real computers. My reaction to that was to design my own language, and then make Pascal so that it would work well for me in those days. But his response was to do everything only intellectually.
So, programming.
I happened to look the other day. I wrote 35 programs in January, and 28 or 29 programs in February. These are small programs, but I have a compulsion. I love to write programs and put things into it. I think of a question that I want to answer, or I have part of my book where I want to present something. But I can't just present it by reading about it in a book. As I code it, it all becomes clear in my head. It's just the discipline. The fact that I have to translate my knowledge of this method into something that the machine is going to understand just forces me to make that crystal-clear in my head. Then I can explain it to somebody else infinitely better. The exposition is always better if I've implemented it, even though it's going to take me more time.
Sep 07, 2019 | archive.computerhistory.org
So I had a programming hat when I was outside of Cal Tech, and at Cal Tech I am a mathematician taking my grad studies. A startup company, called Green Tree Corporation because green is the color of money, came to me and said, "Don, name your price. Write compilers for us and we will take care of finding computers for you to debug them on, and assistance for you to do your work. Name your price." I said, "Oh, okay. $100,000.", assuming that this was In that era this was not quite at Bill Gate's level today, but it was sort of out there.
The guy didn't blink. He said, "Okay." I didn't really blink either. I said, "Well, I'm not going to do it. I just thought this was an impossible number."
At that point I made the decision in my life that I wasn't going to optimize my income; I was really going to do what I thought I could do for well, I don't know. If you ask me what makes me most happy, number one would be somebody saying "I learned something from you". Number two would be somebody saying "I used your software". But number infinity would be Well, no. Number infinity minus one would be "I bought your book". It's not as good as "I read your book", you know. Then there is "I bought your software"; that was not in my own personal value. So that decision came up. I kept up with the literature about compilers. The Communications of the ACM was where the action was. I also worked with people on trying to debug the ALGOL language, which had problems with it. I published a few papers, like "The Remaining Trouble Spots in ALGOL 60" was one of the papers that I worked on. I chaired a committee called "Smallgol" which was to find a subset of ALGOL that would work on small computers. I was active in programming languages.
Sep 07, 2019 | conservancy.umn.edu
Frana: You have made the comment several times that maybe 1 in 50 people have the "computer scientist's mind." Knuth: Yes. Frana: I am wondering if a large number of those people are trained professional librarians? [laughter] There is some strangeness there. But can you pinpoint what it is about the mind of the computer scientist that is....
Knuth: That is different?
Frana: What are the characteristics?
Knuth: Two things: one is the ability to deal with non-uniform structure, where you have case one, case two, case three, case four. Or that you have a model of something where the first component is integer, the next component is a Boolean, and the next component is a real number, or something like that, you know, non-uniform structure. To deal fluently with those kinds of entities, which is not typical in other branches of mathematics, is critical. And the other characteristic ability is to shift levels quickly, from looking at something in the large to looking at something in the small, and many levels in between, jumping from one level of abstraction to another. You know that, when you are adding one to some number, that you are actually getting closer to some overarching goal. These skills, being able to deal with nonuniform objects and to see through things from the top level to the bottom level, these are very essential to computer programming, it seems to me. But maybe I am fooling myself because I am too close to it.
Frana: It is the hardest thing to really understand that which you are existing within.
Knuth: Yes.
Sep 07, 2019 | conservancy.umn.edu
Knuth: I can be a writer, who tries to organize other people's ideas into some kind of a more coherent structure so that it is easier to put things together. I can see that I could be viewed as a scholar that does his best to check out sources of material, so that people get credit where it is due. And to check facts over, not just to look at the abstract of something, but to see what the methods were that did it and to fill in holes if necessary. I look at my role as being able to understand the motivations and terminology of one group of specialists and boil it down to a certain extent so that people in other parts of the field can use it. I try to listen to the theoreticians and select what they have done that is important to the programmer on the street; to remove technical jargon when possible.
But I have never been good at any kind of a role that would be making policy, or advising people on strategies, or what to do. I have always been best at refining things that are there and bringing order out of chaos. I sometimes raise new ideas that might stimulate people, but not really in a way that would be in any way controlling the flow. The only time I have ever advocated something strongly was with literate programming; but I do this always with the caveat that it works for me, not knowing if it would work for anybody else.
When I work with a system that I have created myself, I can always change it if I don't like it. But everybody who works with my system has to work with what I give them. So I am not able to judge my own stuff impartially. So anyway, I have always felt bad about if anyone says, 'Don, please forecast the future,'...
Sep 06, 2019 | archive.computerhistory.org
...I showed the second version of this design to two of my graduate students, and I said, "Okay, implement this, please, this summer. That's your summer job." I thought I had specified a language. I had to go away. I spent several weeks in China during the summer of 1977, and I had various other obligations. I assumed that when I got back from my summer trips, I would be able to play around with TeX and refine it a little bit. To my amazement, the students, who were outstanding students, had not competed [it]. They had a system that was able to do about three lines of TeX. I thought, "My goodness, what's going on? I thought these were good students." Well afterwards I changed my attitude to saying, "Boy, they accomplished a miracle."
Because going from my specification, which I thought was complete, they really had an impossible task, and they had succeeded wonderfully with it. These students, by the way, [were] Michael Plass, who has gone on to be the brains behind almost all of Xerox's Docutech software and all kind of things that are inside of typesetting devices now, and Frank Liang, one of the key people for Microsoft Word.
He did important mathematical things as well as his hyphenation methods which are quite used in all languages now. These guys were actually doing great work, but I was amazed that they couldn't do what I thought was just sort of a routine task. Then I became a programmer in earnest, where I had to do it. The reason is when you're doing programming, you have to explain something to a computer, which is dumb.
When you're writing a document for a human being to understand, the human being will look at it and nod his head and say, "Yeah, this makes sense." But then there's all kinds of ambiguities and vagueness that you don't realize until you try to put it into a computer. Then all of a sudden, almost every five minutes as you're writing the code, a question comes up that wasn't addressed in the specification. "What if this combination occurs?"
It just didn't occur to the person writing the design specification. When you're faced with implementation, a person who has been delegated this job of working from a design would have to say, "Well hmm, I don't know what the designer meant by this."
If I hadn't been in China they would've scheduled an appointment with me and stopped their programming for a day. Then they would come in at the designated hour and we would talk. They would take 15 minutes to present to me what the problem was, and then I would think about it for a while, and then I'd say, "Oh yeah, do this. " Then they would go home and they would write code for another five minutes and they'd have to schedule another appointment.
I'm probably exaggerating, but this is why I think Bob Floyd's Chiron compiler never got going. Bob worked many years on a beautiful idea for a programming language, where he designed a language called Chiron, but he never touched the programming himself. I think this was actually the reason that he had trouble with that project, because it's so hard to do the design unless you're faced with the low-level aspects of it, explaining it to a machine instead of to another person.
Forsythe, I think it was, who said, "People have said traditionally that you don't understand something until you've taught it in a class. The truth is you don't really understand something until you've taught it to a computer, until you've been able to program it." At this level, programming was absolutely important
Sep 06, 2019 | conservancy.umn.edu
Knuth: No, I stopped going to conferences. It was too discouraging. Computer programming keeps getting harder because more stuff is discovered. I can cope with learning about one new technique per day, but I can't take ten in a day all at once. So conferences are depressing; it means I have so much more work to do. If I hide myself from the truth I am much happier.
Sep 06, 2019 | archive.computerhistory.org
Knuth: This is, of course, really the story of my life, because I hope to live long enough to finish it. But I may not, because it's turned out to be such a huge project. I got married in the summer of 1961, after my first year of graduate school. My wife finished college, and I could use the money I had made -- the $5000 on the compiler -- to finance a trip to Europe for our honeymoon.
We had four months of wedded bliss in Southern California, and then a man from Addison-Wesley came to visit me and said "Don, we would like you to write a book about how to write compilers."
The more I thought about it, I decided "Oh yes, I've got this book inside of me."
I sketched out that day -- I still have the sheet of tablet paper on which I wrote -- I sketched out 12 chapters that I thought ought to be in such a book. I told Jill, my wife, "I think I'm going to write a book."
As I say, we had four months of bliss, because the rest of our marriage has all been devoted to this book. Well, we still have had happiness. But really, I wake up every morning and I still haven't finished the book. So I try to -- I have to -- organize the rest of my life around this, as one main unifying theme. The book was supposed to be about how to write a compiler. They had heard about me from one of their editorial advisors, that I knew something about how to do this. The idea appealed to me for two main reasons. One is that I did enjoy writing. In high school I had been editor of the weekly paper. In college I was editor of the science magazine, and I worked on the campus paper as copy editor. And, as I told you, I wrote the manual for that compiler that we wrote. I enjoyed writing, number one.
Also, Addison-Wesley was the people who were asking me to do this book; my favorite textbooks had been published by Addison Wesley. They had done the books that I loved the most as a student. For them to come to me and say, "Would you write a book for us?", and here I am just a secondyear gradate student -- this was a thrill.
Another very important reason at the time was that I knew that there was a great need for a book about compilers, because there were a lot of people who even in 1962 -- this was January of 1962 -- were starting to rediscover the wheel. The knowledge was out there, but it hadn't been explained. The people who had discovered it, though, were scattered all over the world and they didn't know of each other's work either, very much. I had been following it. Everybody I could think of who could write a book about compilers, as far as I could see, they would only give a piece of the fabric. They would slant it to their own view of it. There might be four people who could write about it, but they would write four different books. I could present all four of their viewpoints in what I would think was a balanced way, without any axe to grind, without slanting it towards something that I thought would be misleading to the compiler writer for the future. I considered myself as a journalist, essentially. I could be the expositor, the tech writer, that could do the job that was needed in order to take the work of these brilliant people and make it accessible to the world. That was my motivation. Now, I didn't have much time to spend on it then, I just had this page of paper with 12 chapter headings on it. That's all I could do while I'm a consultant at Burroughs and doing my graduate work. I signed a contract, but they said "We know it'll take you a while." I didn't really begin to have much time to work on it until 1963, my third year of graduate school, as I'm already finishing up on my thesis. In the summer of '62, I guess I should mention, I wrote another compiler. This was for Univac; it was a FORTRAN compiler. I spent the summer, I sold my soul to the devil, I guess you say, for three months in the summer of 1962 to write a FORTRAN compiler. I believe that the salary for that was $15,000, which was much more than an assistant professor. I think assistant professors were getting eight or nine thousand in those days.
Feigenbaum: Well, when I started in 1960 at [University of California] Berkeley, I was getting $7,600 for the nine-month year.
Knuth: Knuth: Yeah, so you see it. I got $15,000 for a summer job in 1962 writing a FORTRAN compiler. One day during that summer I was writing the part of the compiler that looks up identifiers in a hash table. The method that we used is called linear probing. Basically you take the variable name that you want to look up, you scramble it, like you square it or something like this, and that gives you a number between one and, well in those days it would have been between 1 and 1000, and then you look there. If you find it, good; if you don't find it, go to the next place and keep on going until you either get to an empty place, or you find the number you're looking for. It's called linear probing. There was a rumor that one of Professor Feller's students at Princeton had tried to figure out how fast linear probing works and was unable to succeed. This was a new thing for me. It was a case where I was doing programming, but I also had a mathematical problem that would go into my other [job]. My winter job was being a math student, my summer job was writing compilers. There was no mix. These worlds did not intersect at all in my life at that point. So I spent one day during the summer while writing the compiler looking at the mathematics of how fast does linear probing work. I got lucky, and I solved the problem. I figured out some math, and I kept two or three sheets of paper with me and I typed it up. ["Notes on 'Open' Addressing', 7/22/63] I guess that's on the internet now, because this became really the genesis of my main research work, which developed not to be working on compilers, but to be working on what they call analysis of algorithms, which is, have a computer method and find out how good is it quantitatively. I can say, if I got so many things to look up in the table, how long is linear probing going to take. It dawned on me that this was just one of many algorithms that would be important, and each one would lead to a fascinating mathematical problem. This was easily a good lifetime source of rich problems to work on. Here I am then, in the middle of 1962, writing this FORTRAN compiler, and I had one day to do the research and mathematics that changed my life for my future research trends. But now I've gotten off the topic of what your original question was.
Feigenbaum: We were talking about sort of the.. You talked about the embryo of The Art of Computing. The compiler book morphed into The Art of Computer Programming, which became a seven-volume plan.
Knuth: Exactly. Anyway, I'm working on a compiler and I'm thinking about this. But now I'm starting, after I finish this summer job, then I began to do things that were going to be relating to the book. One of the things I knew I had to have in the book was an artificial machine, because I'm writing a compiler book but machines are changing faster than I can write books. I have to have a machine that I'm totally in control of. I invented this machine called MIX, which was typical of the computers of 1962.
In 1963 I wrote a simulator for MIX so that I could write sample programs for it, and I taught a class at Caltech on how to write programs in assembly language for this hypothetical computer. Then I started writing the parts that dealt with sorting problems and searching problems, like the linear probing idea. I began to write those parts, which are part of a compiler, of the book. I had several hundred pages of notes gathering for those chapters for The Art of Computer Programming. Before I graduated, I've already done quite a bit of writing on The Art of Computer Programming.
I met George Forsythe about this time. George was the man who inspired both of us [Knuth and Feigenbaum] to come to Stanford during the '60s. George came down to Southern California for a talk, and he said, "Come up to Stanford. How about joining our faculty?" I said "Oh no, I can't do that. I just got married, and I've got to finish this book first." I said, "I think I'll finish the book next year, and then I can come up [and] start thinking about the rest of my life, but I want to get my book done before my son is born." Well, John is now 40-some years old and I'm not done with the book. Part of my lack of expertise is any good estimation procedure as to how long projects are going to take. I way underestimated how much needed to be written about in this book. Anyway, I started writing the manuscript, and I went merrily along writing pages of things that I thought really needed to be said. Of course, it didn't take long before I had started to discover a few things of my own that weren't in any of the existing literature. I did have an axe to grind. The message that I was presenting was in fact not going to be unbiased at all. It was going to be based on my own particular slant on stuff, and that original reason for why I should write the book became impossible to sustain. But the fact that I had worked on linear probing and solved the problem gave me a new unifying theme for the book. I was going to base it around this idea of analyzing algorithms, and have some quantitative ideas about how good methods were. Not just that they worked, but that they worked well: this method worked 3 times better than this method, or 3.1 times better than this method. Also, at this time I was learning mathematical techniques that I had never been taught in school. I found they were out there, but they just hadn't been emphasized openly, about how to solve problems of this kind.
So my book would also present a different kind of mathematics than was common in the curriculum at the time, that was very relevant to analysis of algorithm. I went to the publishers, I went to Addison Wesley, and said "How about changing the title of the book from 'The Art of Computer Programming' to 'The Analysis of Algorithms'." They said that will never sell; their focus group couldn't buy that one. I'm glad they stuck to the original title, although I'm also glad to see that several books have now come out called "The Analysis of Algorithms", 20 years down the line.
But in those days, The Art of Computer Programming was very important because I'm thinking of the aesthetical: the whole question of writing programs as something that has artistic aspects in all senses of the word. The one idea is "art" which means artificial, and the other "art" means fine art. All these are long stories, but I've got to cover it fairly quickly.
I've got The Art of Computer Programming started out, and I'm working on my 12 chapters. I finish a rough draft of all 12 chapters by, I think it was like 1965. I've got 3,000 pages of notes, including a very good example of what you mentioned about seeing holes in the fabric. One of the most important chapters in the book is parsing: going from somebody's algebraic formula and figuring out the structure of the formula. Just the way I had done in seventh grade finding the structure of English sentences, I had to do this with mathematical sentences.
Chapter ten is all about parsing of context-free language, [which] is what we called it at the time. I covered what people had published about context-free languages and parsing. I got to the end of the chapter and I said, well, you can combine these ideas and these ideas, and all of a sudden you get a unifying thing which goes all the way to the limit. These other ideas had sort of gone partway there. They would say "Oh, if a grammar satisfies this condition, I can do it efficiently." "If a grammar satisfies this condition, I can do it efficiently." But now, all of a sudden, I saw there was a way to say I can find the most general condition that can be done efficiently without looking ahead to the end of the sentence. That you could make a decision on the fly, reading from left to right, about the structure of the thing. That was just a natural outgrowth of seeing the different pieces of the fabric that other people had put together, and writing it into a chapter for the first time. But I felt that this general concept, well, I didn't feel that I had surrounded the concept. I knew that I had it, and I could prove it, and I could check it, but I couldn't really intuit it all in my head. I knew it was right, but it was too hard for me, really, to explain it well.
So I didn't put in The Art of Computer Programming. I thought it was beyond the scope of my book. Textbooks don't have to cover everything when you get to the harder things; then you have to go to the literature. My idea at that time [is] I'm writing this book and I'm thinking it's going to be published very soon, so any little things I discover and put in the book I didn't bother to write a paper and publish in the journal because I figure it'll be in my book pretty soon anyway. Computer science is changing so fast, my book is bound to be obsolete.
It takes a year for it to go through editing, and people drawing the illustrations, and then they have to print it and bind it and so on. I have to be a little bit ahead of the state-of-the-art if my book isn't going to be obsolete when it comes out. So I kept most of the stuff to myself that I had, these little ideas I had been coming up with. But when I got to this idea of left-to-right parsing, I said "Well here's something I don't really understand very well. I'll publish this, let other people figure out what it is, and then they can tell me what I should have said." I published that paper I believe in 1965, at the end of finishing my draft of the chapter, which didn't get as far as that story, LR(k). Well now, textbooks of computer science start with LR(k) and take off from there. But I want to give you an idea of
Nov 05, 2018 | www.amazon.com
Elegance is one of those things that can be difficult to define. I know it when I see it, but putting what I see into a terse definition is a challenge. Using the Linux diet
command, Wordnet provides one definition of elegance as, "a quality of neatness and ingenious simplicity in the solution of a problem (especially in science or mathematics); 'the simplicity and elegance of his invention.'"In the context of this book, I think that elegance is a state of beauty and simplicity in the design and working of both hardware and software. When a design is elegant,
software and hardware work better and are more efficient. The user is aided by simple, efficient, and understandable tools.Creating elegance in a technological environment is hard. It is also necessary. Elegant solutions produce elegant results and are easy to maintain and fix. Elegance does not happen by accident; you must work for it.
The quality of simplicity is a large part of technical elegance. So large, in fact that it deserves a chapter of its own, Chapter 18, "Find the Simplicity," but we do not ignore it here. This chapter discusses what it means for hardware and software to be elegant.
Yes, hardware can be elegant -- even beautiful, pleasing to the eye. Hardware that is well designed is more reliable as well. Elegant hardware solutions improve reliability'.
Sep 21, 2018 | tech.slashdot.org
Nikita Prokopov, a software programmer and author of Fira Code, a popular programming font, AnyBar, a universal status indicator, and some open-source Clojure libraries, writes :
Remember times when an OS, apps and all your data fit on a floppy? Your desktop todo app is probably written in Electron and thus has userland driver for Xbox 360 controller in it, can render 3d graphics and play audio and take photos with your web camera. A simple text chat is notorious for its load speed and memory consumption. Yes, you really have to count Slack in as a resource-heavy application. I mean, chatroom and barebones text editor, those are supposed to be two of the less demanding apps in the whole world. Welcome to 2018.
At least it works, you might say. Well, bigger doesn't imply better. Bigger means someone has lost control. Bigger means we don't know what's going on. Bigger means complexity tax, performance tax, reliability tax. This is not the norm and should not become the norm . Overweight apps should mean a red flag. They should mean run away scared. 16Gb Android phone was perfectly fine 3 years ago. Today with Android 8.1 it's barely usable because each app has become at least twice as big for no apparent reason. There are no additional functions. They are not faster or more optimized. They don't look different. They just...grow?
iPhone 4s was released with iOS 5, but can barely run iOS 9. And it's not because iOS 9 is that much superior -- it's basically the same. But their new hardware is faster, so they made software slower. Don't worry -- you got exciting new capabilities like...running the same apps with the same speed! I dunno. [...] Nobody understands anything at this point. Neither they want to. We just throw barely baked shit out there, hope for the best and call it "startup wisdom." Web pages ask you to refresh if anything goes wrong. Who has time to figure out what happened? Any web app produces a constant stream of "random" JS errors in the wild, even on compatible browsers.
[...] It just seems that nobody is interested in building quality, fast, efficient, lasting, foundational stuff anymore. Even when efficient solutions have been known for ages, we still struggle with the same problems: package management, build systems, compilers, language design, IDEs. Build systems are inherently unreliable and periodically require full clean, even though all info for invalidation is there. Nothing stops us from making build process reliable, predictable and 100% reproducible. Just nobody thinks its important. NPM has stayed in "sometimes works" state for years.
K. S. Kyosuke ( 729550 ) , Friday September 21, 2018 @11:32AM ( #57354556 )K. S. Kyosuke ( 729550 ) writes: on Friday September 21, 2018 @11:58AM ( #57354754 )Re:Why should they? ( Score: 4 , Insightful)Less resource use to accomplish the required tasks? Both in manufacturing (more chips from the same amount of manufacturing input) and in operation (less power used)?
Re:Why should they? ( Score: 2 )DontBeAMoran ( 4843879 ) writes: on Friday September 21, 2018 @12:04PM ( #57354826 )Ehm...so for example using smaller cars with better mileage to commute isn't more environmentally friendly either, according to you?https://slashdot.org/comments.pl?sid=12644750&cid=57354556#
Re:Why should they? ( Score: 2 )iPhone 4S used to be the best and could run all the applications.
Today, the same power is not sufficient because of software bloat. So you could say that all the iPhones since the iPhone 4S are devices that were created and then dumped for no reason.
It doesn't matter since we can't change the past and it doesn't matter much since improvements are slowing down so people are changing their phones less often.
Mark of the North ( 19760 ) , Friday September 21, 2018 @01:02PM ( #57355296 )Re:Why should they? ( Score: 5 , Interesting)Can you really not see the connection between inefficient software and environmental harm? All those computers running code that uses four times as much data, and four times the number crunching, as is reasonable? That excess RAM and storage has to be built as well as powered along with the CPU. Those material and electrical resources have to come from somewhere.
But the calculus changes completely when the software manufacturer hosts the software (or pays for the hosting) for their customers. Our projected AWS bill motivated our management to let me write the sort of efficient code I've been trained to write. After two years of maintaining some pretty horrible legacy code, it is a welcome change.
The big players care a great deal about efficiency when they can't outsource inefficiency to the user's computing resources.
eth1 ( 94901 ) , Friday September 21, 2018 @11:45AM ( #57354656 )Re:Why should they? ( Score: 5 , Informative)We've been trained to be a consuming society of disposable goods. The latest and greatest feature will always be more important than something that is reliable and durable for the long haul.It's not just consumer stuff.
The network team I'm a part of has been dealing with more and more frequent outages, 90% of which are due to bugs in software running our devices. These aren't fly-by-night vendors either, they're the "no one ever got fired for buying X" ones like Cisco, F5, Palo Alto, EMC, etc.
10 years ago, outages were 10% bugs, and 90% human error, now it seems to be the other way around. Everyone's chasing features, because that's what sells, so there's no time for efficiency/stability/security any more.
LucasBC ( 1138637 ) , Friday September 21, 2018 @12:05PM ( #57354836 )arglebargle_xiv ( 2212710 ) writes:Re:Why should they? ( Score: 3 , Interesting)Poor software engineering means that very capable computers are no longer capable of running modern, unnecessarily bloated software. This, in turn, leads to people having to replace computers that are otherwise working well, solely for the reason to keep up with software that requires more and more system resources for no tangible benefit. In a nutshell -- sloppy, lazy programming leads to more technology waste. That impacts the environment. I have a unique perspective in this topic. I do web development for a company that does electronics recycling. I have suffered the continued bloat in software in the tools I use (most egregiously, Adobe), and I see the impact of technological waste in the increasing amount of electronics recycling that is occurring. Ironically, I'm working at home today because my computer at the office kept stalling every time I had Photoshop and Illustrator open at the same time. A few years ago that wasn't a problem.
Re: ( Score: 3 )commodore64_love ( 1445365 ) , Friday September 21, 2018 @03:58PM ( #57356680 ) JournalThere is one place where people still produce stuff like the OP wants, and that's embedded. Not IoT wank, but real embedded, running on CPUs clocked at tens of MHz with RAM in two-digit kilobyte (not megabyte or gigabyte) quantities. And a lot of that stuff is written to very exacting standards, particularly where something like realtime control and/or safety is involved.
The one problem in this area is the endless battle with standards morons who begin each standard with an implicit "assume an infinitely
Re:Why should they? ( Score: 3 )> Poor software engineering means that very capable computers are no longer capable of running modern, unnecessarily bloated software.
Not just computers.
You can add Smart TVs, settop internet boxes, Kindles, tablets, et cetera that must be thrown-away when they become too old (say 5 years) to run the latest bloatware. Software non-engineering is causing a lot of working hardware to be landfilled, and for no good reason.
Sep 21, 2018 | tech.slashdot.org
JoeDuncan ( 874519 ) , Friday September 21, 2018 @12:58PM ( #57355276 )Obligatory ( Score: 2 )Fast, cheap (efficient) and reliable (robust, long lasting): pick 2.
roc97007 ( 608802 ) , Friday September 21, 2018 @12:16PM ( #57354946 ) JournalRe:Bloat = growth ( Score: 2 )There's probably some truth to that. And it's a sad commentary on the industry.
Sep 21, 2018 | tech.slashdot.org
Anonymous Coward , Friday September 21, 2018 @11:26AM ( #57354512 )Moore's law ( Score: 5 , Interesting)When the speed of your processor doubles every two year along with a concurrent doubling of RAM and disk space, then you can get away with bloatware.
Since Moore's law appears to have stalled since at least five years ago, it will be interesting to see if we start to see algorithm research or code optimization techniques coming to the fore again.
Nov 19, 2017 | perlmonks.com
in reply to Re: Modern Perl 4th Edition
in thread Modern Perl 4th EditionInstead, I wanted to write a book that explained the design of the language so that people could use it effectively, taking full advantage of the CPAN, and knowing enough that the copious documentation makes sense without needing a couple of semesters of computer science.The road to hell is paved with good intentions.There is such thing as the "level of abstraction." The ability to operate on various levels of abstraction and switch them at will is the talent closely associated with the software architect talent. If it is absent, the guy is just useless as a software architect and probably is a bad programmer too. You tried to remove all, even existing, links to the lower levels of abstraction (for example, by choosing to cover Moose and avoiding old school "bolted on" Perl OO mechanisms). IMHO that creates the "house of cards" situation. I think that's a dangerous strategy.
My position is that a competent Perl programmer needs to know and strive to learn some C, and should have some genuine interest (at least on the superficial level) on how various Perl constructs are mapped in memory, how Perl interpreter symbol tables are organized and how they are linked to the notion of namespaces, and how garbage collection works. IMHO it is challenging to learn Perl to sufficient depth staying on "pure Perl" level. As a minimum, the person should learn well Perl debugger in addition to the language. From this point of view features that are not well represented in Perl debugger should be avoided. So complete novices, who try to learn Perl "without needing a couple of semesters of computer science," probably should use Minimal Perl book by Tim Maher and stay away from yours.
So I see a problem with a high level "pure Perl" approach, which is what your book is about. There is little coverage of "Perl ecosystem" outside CPAN in your book. Lip service is not enough. There is no chapter about Perl debugger. There is no chapter about Perl ability to call C.
And that's why I think coverage of the "classic" text manipulation functions is important. They represent a lower level of abstraction than regex (and historically they are older than regex; I think substr , index and tr were first defined in PL/1 around 1964; regex history started around 1968.). So coverage of both means adherence to Perl slogan "There's more than one way to do it" and coverage of only one is a betrayal of this slogan. As simple as that.
I think that various levels of abstraction need to coexist in the same language. And that's why I like Perl. But "my Perl" is not the language I have found in your book. Yours is a different Perl.
While the higher level of abstraction represents the progress of the language, that does not obviate the need for the features that exist on the lower level of abstraction. You need to give people a choice, not to corral them into the highest level of abstraction available.
In this sense, the ability to use small C fragments in Perl (see the discussion at XS Library - Embedding C code in Perl ), the good understanding of classing string functions as an alternative to regex (Perl, after all, is a great text processing language), etc., are so important and, as such, represent Perl advantages. Classic Perl slogan "There's more than one way to do it" should be interpreted as "There's more than one way to do it on different levels of abstractions." IMHO.
For example, Moose does provide the higher level of abstraction of OO than the "old school" Perl5 "bolted on" OO solution. But the question arises whether the advantages justify the cost and learning curve, as well as how much of it is the pure "syntax sugar" and how much is the "meat." The fact that "Moose is more smooth" does not make it inherently superior. All depends on your needs as a programmer.
The ability to see the OO "Kitchen," even if it is dirty, is also a valuable feature. Especially for students. That's a positive feature of "old school" Perl OO in comparison with Ruby and Python: it does provide access to lower levels of abstraction for OO. People are smart enough to choose what is best for them. But that means that it might be beneficial to cover both in a reference book. I, for example, will not approach Moose, unless I need to maintain somebody else code that uses it.
While creating the higher level of abstraction is the name of the game (and that's why Perl became popular), a "reckless" drive to higher levels of questionable abstractions can be self-defeating. That's what I mean by my "house of cards" analogy.
Many people resent being in the situation when they need to catch a black cat in a dark room (when internals of a complex feature are completely hidden), all those artificial examples of "complexity aficionados" advertising those features in their books notwithstanding. And in such cases, programmers either abandon the language and use a lower level one (for example descending from Python to Java) or just use a more simple subset avoiding 'extra" features with "extra" complexity. That's the reality of the situation as I see it.
That's why when you can't do something via regex or can't figure out how particular feature of Perl regex implementation works or why it works in such a way, programming using index and substr often the best and quickest alternative solution. The solution that, as I have found, works "well enough" even in cases were regex looks "the thing to use." KISS principle is about being simple, not about the most compact solution of a given problem (although it also has great value, if not taken to extremes).
Your attitude "eliding mention of closures would mean there's no good way to explain grep, sort, or map or even lexical scope" is wrong and IMHO is the attitude of a "complexity junkie." Yes, you can explain closures using map or grep as examples where this notion is potentially useful, but not the other way around. You need to repent ;-)
And please do not try to shoot the messenger. I know that writing a book is a very demanding, and not very rewarding occupation, with unfair criticism being one of the hazards of trade, and I commend you for publishing the "Modern Perl." Please consider my critique as the set of recommendations on how to improve it in future editions.
Nov 01, 2008 | IEEE Software, pp.18-19
As I write this column, I'm in the middle of two summer projects; with luck, they'll both be finished by the time you read it.
- One involves a forensic analysis of over 100,000 lines of old C and assembly code from about 1990, and I have to work on Windows XP.
- The other is a hack to translate code written in weird language L1 into weird language L2 with a program written in scripting language L3, where none of the L's even existed in 1990; this one uses Linux. Thus it's perhaps a bit surprising that I find myself relying on much the same toolset for these very different tasks.
... ... ...
Here has surely been much progress in tools over the 25 years that IEEE Software has been around, and I wouldn't want to go back in time.
But the tools I use today are mostly the same old ones-grep, diff, sort, awk, and friends. This might well mean that I'm a dinosaur stuck in the past.
On the other hand, when it comes to doing simple things quickly, I can often have the job done while experts are still waiting for their IDE to start up. Sometimes the old ways are best, and they're certainly worth knowing well
Simplicity is the core of a good infrastructureI've seen many infrastructures in my day. I work for a company with a very complicated infrastructure now. They've got a dev/stage/prod environment for every product (and they've got many of them). Trust is not a word spoken lightly here. There is no 'trust' for even sysadmins (I've been working here for 7 months now and still don't have production sudo access). Developers constantly complain about not having the access that they need to do their jobs and there are multiple failures a week that can only be fixed by a small handful of people that know the (very complex) systems in place. Not only that, but in order to save work, they've used every cutting-edge piece of software that they can get their hands on (mainly to learn it so they can put it on their resume, I assume), but this causes more complexity that only a handful of people can manage. As a result of this the site uptime is (on a good month) 3 nines at best.
In my last position (pronto.com) I put together an infrastructure that any idiot could maintain. I used unmanaged switches behind a load-balancer/firewall and a few VPNs around to the different sites. It was simple. It had very little complexity, and a new sysadmin could take over in a very short time if I were to be hit by a bus. A single person could run the network and servers and if the documentation was lost, a new sysadmin could figure it out without much trouble.
Over time, I handed off my ownership of many of the Infrastructure components to other people in the operations group and of course, complexity took over. We ended up with a multi-tier network with bunches of VLANs and complexity that could only be understood with charts, documentation and a CCNA. Now the team is 4+ people and if something happens, people run around like chickens with their heads cut off not knowing what to do or who to contact when something goes wrong.
Complexity kills productivity. Security is inversely proportionate to usability. Keep it simple, stupid. These are all rules to live by in my book.
Downtimes: Beatport: not unlikely to have 1-2 hours downtime for the main site per month. Pronto: several 10-15 minute outages a year Pronto (under my supervision): a few seconds a month (mostly human error though, no mechanical failure)
Ok, rant over. :)
Oct 18, 2010 | The Oil Drum Campfire
This is a guest post by Cameron Leckie, known on The Oil Drum as leckos. Cameron is an officer in the Australian army. He is a member of ASPO Australia and lives in Brisbane with his wife and two young children.
The other day, whilst visiting the in-laws, I was involved in a conversation that in my view opened a window to the future of technology. My mother in law, who works in a small retail outlet was packing her lunch. My wife asked why she was putting an ice block in with her lunch box. The answer was that the owner of the shop had removed the staff refrigerator (and turned off the hot water system) to save a couple of hundred dollars a year. As someone who strongly believes that the most likely outcome for a debt based economic system approaching a world of declining net energy supplies is economic contraction and lower standards of living (at least materially), this started me thinking about the process by which industrial civilisation may abandon some of the technologies that we currently take for granted.
There are many reasons why we humans adopt new technologies, but in my view the root cause is that the benefit provided by a new technology outweighs its cost. Importantly costs and benefits can be measured both in financial terms and by other less tangible factors, something that will be important when considering which technologies are abandoned. One reason that we may abandon a technology is the flip side of the reason for its adoption - that the costs outweigh the benefits obtained. Thus the fridge has been abandoned because the cost of maintaining it outweighs the benefit of keeping lunch cold. Other reasons might be that the technology is no longer supportable (for example, If you cannot access fuel, your car is not going anywhere) or another technology appears/reappears to replace it.
In this post, I would like to propose a theory by which some, or potentially many, modern technologies could be abandoned. This is an important issue because of its implications for government policy, business investment and of course society as a whole. I will briefly examine the relationship between technology and complexity, detail a theory to explain how technologies might be abandoned and finally propose some questions for discussion.
Technology and complexity
Virtually all technologies increase the complexity of the organisation/society that adopts the technology. Whilst to the end user a new technology might appear simpler, from a systems perspective, complexity has increased. Consider a hunter gatherer versus a modern consumer's procuring of food. The hunter gather had to work much harder to obtain and prepare food than the modern consumer reliant upon supermarkets and pre-prepared food. The system required to support our food system however is orders of magnitude more complex than that of a hunter gatherer. This increased level of complexity comes at a cost in terms of the capital, resources and energy required to maintain a level of complexity.
For example, to maintain our road networks requires significant financial and human capital, a vast array of equipment, and resources such as sand, gravel, bitumen, steel, aluminium and concrete. This is all supported by the expenditure of energy, such as diesel and electricity. Whilst the global economy has grown meeting these maintenance costs has been in the most part achievable. It is highly unlikely however that society will be able to meet these maintenance costs in a contracting economy. Indeed this is already occurring in some parts of the world, such as the US, where in some instances financially pressured local governments have been turning bitumen roads into gravel roads to reduce costs.
The theory
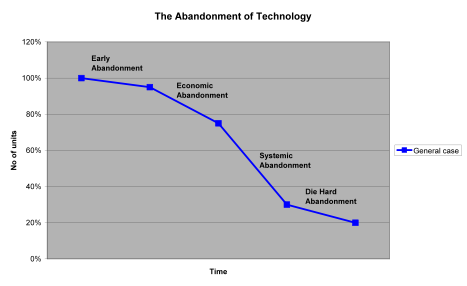
So how could a technology be abandoned? Figure 1 summarises the theory that I am proposing. Figure 1 represents a single technology, such as a car. Rather than using a specific number of units (e.g. cars) or other measures (e.g. Vehicle Kilometres Travelled), I have used percentages to represent the level of abandonment, with 100% representing the maximum uptake of a particular technology and 0% being its complete abandonment. Obviously how individual technologies are abandoned will vary considerably both in time and level of abandonment, thus the general case represented in Figure 1 is generic only to assist with explaining the theory.
Figure 1. The abandonment of technology. General case. In the general case, technology is abandoned in four stages:
Early abandonment. During this phase a small number of people abandon a technology for a number of reasons. These could be altruistic (selling the second refrigerator because of concerns over climate change), frugality (trying to save a little extra money) or economic (long term unemployment). Whilst some of these reasons will recur in later stages, the early abandoners will be small in numbers, the actual abandonment won't cause major inconveniences to the people who decide to do so, the technologies are likely to be discretionary use items and the effects of this abandonment are likely to only have minor impacts upon the industries associated with that technology.
An example might be provided by the home telephone. With the proliferation of mobile telephone services and attractive contracts, some people might decide to close their home telephone service and instead rely upon mobile phones. I know a number of people who have done this already and have even considered it myself as a means of reducing living expenses.
- Economic abandonment. The transition from the relatively painless stage of early abandonment to this stage is likely to coincide with a financial crisis or economic recession. Unemployment, increased costs of living and reduced incomes will force tough decisions to be made resulting in abandoning or significantly reducing the use of technologies. Discretionary items are likely to be the first to go, but over time, items more and more fundamental to our current lifestyles will be abandoned. This stage will be characterised by major falls in sales. It is likely to be widespread, at least regionally or nationally and the items that are abandoned will have increasingly greater impacts.
During this stage the item of technology will still be supported, that is the industries supporting the technology will still function. An example might be provided by cars. Sustained high oil prices combined with other economic factors are likely to result in significantly less travel by car; however there will still be an automotive industry. This stage is likely to last for some time, potentially decades depending upon the technology.
- Systemic abandonment. This stage is defined by a technology being abandoned because it can no longer be supported or maintained, at least on a wide scale. The reasons that this could occur are many such as the unavailability of parts due to business failures/supply chain disruptions, a credit freeze, oil supply disruptions or an unreliable electrical supply. This stage is characterised by the physical inability to support a technology on a reliable basis. This stage could have global impacts and occur quite quickly due to synchronous failure. For example if Boeing, or Airbus, were to fail, this would have significant implications for airlines globally.
- Die hard abandonment. The final stage of abandonment is likely to be the longest. Some technologies might disappear completely whilst others may last for decades or centuries. The use of a technology during this phase is likely to be isolated and dependent upon local circumstances. For example, you would expect that Saudi Arabia will have cars on the road far longer than an oil importing nation. Smaller numbers of a technology may also be maintained through the cannibalisation of parts or local manufacture. This stage is likely to be highly uneven between regions and different types of technologies. For example, maintaining mechanical items is likely to be more achievable than sophisticated electronic items.
Some general comments on the theory. Although this is explained in a linear fashion, the transition between stages is likely to overlap and could even occur concurrently between different regions or nations. Indeed some nations might be increasing the uptake of a technology at the same time another nation is abandoning it.
Also, it is not necessarily a one way process; it is likely to be dynamic. All that it will take to reverse the process is for the cost benefit analysis to alter direction, assuming that a technology is still supportable. In many industries we are likely to have major over capacity problems in the years ahead as the global economy contracts. Economic and systemic abandonment, whilst likely to be highly disruptive, may result in some technologies being able to remain viable for much longer as excess capacity is removed.
Finally synchronous failure, to use Thomas Homer-Dixon's phrase, could rapidly accelerate this process due to the interdependencies between many technologies. As an example, if the US Air Forces Global Positioning System constellation were to fail, this could render a whole host of technologies that rely upon it immediately useless.
Questions
The key assumption that underpins this theory is that the future path of the global economy will be one of contraction. Taken in this context, detailed below are some questions for discussion on the theory of technological abandonment:
- Is this theory valid? If not, are there other ways of describing how we might abandon technology?
- Is there any evidence, anecdotal or otherwise, available to support this theory?
- What technologies are most at risk?
- What technologies should we attempt to maintain? What are the priorities?
- What role should Governments take?
- Where should we be focusing investment and R&D budgets?
- What characteristics should future technologies embody?
- What are the implications for manufacturers and business?
- What opportunities does the realisation of this theory present?
- Should/could we abandon at risk technologies prematurely?
- What do we do with the remnants of the technologies that we abandon?
Author's Note
This campfire post is an extension of my thoughts on the future of technology explained in a paper that has recently been published in the Australian Defence Force Journal titled 'Lasers or Longbows: A paradox of military technology' (from page 44). The paradox I define in the paper as being 'The advantage provided by the increased complexity of a military capability increases the vulnerability of that same capability to systemic collapse due to its reliance on complex supply chains.' Whilst this paper was describing the impact on the military, I believe that it is equally relevant to all technologies. This post expands upon the argument presented in the paper to examine how individual technologies may be abandoned.
297 comments on The Abandonment of Technology
David Sucher on October 16, 2010 - 3:36pm Permalink | Subthread | Comments top
I don't believe that it makes sense that we in the USA have been abandoning our roads because it relates to overall peak oil etc., as you say here:
"Indeed this is already occurring in some parts of the world, such as the US, where in some instances financially pressured local governments have been turning bitumen roads into gravel roads to reduce costs."
We simply have not been spending our money wisely. One reason that the USA is not spending money to maintain its infrastructure simply because the USA has such idiotic foreign policy and we spend too much on "defense" spending. Consider the many many billions if the USA wasn't so lacking in astuteness.
Yeah, transport is really the sector that will change. There is plenty of electricity available. Peak oil is about . . . well, oil. Between coal, natural gas, nuclear power, solar, and wind; there will be plenty of electricity for my lifetime and my child's lifetime.
We must keep in mind that there are considerable interdependencies between all sectors of critical infrastructure. With high oil prices come economic uncertainty, and low budgets for roads, which are expensive to maintain due to the high bitumen costs. Lack of road maintenance impacts almost every other sector - these supply chain risks are already being examined;
Critical Infrastructure Interdependencies from the National Infrastructure Simulation and Analysis CenterIf we look at the impacts of road disruptions in specific areas over time;
If we take just a peek at some of the details in the Communications sector alone, we'll see how delicate our current (chaotic) system really is;
Just like the climate, we don't know exactly what will happen when the system is perturbed in any number of ways, so something as complex as our critical infrastructure must be modeled;
We are being supported by an n-dimensional house of cards. Pull one lower card out and...
Does complexity unwind the same way built up through progressive transformations?
I'd say that simplification of a complex system can only be achieved through progressive transformations. Unless of course you have a catastrophic failure of the system in which case I wouldn't call it a mere 'simplification' process. However that simplification process will not likely be a straight forward reversal of the process that originally led to the existence of the complex system.
All one has to do is think of the increasing complexity over time that a fertilized egg must undergo so that it eventually becomes, say, a highly accomplished neuroscientist... and compare that process to the cascade of organ failures the leads to his or her death followed by the decomposition of the body.
WHT's inadvertently coined word 'Entrophy' might be a good way to describe the later.
Entrophy being an amalgamation of the words Entropy and Eutrophication.If one could obtain data with which to graph the delta 'Entrophy' from the moment of the first cellular disruption leading to the series of organ failures that would eventually cause the cascade of failing organs, one should be able to obtain momentary snapshots of the simplification process (decreasing complexity) in action along a chosen timeline.
I believe the same picture can be obtained for any complex system undergoing an 'Enthrophic' process, even our complex industrialized civilization which is IMHO now undergoing it's first cellular disruptions due to declining energy sources and diminishing resources. This particular oil candle has burned exceedingly brightly by having been lit at both ends.
Here's your analogy of the highly accomplished neuro-scientist, pictured below in terms of transformities. But to equate the physical DNA, the cells of his liver with the legacy of his work (books, medical knowledge that then gets passed on, and other cultural DNA) is mixing two different streams of transformity. The physical stream of DNA and cells is what makes us mammals as part of the food chain. The information stream is many exponents greater in terms of transformation, and it is what makes the human culture so amazing. The body dies, but the legacy lives on within the culture, as does the DNA of the neuroscientist, if propagated? The failure of both streams of transformation may occur at drastically different rates. Cultural DNA is arguably just as valuable as genetic DNA, but on a different, shorter time scale, but with massive embodied energy from our FF culture?
So far there is no question of abandoning any technology, or of being forced by cost to abandon any real capability.
I'm not quite sure that's true. Many military technologies have been abandoned - like big gun battleships, sail power, and coal power
In most military situations it is not because of cost that they are abandoned, but because they are rendered obsolete (e.g. coal) or ineffective (battleships).There is a recent example of cost abandonment - the US Navy used to have some nuclear powered cruisers, which are more operationally capable than conventional ones, but were "abandoned" )i.e. not replaced) for cost reasons. The nuke cruiser concept was refloated, and re-abandoned, as recently as this year.
http://www.fas.org/sgp/crs/weapons/RL33946.pdf
I can think of no better example of an increase in capability (i.e. "infinite" range), for a massive increase in complexity. For large ships (carriers) and submarines, it clearly makes sense, for small ones it does not - the cruisers are clearly near the crossover point.
mcain6925 on October 17, 2010 - 3:58am
...but because they are rendered obsolete (e.g. coal)...
Following the oil price spike at the end of the 1970s, there was some consideration given to the possibility of building new coal-fired steamships. At least one, the SS Energy Independence, a small bulk freighter, was actually built. The thinking was that improvements in boiler design and automation of fuel handling developed by the electric generating industry appeared to make such ships feasible. There were a whole list of practical problems that would have had to be solved, such as contemporary ports lack of infrastructure for handling coal fuel. At some level, coal is "obsolete" only as long as you have oil.
robert wilson on October 16, 2010 - 4:44pm
A remarkable book that discusses the complexity of modern medicine is The Checklist Manifesto by Atul Gawande. Complexity is one of the drivers for rising medical expenses. For decades I have been astonished by the progress seen in nuclear medicine, digital radiography, computed tomography, PET and especially MRI and fMRI (magic resonance imaging?). Although I have recently benefited from the service of a super specialist, a certified cardiologist with a sub-specialty in cardiac electrophysiology, I doubt that increasing medical complexity is sustainable. In coming decades society may be forced into acceptance of simpler medical care.
Alaska_geo on October 17, 2010 - 11:50am
Gawande's Checklist Manifesto is indeed a most excellent book. It has many insights that go well beyond medicine. I highly recommend it.
daxr on October 17, 2010 - 7:30pm
Just for fun:
http://www.newsweek.com/photo/2010/08/24/dumb-things-americans-believe.html
The truly scary thing is how easy it seems to be to get people to believe ridiculous crap...in an autocracy it doesn't make much difference how stupid the populace is, but in a democracy everything tends to get dragged down toward the lowest common denominator.
That may be true but I think there is much more to it than that.
1. 7 billion people competing for a shrinking pie (in all areas - energy, metals, fresh water, etc.) is a very different context than the Middle Ages/Dark Ages
2. it's very possible (likely?) that we will see the rollback of The Enlightenment in many areas of the world that have it now.Even with a broadly available public education system, the best the U.S. has gotten to is this:
Half of all Americans believe they are protected by guardian angels, one-fifth say they've heard God speak to them, one-quarter say they have witnessed miraculous healings, 16 percent say they've received one and 8 percent say they pray in tongues, according to a survey released Thursday by Baylor University.
http://www.washingtontimes.com/news/2008/sep/19/half-of-americans-believ...
It's not just technology...it's the whole of society that will regress.
Nick on October 18, 2010 - 12:41pm
That's something that has amazed me for years.
People like to believe that the rich/elite gather in conspiracies which know everything. In fact, the rich/elite believe their own propaganda, and often end up far stupider than can be believed.
Merrill on October 16, 2010 - 4:24pm
Most examples of "abandonment" are really "replacements". New technologies which are better, easier, and cheaper replace old ones (though the "cheaper" part doesn't matter much for military technology).
Audio recording has gone through mechanical recording on Edison cylinders, 78, 45 and 33-1/3 discs, magnetic recording on wire, 1/4" reel-to-reel, 8-track cartridge, Philips cassette, optical recording on CDs, and media-independent computer files, such as MP3s. Of these only the 33-1/2 vinyl records, CDs, and computer files survive in any volume.
However, the audio recording technologies are all replacements. As was the replacement of black powder by smokeless powder, matchlocks by flintlocks by percussion caps by cartridges, wooden ships by iron hulls by steel hulls, etc. It wasn't that the supply of vinyl or saltpeter or flint or wood ran out.
Abandonment of a technology because a factor needed for its production or operation is pretty rare.
I think that in some cases irrigated agriculture has been abandoned when water supplies became too meager to sustain it. However, in most cases irrigation had been abandoned when the soil becomes to alkaline or salty for further irrigation, which is a different type of failure.
Carving of ivory objects or objects made from rhinocerous horn might be an example. I can't think of a mineral or a plant substance that has become totally unavailable, but several animals have become endangered or extinct. Market hunting of passenger pigeons and other game birds is no longer done. Beaver hat making has been abandoned.
half full on October 16, 2010 - 6:36pm
Yes. Replacement, not abandonment, will be the significant trend. Those technologies most directly associated with coal, oil, and gas will be replaced with those for capture, storage, transformation, and utilization of solar energy. Our current technology materials mix is coloured by our use of carbon as a metallurgical reductant and petrochemicals as polymer feedstocks. Solar electricity used in electo-metallurgy will result in greater use of metals like magnesium, titanium, manganese and aluminum (which are hard to reduce with carbon), and biomass feedstocks will be useful for a wider variety of 'designer' polymers.
There is no reason why secondary industries like manufacture of refrigerators should be affected beyond materials choices.
If i were an Australian i would be mindful of the fact that enough solar energy could be captured in the outback to power most of the world. That resource should identified as something of strategic importance and defended. Solar technologies are not ready yet, but will be long before the last of the fossil fuels are gone.
pancake on October 17, 2010 - 12:25am
Most examples of "abandonment" are really "replacements". New technologies which are better, easier, and cheaper replace old ones (though the "cheaper" part doesn't matter much for military technology).
What if the replacement technology does not make your life easier. Does that count as an "abandonment" are a "replacement"?
Old-fashioned washing machineMartian on October 17, 2010 - 1:46pm
Sorry, but your example is not quite right. Look at what is there in the video.
Plastic Bucket?
Vitreous China sink?
Modern detergents?
Michelle Obama? (just kidding)
Where did the water come from?
And many more...This is a very poorly designed use of a very basic technology. Kinda like pushing a rope. Reminds me of a bicycle with square wheels.......
Most technology today, and for the last 50 years, is nothing more than mental masterbation.
Technology for technologies sake....a Child's Merry-go-round to nothing.jokuhl on October 17, 2010 - 3:23pm
I'm wondering what you're referring to with recent tech..
There is a lot of junk, but the core advancement they are built on, Microprocessors, for example, have proven to be highly adaptable and useful in real ways as well.
I remember doing corporate videos 15 years back, and noting all the different applications I was seeing 'old' IBM AT's and PC's still being used for, from CAD-CAM app's to Making T-shirts, to Trading, Bookkeeping, Desktop Publishing, DataLogging, etc.. with programs and interfaces that could largely be installed from the Screenprinter's machine onto the Trader's machine and be expected to run just fine. Even if the products they were creating were unnecessary or built on the 'Overconsumption Model', that doesn't mean that the flexibility of this technology was at fault.. and Now, I've got a handheld from HP in 1995 that can run any program that an old IBM 8086 or 286 would run, powered by a pair of AA batteries. There are all sorts of useful and meaningful ways such tech could still be put to use for localized groups.
Nick on October 18, 2010 - 1:13pm
all the different applications I was seeing 'old' IBM AT's and PC's still being used for
The most striking example for me was the space shuttle, powered by the original PC-XT 8086 processor!
jokuhl on October 19, 2010 - 4:38am
Which brings to mind this old internet gem.. of the dependence of Modern Tech on the Ancients.
THE SPACE SHUTTLE AND ROMAN CHARIOTS
Does the statement, "We've always done it like that" ring any bells?
The US standard railroad gauge (distance between the rails) is 4 feet, 8.5 inches. That's an exceedingly odd number. Why was that gauge used?
Because that's the way they built them in England , and English expatriates built the US Railroads.
Why did the English build them like that?
Because the first rail lines were built by the same people who built the pre-railroad tramways, and that's the gauge they used.
Why did "they" use that gauge then?
Because the people who built the tramways used the same jigs and tools that they used for building wagons, which used that wheel spacing.
Okay! Why did the wagons have that particular odd wheel spacing?
Well, if they tried to use any other spacing, the wagon wheels would break on some of the old, long distance roads in England , because that's the spacing of the wheel ruts.
So who built those old rutted roads?
Imperial Rome built the first long distance roads in Europe (and England ) for their legions. The roads have been used ever since.
And the ruts in the roads?
Roman war chariots formed the initial ruts, which everyone else had to match for fear of destroying their wagon wheels. Since the chariots were made for Imperial Rome , they were all alike in the matter of wheel spacing.
The United States standard railroad gauge of 4 feet, 8.5 inches is derived from the original specifications for an Imperial Roman war chariot. And bureaucracies live forever.
So the next time you are handed a specification and wonder what horse's ass came up with it, you may be exactly right, because the Imperial Roman army chariots were made just wide enough to accommodate the back ends of two war horses!
Now, the twist to the story
When you see a Space Shuttle sitting on its launch pad, there are two big booster rockets attached to the sides of the main fuel tank. These are solid rocket boosters, or SRBs.
The SRBs are made by Thiokol at their factory at Utah . The engineers who designed the SRBs would have preferred to make them a bit fatter, but the SRBs had to be shipped by train from the factory to the launch site.
The railroad line from the factory happens to run through a tunnel in the mountains.
The SRBs had to fit through that tunnel.The tunnel is slightly wider than the railroad track, and the railroad track, as you now know, is about as wide as two horses' behinds.
So, a major Space Shuttle design feature of what is arguably the world's most advanced transportation system was determined over two thousand years ago by the width of a horse's butt.
SNOPES demurs on this one a bit, but gives it some credit here and there.
http://www.snopes.com/history/american/gauge.aspjoule on October 16, 2010 - 4:25pm
Leckos -
I think your theory is quite reasonable at least as a broad generalization. However, technology is a very nebulous subject, and the very term 'technology' often connotes different things to different people. Even the dictionary offers several different definitions of technology, none of which are terribly helpful, to wit: i) the study, development, and application of devices, machines, and techniques for manufacturing and productive processes, ii) a method of methodology that applies technical knowledge or tools, iii) the sum of a society's or culture's practical knowledge, especially with reference to its material culture.
Note that none of these definitions talk about specific products as being 'technology', and I think that's where some people get into trouble when using the term technology too loosely. If I drive a monstrous Ford pick-up truck while you drive a small, fuel-efficient Smart Car, we are both using automotive technology but in the form of vastly different products. However, if I go to a bicycle, then that is switch to a different technology. If the modern Australian Air Force flies jets while the WW II RAF flew piston-engined planes, they were both using aviation technology, but vastly different propulsion technologies. One often encounters this conflating of technology with products in technical advertising. A company with a new line of water filters will boast about their new 'technology' when in actuality it is nothing more than a new product based on fundamental filtration technology, and thus really just a different embodiment of an existing technology.
My purpose here is not semantical nit-picking, but rather to point out that technology and products are not the same thing. And I think much of what you call 'abandonment of technology' is often just a case of restricting or limiting the application of products based on that technology. In the example of your mother-in-law's boss who removed the employee's refrigerator, he was not abandoning refrigeration technology, but rather was stingily restricting access to a particular product based on that technology. I'm sure the boss still maintain a nice refrigerator in his own home. But if we replace a coal-fired power plant with a wind farm or solar array, then that is clear an abandonment of one technology and the taking up of another technology.
Then we have the problem of complexity, which can also be somewhat in the eye of the beholder, as illustrated by the following question: which is more complex a classic steam locomotive or a modern diesel-electric locomotive? The answer is not as obvious as it looks. While the steam locomotive uses lower-tech coal instead of higher-tech petroleum (and the vast infrastructure associated with such), it is a plumbing nightmare, far more complex in operation, and requires far more complex maintenance. An external combustion engine is inherently more complex and inefficient than an internal combustion engine, even though it came first. So, one might argue that this forward step in technology, i.e. going from steam to diesel, actually reduced rather than increased complexity. Ditto for going from vacuum tube to solid state electronics.
And lastly, many people tend to view individual technologies in a vacuum and don't fully appreciate the extent to which one technology is dependent upon many others, with economics being the main driving force. If I can no longer drive my car because a whole chain of parts suppliers have gone bankrupt and I can no longer get replacement parts, it's not that I have abandoned automotive technology, but rather that a systemic failure of infrastructure has occurred.
I prefer to view what you're talking about as products being abandoned due to economic and infrastructure problems, rather than abandonment of technologies, per se. Regardless of which way one wants to phrase it, you are on the right track, and the technological landscape of the future will not necessarily be more advanced than that of the present, as what has been viewed as 'progress' often turns out to not be progress after all. For things to work, the technological mix must be appropriate and fit the set of circumstances under which we live. However, I fear this will never happen in an ordered and painless way, and we will largely keep doing what we're doing until we can't.
RickM on October 16, 2010 - 5:49pm
I agree, Joule:
Cam is on the right track, and we humans tend to keep doing what we're doing until we can't.
That truism applies not only to beneficial behavioural patterns (I automatically get out of bed, shower and go to work each morning, all of which has benefits) but also to all sorts of vices (smoking, drinking, junk food, wasting time on the internet, even thievery... people often must be forced in some way before they will stop).Many Ontario farms have a spot in the trees where a half-century ago, the farmer dragged off his horse-drawn equipment: seed drills, wagons, two-furrow riding plows, etc. They did so, often reluctantly, trusting that gasoline (and eventually diesel) tractors would prove superior to live horsepower. Many farmers bought a tractor but still kept the horses "just in case," and sometimes that paid off.
But I think your distinction between abandonment for economic & infrastructure reasons (vs abandoning the technology itself) sort of parallels the debate over what will prove to be the "cause" of peak oil: what 'causes' it will matter far less than the fact that it has occurred, and the result may be pretty much the same.
I do agree that a person may not abandon the technology on some emotional level (a power failure in no way diminishes my appreciation of my computer, even though it's completely useless for a while) but we may be forced into it because of infrastructure problems (what if the grid became unstable and we had occasional voltage surges which damaged our expensive electronics?). Or financial hardship may force us to give up something which we certainly have no desire to abandon (as you correctly pointed out).
In any event the infrastructure really can't be meaningfully isolated from the technology, since the technology can't really operate effectively without it, just as the infra would not exist were it not for the technology.
But the fear here is the vulnerability which is inherent in the interconnectedness and the complexity of both our technologies and their attendant infrastructures, including the economic and fiscal systems which support them.
And that is, I think, the central message of the recent Bundeswehr report on peak oil: oil is so fundamental to our mobility, our supply chains for food and everything else, our jobs and the tax base, military capabilities, etc... anything which interferes with our large-scale access to affordable oil could very quickly put us outside that narrow band of economic and social stability.
The Bundeswehr report is unprecedented in the publicly-available military literature for that reason: instead of focusing on the usual set of concerns, most of which are external (choke-points, NOCs, resource wars, geopolitics, Chindian demand, etc) this report has flagged the potential for economic, social and even technological unraveling on the home front.
As the Amish continue to prove, there is great resiliency in technologies and an infrastructure which are under one's own direct control. They are the classic example of a society which thinks long & hard before it decides to change its technologies or its infrastructure. (Some of us make such changes in an eye-blink, following the latest commercial, with no real thought.)
The Amish (and many other farmers) just have to pray that the rest of society will leave them alone when the flashy, consumptive lifestyle which many of us have chosen runs into trouble, which probably won't take too long....
vertigo on October 16, 2010 - 8:52pm
Just a note re. the Amish saving us. I come from a Mennonite family that used buggies long after everyone else was in cars. That society was dependent on having large families to provide the farm labor; my grandmother was one of ten. Overpopulation was prevented by exporting the excess into the surrounding communities, so my grandmother stopped that lifestyle and became modernized, along with many of her siblings and most of their descendents. Without high birth rates, the Amish/Mennonite system is not going to work too well.
geek7 on October 16, 2010 - 6:15pm
This redirection away from the word technology and towards the word product seems a good idea to me. Actually, I had been thinking of posting some thoughts about renaming the target of discussion as modern behaviors which will be abandoned. And I'm inclined to believe that still has merit.
When I started feeling uncomfortable with the abandonment of technology as a topic, the behavior that first came to mind, for me, was the phenomenon of world leaders gathering in person at the United Nations building in New York on a annual basis. Although the cost of this trip is a trivial burden on USA for our President, there are other nations for which it must be a difficult burden, or a source of corrupt influence on the leadership by foreign business interests. This is an example of a topic which doesn't fit well with either technology or product, but belongs somewhere in a discussion of what the future might bring. But for now, lets concentrate on technology.
For a technology to exist, there must be a sub-set of the population who count themselves as being experts in that technology. These people must maintain their skills and must recruit and train their replacements before they retire (or die). So every technology has a base level of cost even if it is very little used. And every technology also seems to depend on other technologies to some extent. So for a technology to survive, its supplier technologies must also survive. There was a time when an economist (Leontief) tried to create a diagram of how all the economic activity in the US was linked into a gigantic whole. (Most economic activity is the actual implementation of a few inter-related technologies.) If we had that linkage map, we might be able to read off it what technologies would live, or die, as groups. But we don't have that map because that work was itself a technology that has not survived.
Paul Nash on October 17, 2010 - 1:24am
I have to disagree absolutely that the steam engine, or steam locomotive, is more complex than a diesel one.
The number of moving parts, and precision machined parts, is much smaller. (an excellent photo comparison at http://www.cyclonepower.com/comparison.html)
The metallurgical treatments involved is much smaller. The steam engine can be operated without any electrical system at all (as can a diesel engine, but not a diesel electric). Steam engines do not de-rate with altitude. They can, suitably equipped, run on any fuel.
The "plumbing nightmare" is not much worse than the plumbing nightmare in and diesel - look at a map of lubricating oil flows in a diesel engine.
And, to cap it off, look at the *very* complex NOx emission control systems being fitted to modern diesels - these are not required with steam engines as the combustion takes place at atmospheric pressure, and NOx is not formed. The nature of continous combustion also minimises Co and HC emissionsGranted that the diesel IS more thermodynamically efficient, especially given the non- condensing nature of railroad steam engines, but I would argue there is a considerable increase in system complexity to get this. A diesel may be simpler for the operator, but it is a perfect example of the supply line issue - no diesel, no go. A suitably equipped steam engine can use almost any liquid, gas or solid fuel, and solid fuel can be, if needed, obtained in the field.
I think where the mismatch comes from is that steam locomotives are old, and were not developed over the last 80yrs, so they reflect knowledge as at the 1930's. Built with todays knowledge,many of the problems disappear - here is an example of a company in Switzerland making new steam locomotives (fired by oil)
http://www.dlm-ag.ch/attachments/Typenblatt_99.10xx_1d1_en.pdf
I would argue the steam engine (in modern form) is not more complex, just less efficient. It is then a case of trading off complexity for efficiency.
joule on October 17, 2010 - 9:34am
Paul Nash -
As I said, a good deal of complexity is in the eye of the beholder. I was largely talking about a steam locomotive versus a diesel-electric locomotive, not merely a generic steam engine versus a diesel engine. If you've ever examined detailed construction drawings of a 1940s-vintage steam locomotive, it should be evident that it has a very large number of parts, many of which are large and not easy to manufacture.
Both a steam engine and a diesel have cylinders and pistons, but a steam engine has the added complexity (and major headache) of a boiler. Plus, the valve train on one of these steam locomotives is far more complex than the valve and camshaft system on a diesel.
Much of the complexity associated with steam locomotives is separate from the physical object. While large and robust looking, a steam locomotive was a rather temperamental piece of machinery and required constant maintenance and repair. The main weak point was the boiler, which was prone to scale build-up from minerals in the feed water, required constant cleaning, and needed frequent replacement of boiler tubes. If in constant service, the locomotives often had to keep a banked fire in their fire box overnight so they could start up the next day without a long wait to get up steam. Railroads needed coaling and water tanks positioned along the route. Plus there was ash handling and disposal. All this was very labor-intensive, but back in those days labor was cheap.
Now with a diesel locomotive, you just fill her up like a car, and off you go. While the diesel engine is directly coupled to a generator and electric motor, no external electrical power is required. Of course, the electrical controls on a modern diesel do represent additional complexity.
Now, if you've ever examined the detailed drawings of a steam automobile .... now there's a plumbing and maintenance nightmare! No wonder it turned out to be a technological dead end.
One other thing, as a final note: steam locomotives were not really mass produced in the current sense of the word, but were turned out in relatively small batches, sort of like military aircraft. The manufacture of diesel engines on the other hand closely parallels that of the automotive industry, with all the associated economies of scale that entails.
But I guess these comparisons can only be taken so far, as after a while it's like asking: which is more complex, an apple or an orange?
Recision on October 16, 2010 - 7:26pm
Always and everywhere, the adoption or abandonment of technology is the cost/benefit equation. New technology/products replaces old technology/products because it is more cost effective/efficient (per the perceptions of the user). Technology is a tool for obtaining a result. When one type of technology becomes price prohibitive (or uncompetitive), it will be replaced with an alternative.
Technology per-se is essentially an intellectual understanding of our physical world and an ability to manipulate it. From that, all you need is some very basic tools in order to build more advanced tools in order to fabricate the ultimate tool or product you want.
While one "technology" or another may be adopted or abandoned due to the availability/cost of resources, that technology is really just a technique.
The real question is, have the techniques we have used to date to prosper, outrun our resource base due to an aberrantly high EROI we wont ever see again?
How much will we need to contract (if at all) over the next 10/50/100 years?daxr on October 16, 2010 - 8:25pm
Always and everywhere, the adoption or abandonment of technology is the cost/benefit equation
Only if you include "status" as one of the perceived benefits. Much of the electronics industry (and the auto industry as well, come to think of it) is devoted to developing status-conferring devices, and then selling them at a premium by emphasizing how cool you will be...
ebHubbleTelescope on October 16, 2010 - 8:12pm
I agree completely. This is something the Logistic function is better suited for as it brings about the concept of carrying capacity. The adoption of new technology saturates at some level (possibly below 100%) which is related to the maximum carrying capacity. (note that this is not anywhere near the same as using logistic for oil depletion, which has a completely different derivation)
If things die-off it could be simply a replacement with new technology which has the logistic shape. And that reflextion around the y-axis is exactly what Merrill is referring to. Brilliant!
So the question is whether something will die-off without something better taking its place?
Its all so tricky to model in any predictive sense in that we have no idea what the saturation level will be for any new product. Interesting to think about though.
PaulS on October 16, 2010 - 8:37pm
It occurs to me that a good chunk of what's being discussed is actually cost-shifting rather than actual abandonment. The employee with the lunch box gets to waste time futzing with the block of ice (and with the meltwater) so that the employer can save a few cents a day per employee. The time-cost of futzing with the ice doesn't appear on the employer's books, so it's free to the employer, and no one ever gets to discover whether the exercise is actually cost-effective overall, or not.
Something similar will happen with the gravel roads. The costs of cracked windshields, of extra accidents from the more rough and slippery surface, and of extra wear-and-tear on everything and anything where the clouds of gritty dust settle, don't appear on the county books. Those costs are free to the county, allowing it to squander the money on politicians' pet projects and the like. And again, those costs are never counted, so we never get to discover whether the exercise is cost-effective overall, or not.
Similarly with trying to force people onto slow, tardy, unreliable city buses. The immense time-cost is nowhere tallied, nor the psychological cost of people seeing even less of their families, so according to the reports and assessments that will all be free, with only the oil "savings" being counted.
Somehow I expect to see a lot more of this sort of arrant nonsense if and as things continue to get tougher. It seems like a shell game in much the same spirit as "Don't tax you, don't tax me, tax the fellow behind that tree."
Leckos,
Great article, and your one in the Defence Force Journal makes for good reading too. I am of the view that most abandonment of technologies to date has been for reasons of obsolesence and/or cost and/or environmental consequences (e.g. lead pipes, PCB's etc). It is hard to think of any that are directly from unavailability of a material, although reduced availability usually manifests itself as increased cost (as we are seeing with oil).
For this reason, I think modern society struggles with the concept of having to give something up (i.e. oil based personal transport) not because a better option is available, but because the current option is no longer available (at an affordable cost). The thought of having to back to something, such as the gravel roads, is anathema to most people, but sometimes there are advantages.
If you are not familiar with it, an excellent collection of such things is at the Low Tech Magazine
In the case of Australia (writing here as an expat Aussie living in Canada), part of the supply line problem is that Australia is often at the end of it, so I can thoroughly understand why the Australian military is keeping an eye on this. In a regional conflict situation this would be exacerbated even further.
My personal favourite example of a successful real world decision to specifically use an obsolete technology, in prefernce to the state of the art, is this device;
De Havilland Mosquito, 1942
The designers of this, in the late 30's, knew that aluminium would be in short supply in a war situation, as would machinists, and their machines. The decision to build it out of plywood was initially laughed at by the RAF, but DeHavillands reasoning was that wood would be in more plentiful supply (and is cheaper), and can easily be worked by carpenters, furniture makers etc, with simple equipment. This represents a perfect example of a conscious decision to decrease complexity.
And, of course, it proved it self to be faster and more capable than any other aircraft then in the skies.
So, there are cases, if the designers really look hard, where you can get the win-win of both increased capability and decreased complexity. This obviously works for the military, but clearly is a concept that most industries that sell to consumers (e.g. carmakers) have rejected.
eckos on October 17, 2010 - 6:52am
Thanks for your comments Paul.
For this reason, I think modern society struggles with the concept of having to give something up (i.e. oil based personal transport) not because a better option is available, but because the current option is no longer available (at an affordable cost). The thought of having to back to something, such as the gravel roads, is anathema to most people, but sometimes there are advantages.
That is an excellent description of what I was trying to explain in the article, but I don't think that I did as well as I could.
The Mosquito is an excellent example that you provide. Other examples could be the British Sten and Australian Owen sub machine guns developed during WWII which were crude but effective weapons.
The military (the situation would be no different for industry as well) has a very difficult balancing act to make. All modern militaries (state based anyway) are on a similiar path of increasing technological development. There are obvious reasons for this (measure, counter-measure and so on). This is essentially the basis of the paradox described in the journal article. But at some point there will need to be a transition to simpler more robust technologies. The issue is that the military that does this first has the potential to be at a significant disadvantage for as long as other militaries are still capable of maintaining their 'advanced' technological advantage.
The asymmetrical approach I guess is one way around this as has been demonstrated through successful insurgencies by technologically inferior forces.
Merrill on October 17, 2010 - 12:26pm
Suppose that NATO were to fight in Afghanistan without aircraft, drones, helicopters, armored vehicles, night vision goggles, GPS recievers, etc.
In other words, limit the forces to light infantry in trucks with rifles, grenade launchers, machine guns, mortars, light artillery, binoculars, maps, and other low tech supplies.
I'd think that a force of about 500,000 could eliminate the insurgency in about 6 months and take casualties of no more than 50,000.
Most of the military high-tech is oriented towards:
- fighting the war with very low casualty rates because otherwise political support will end, and
- proving out technologies and tactics in case a war with a similarly high-tech adversary occurs.
Problem with military high-technology is that there is no price constraint. As a result, it may evolve to the point where political support ends because military expenditures are damaging to the military's national economy, rather than acting as a Keyensian stimulus to the economy and as a source of pork for elected politicians.
Paul Nash on October 17, 2010 - 1:51pm
Yep, the low tech magazine is one of my favourite places - the old school techniques always had a reason why they were what they were, and we tend to forget them rapidly when they are obsolete, but many (such as the woodenpipes) still have their niche applications.
With the Mosquito, yes, wooden planes is what DH did, and that alone is one reason why they were not building many for the air force. Also correct about the concerns for tropical use - that is one of the reasons why wood became obsolete.
BUt, part of their pitch was the (likely) scarcity of aluminium and machinists, and once the war had started, it also became obvious there were plenty of skilled woodworkers available.
It was also obvious that if Britain was not defended successfully, the tropics would not matter.The key thing is, the wooden construction was considered, by industry and government, to be obsolete, and had been discarded by the military. DH knew the many advantages, simplicity of construction being one of them, and the Mosquito proved them right- brilliantly.
A great combination of modern engineering applied to old school methods/materials.Grouch on October 17, 2010 - 10:53am
"For example, maintaining mechanical items is likely to be more achievable than sophisticated electronic items."
I disagree. Microprocessors (specifically embedded microprocessors and microcontrollers) are cheap, non-perishable, lightweight, and mind-bogglingly useful.
My argument rests on these pillars:
After a couple of years of lurking on this site, I see Peak Oil unfolding as a "Great Depression that never ends" type scenario. If you think this scenario is unlikely, my comments will be of limited interest.
Microprocessors/microntrollers are cheap: only a couple of dollars. In a "never-ending great-depression" type of peak-oil scenario
Paul Nash on October 17, 2010 - 3:08pm
Grouch, Welcome to TOD!
I view the microprocessors as a perfect example of moving the complexity upstream, away from the user. And they are great, as long as you still have access to them, and someone knows how to build and program them.
That knowledge, however, becomes increasingly concentrated, and, those who make the chips decide which ones they wil continue to make, based on theior reasons, which can often lead to good chips systems becoming obsolete/unreproducible, even though they work fine. The same cannot be said of an engine crank - the ability to make that is everywhere.Case in point - I know a fellow who makes control systems for stand alone micro hydro systems. You need to have a governor to dump excess load, and give certain loads priority when their is excess demand. He developed such a system based on old style PLC's - works brilliantly. Except that said PLC's went out of production 1999. he bought several hundred from the last batch, but was told he would need to order 10,000 before they would even consider doing another production run.
There are other ways to achieve the same end, you can, of course, program a computer to do that, but that is a much more complex system. The remote nature off off grid hydro systems demands they be simple and reliable - dialing up for help is not always an option.
So good things can become obsolete not because something better replaces them, but because someone doesn't want to make them anymore. It leads to standardisation, but sometimes is a barrier to innovation. Overall, you are right in that we are better off, but there are of course cases where we are not.
jokuhl on October 17, 2010 - 3:36pm
Don't know about that example, Paul.
There are so many consumer level MicroProc's and PIC's available now, plus the countless hacks available on the web for using other consumer Electronics as Control Systems (Pocket PCs, etc) .. It seems that the genie has left the factory.. even tho' there is that equal/opposite force of Operating Systems and Hardware that has, indeed, grown more opaque and untouchable.. still, look at how the open-source community has been thriving, with numerous variants on Linux, etc, and other OS's and apps.
There is also a broad offering for small-shop custom Motherboards, Controllers and Op systems. Sure, the fab's can stop making a chip, but which is more important to them, control or sales? As soon as one chooses 'control', a bunch of competing upstarts seem to show up with visions of Sugardaddies dancing in their eyes instead..
Paul Nash on October 17, 2010 - 5:40pm
Well, that was as he told it to me five years ago. There are probably suitable alternatives available now, but he was adamant there weren;t then.
I think Linux and other OS stuff is actually the best thing since sliced bread, because it reverses the concentration and control of the information. not great for a controlling corporation, but great for the development of the stuff, as long as the signal to noise ratio is good enough.
With OS stuff you have less chance of "the old man with the secret died", as, by definition, it is not secret.
I think that will turn out to be the single largest benefit enabled by the internet, that's affordable. Also, this cheap price is made possible by the economies of scale of a large factory, and a large factory or 3 can be enough to produce the entire world demand.
Microprossors/microcontrollers are non-perishable: Electronics feel perishable because someone might invent a better device during a particularly long transit-time. However, in real life, they can sit on the shelf for decades and they're just as useful as the day they were built. In a "great depression that never ends" scenario, the actual utility of an electronic device (rather than how it performs relative to the one next to it on the shelf) will be the most important factor.
Lightweight: a chip the size of my thumbnail doesn't weigh much. Being lightweight and non-perishable makes it easy to ship, just like spices.
Mind-bogglingly useful: They can also make a mechanical system simpler while maintaining a complex behavior. For instance, a microcontroller can monitor a pyrometer, thermometer, rain gage, and a number of other factors to open and close the windows of a building or greenhouse in order to reduce the energy consumption when the owner is away. Note that I'm not talking about iPods here. This is a different kind of electronics here -- it's the parent of the electronics under the hood of your car, or that runs your microwave.
So, I think we'll be shipping microprocessors around the world, even in most Peak Oil scenarios. And I think that they wil be useful. My thought is that our technology will change quite a bit (and become much more user-serviceable) to reflect our new needs, but electromechanical systems are going to stay with us. The kids in any community who would have taken up HAM radio in the past can surely learn to program a microconteroller.
"Raw intellect ain't always all it's cracked up to be, advises Ted Dziuba in his introduction to Programming Things I Wish I Knew Earlier, so don't be too stubborn to learn the things that can save you from the headaches of over-engineering.
Here's some sample how-to-avoid-over-complicating-things advice:
- If Linux can do it, you shouldn't.
- Don't use Hadoop MapReduce until you have a solid reason why xargs won't solve your problem.
- Don't implement your own lockservice when Linux's advisory file locking works just fine.
- Don't do image processing work with PIL unless you have proven that command-line ImageMagick won't do the job.
Modern Linux distributions are capable of a lot, and most hard problems are already solved for you. You just need to know where to look.' Any cautionary tips you'd like to share from your own experience?"
msobkow
petes_PoV :The truth is that the "hard" way of doing things is often more fun, because you have the challenge of learning a new tool or API. Plus sometimes it's actually easier in the long run because you've engineered a solution for the outer bounds conditions of scalability, so if your application takes off, it can handle the load.
I guess the real issue is that you have to engineer a "good enough" solution rather than a "worst case" solution
melted:You might learn something from doing things the hard way, but all you'll achieve is a version #1. As we all know (or will learn) version #1 of pretty much everything should be thrown away and should NEVER see the light of a production server. However, timescales being what they are as soon as an application gets close to functional it gets snatched away and put live - no matter how ugly it is. After that, all you ever have time for is to patch the worst parts. Doing a complete rewrite from the ground up, to do it right, is a luxury few of us experience.
Do not make things super-modular and generic unless they 100% have to be. In 99.9% of the projects no one, including yourself, will use your stupid dependency injection, and logging / access control can be done just fine without AOP. Don't layer patterns where there's no need. Aim for the simplest possible design that will work. Don't overemphasize extensibility and flexibility, unless you KNOW you will need it, follow the YAGNI principle (you ain't gonna need it).
Dec 22, 2009 | oftwominds.com
Regarding The World Is Too Complex (Guest essay by Subuddh Parekh): I was first positively surprised by the headline, but I found the essay doesn't quite cut it! Let me explain:
Things are getting more and more complex in today's world. That is a statement few would doubt.
However the question is why. Is it necessary? Is it always necessary? How many people can keep up with changes and understand them? How can democracy / any form of participation still work if the majority doesn't even understand the broad overview anymore?
The real con of today is "more complex is better."
I am not proposing everybody is capable or should be allowed to fly a jet airliner or operate a nuclear power plant. And research & development as well as advanced manufacturing is definitely becoming more complex often for good reasons.
But the important or necessary parts of everyday life like shopping, household budgeting, insurance, taxes, and even retirement investments need to be handled adequately by the broad majority of people without weeks of special training or consulting a real or self-declared expert.
Otherwise the highly intelligent have just disenfranchised the masses, from there exploitation is just a tiny step away.
For example, look at the excesses from today's product descriptions on corporate websites to credit card contracts: vital information is intentionally hidden behind dozens of marketing pages or legal blather, or completely withheld, making it an especially tedious or impossible task to try to compare competitors.
Jim Quinn writes that Huxley foresaw that approach ( BRAVE NEW WORLD - 2009). While I sure have read Orwell--and by the way believe the most important point in his book "1984" is not total surveillance but Newspeak--it seems I should also read Huxley's "Brave New World."
The first time I realized that approach myself was funnily enough with Microsoft, the self-declared fighter for the "easy to use" personal computer since the advent of Windows operating system. I however worked as Senior Integrator on small to medium enterprise solutions. Having started with Novell 3.12 and playing around with Windows NT 3.51 during some low workload time, suddenly I got thrown so much new Microsoft stuff at me all the time, new Windows version, new Office version, new NT Server, Windows Domain concept, new Exchange Server -- that I never found time to take a closer look at competitor's offerings like NDS (Novell Directory Services) introduced with Novell 4.x release.
After 18 months I reflected on that and realized I need to start to ignore some Microsoft offerings to avoid total capture. I would state this has now become common approach for most IT product vendors.
Another special form manifests itself in the "idiot tax":
- The Economics of the HDMI Cable Ripoff (taken from The Economics of the HDMI Cable Ripoff ) I just bought a blu-ray player. There is a puzzle. Why don't any stores stock cheap HDMI cable? I knew cables were a ripoff yet I could not find reasonably priced cables at Best Buy, Radio Shack, Target or even Wal-Mart. Ordinarily, we would expect competition to push prices down but in this case it seem as if the mere existence of Monster is anchoring high prices everywhere but online.
- My best guess is that this is an unusually strong version of the hidden fee model of Laibson and Gabaix (1). In that model, firms overprice one aspect of service--such as a hotel charging exorbitant rates for telephone service--as an idiot tax.
- Crucially, the idiot tax is matched by a "sophisticated-consumer"-subsidy; the price of the hotel room is lower than it would be without the idiot tax--so the idiots don't know to shop elsewhere and the sophisticated-consumer types are, in fact, drawn to stores with an idiot tax. Thus, buy your blu-ray player at places such as Best Buy which sell a lot of expensive cable as well as massively overpriced extended warranties.
(1) Here is the bottom line:
Laibson and Gabaix's explanation relies on a good bit of math, too, but it can be summarized pretty simply using a hypothetical example. Imagine two hotel chains. The first, Hidden Price Inn, has a very low room rate of $80 a night, but makes liberal use of high "shrouded" fees: Three bucks for a minibar Dr Pepper, $25 for parking, $12 for eggs at breakfast.The unsophisticated traveler cheerily (if unwittingly) forks over the fees, all the while patting herself on the back for getting a cheap room.
Now imagine a second chain, Straightforward Suites. It charges much more reasonably for the extra costs ($1, say, for that Dr Pepper), but because it makes less on the extras, it has to charge slightly more for the room-- $95, instead of $80.
Even an unsophisticated traveler can tell $95 isn't as good as $80. Through an aggressive ad campaign, Straightforward could try to point out how devious the approach of Hidden Price Inn is and how much less deceptive its own prices are. But Laibson and Gabaix show that there's a catch in this strategy: Hidden Price Inn actually has two key types of customers.
Yes, there are the clueless consumers (the economists prefer to call them "myopic"). But there are also the sophisticated ones, who know that if they avoid the hotel restaurant, take a taxi instead of using the parking garage, and call home with a cellphone, they'll actually get a better deal at Hidden Price than at Straightforward.
Straightforward Suites's ad campaign, then, might just end up increasing the ranks of sophisticated consumers who will in turn dial up Hidden Price Inn for a cut-rate room. Rather than play this self-defeating game, Straightforward will most likely just lower its own room prices and stick it to the customers on the extras. (from Why are there hidden fees? )
Subuddh Parekh comes to the wrong conclusion (as pretty much everybody else, I can't blame him): "So what are the 'solutions'? There aren't any as yet. We just have to deal with this complexity in whatever way we can."
Einstein is attributed of having said: "Make everything as simple as possible, but not simpler."
The solution is: Unnecessary complexity has to be cut down. If we don't do it voluntarily, a societal collapse will do it for us.
Therefore:
- Prefer the simpler solution, if it covers your needs. Don't buy something or pay more for a feature you don't understand (unless you have the time, money, and will to take on the early adopter role - please inform others of your experiences).
- If things become intertwined, or complex for good reason, buy from the vendor which you believe has, and operates on, simple, sound principles. Even if he is a bit more expensive than the promise-all competitor. So in the above example choose Straightforward Suites. The same should be applied when voting for politicians.
- Spread the word (in a rational, calm manner please) if you are feeling tricked by somebody.
- But be prepared as well to fight arising trends of oversimplification, like black and white thinking, promises of one-size-fits-all perfect solutions.
Remember: For every complex problem, there is a solution that is simple, neat, and wrong. – H. L. Mencken
But the necessities of life need to remain simple enough that pretty much everyone can comprehend them.
Notes:
1.) I also believe the '68ers to play an important role towards today's mess. While they started beneficial in breaking up narrow views, they overdid it by finally declaring pretty much every opinion correct and of equal value, thereby (unintentionally?) paving the way to unfettered individualism. When this started to become offensive and/or unsustainable after a decade or so, some con artists started to cover it up with complexity. And this complies with what I (unofficially) call the "Milgram effect": given multiple choices most people will avoid selecting one which would invalidate their previous behavior. (His book remains a must read: Obedience to Authority: An Experimental View )
2.) A banker once told me: Complex investment products are/were only invented so the seller can charge higher fees as no investor can value them himself nor compare them. 3.) The next step is upper management and other "leaders" pretend they understand the newest complex models, the underlying assumptions (!) and the implications. Great article which I fully agree with is Mad Mathesis.
CHS note: I also recommend another book on experiments in inducing obedience to authority: The Lucifer Effect: Understanding How Good People Turn Evil.
Written by Chris Chedgey, September 07th, 2006
Ben Hosking writes in Managing Complexity - The aim of Designing Code that:
"The most important part of design is managing complexity"
I like the simplicity of that. What happens if you don't manage complexity. Well, it starts to cost. Talking at OOPSLA 2004, Ward Cunningham (Mr. Wiki) compared complexity with debt:
"Manage complexity like debt," Cunningham told attendees. Using this analogy, he likened skipping designs to borrowing money; dealing with maintenance headaches like incurring interest payments; refactoring, which is improving the design of existing code, like repaying debt; and creating engineering policies like devising financial policies.
In an interview with Bill Venners (Artima), Andy Hunt (Pragmatic Programmer) extends the analogy concisely:
"But just like real debt, it doesn't take much to get to the point where you can never pay it back, where you have so many problems you can never go back and address them."
It's a lovely metaphor. But it does breaks down in one place. Project managers don't get a pile of bills through the door every month. Even if they wanted to, they can't rip them open, sum them up, compare them against income and outgoings and discover just how fragged they are, or even hell, that they can afford loads more debt!
Well it's not quite that bad. We can at least measure and sum up the complexity of items at different levels of design breakout (methods, classes, packages, subsystems and projects). We may not be able to put a hard complexity number on the tipping point (insolvency), but we can give you a number. With this you can compare projects, monitor trends that show where it's getting more or less complex, and discover which items at what level are causing the trend.
I was reading Code Complete and the chapter was talking about Design and it was saying one of the most important parts of Design is managing complexity.This makes perfect sense really, the whole process of designing is breaking the problem into smaller more manageable bits. He states that humans struggle to comprehend one massive complicated piece of software but can understand it easier if you split it down into small subsections.
If you think about the way you start designing you work with large abstract ideas and then slowly work down into smaller and smaller sections, until you end up with lots of small sections.
What I like about the idea of Managing complexity is that it means you start with something simple and then battle with it to keep it simple. It reminds me of seeing the code for a design pattern or a piece of code my some Java ninja, it always strikes me how simple it looks (and then you think, I could have done that).
I also like the word complexity because it's at the heart of making reusable code, reducing the complexity using encapsulation, and cohesion. I also think of complexity as being directly linked to the number of classes linked to a class. e.g. coupling. A simple class/package has loose coupling and is linked to the smallest amount of other classes as possible.
This is easier to understand, maintain and test.
What strikes me about linking Design with Managing Complexity is it is explaining simply what you are aiming to do when designing your code and just having that in my mind will help me focus on the objective of managing complexity.This chapter is actually a free download on the Code Complete site, so if you would like to read more, firstly I would suggest you buy the book because I am finding it very useful and interesting but if you would like a taster to see if you would like the book here is the link
http://cc2e.com/docs/Chapter5-Design.pdf
I have talked about this book before and given links to two sample chapters, if you want a rough outline of the book a list of the contents, check out my previous blog entry
http://hoskinator.blogspot.com/2006/06/design-in-construction-code-complete-2.html
expect to see me talk about more of the topics mentioned in this book
Minimalism, Architecture and Development
Fascinating and deeply disturbing,
May 29, 2004 Tainter's project here is to articulate his grand unifying theory to explain the strange and disturbing fact that every complex civilisation the world has ever seen has collapsed.
By Chris Stolz (canada) - See all my reviews

Tainter first elegantly disposes of the usual theories of social decline (disappearance of natural resources, invasions of barbarians, etc). He then lays out his theory of decline: as societies become more complex, the costs of meeting new challenges increase, until there comes a point where extra resources devoted to meeting new challenges produce diminishing and then negative returns. At this point, societies become less complex (they collapse into smaller societies). For Tainter, social problems are always (ultimately) a problem of recruiting enough energy to "fuel" the increasing social complexity which is necessary to solve ever-newer problems.
Complexity, writes Tainter, describes a variety of characteristics in a number of societies. Some aspects of complexity include many differentiated social roles, a large class of administrators not involved in the production of primary resources, energy devoted to different kinds of communication, centralized government, etc. Societies become more complex in order to solve problems. Complexity, for Tainter, is quantifiable. Where, for example, the Cherokee natives of the U.S. had about 5,000 cultural artifacts (things ranging from recipes to tools to tents) which were integral to their culture, the Allied troops landing on the Normandy coast in 1944 had about 40,000.
Herein, however, lies the rub. Since, as Tainter writes, the "number of challenges with which the Universe can confront a society is, for practical purposes, infinite," complex societies need to keep on increasing their level of complexity in order to survive new challenges. Tainter's thesis is that these "investments in additional complexity" produce fewer and fewer returns with time, until eventually society cannot muster enough energy to fuel complexity. At this point, society collapses.
Consider this example: A simple hunter-gatherer society with limited agriculture (i.e. garden plots) is faced with a problem, such as a seasonal drop in food production (or an invasion from its neighbours who have the same problem and are coming over for food). The bottom line is, this society faces an energy shortage. This society could respond to the food crisis by either voluntarily declining in numbers (die-off, and unlikely) or by increasing production. Most societies choose the latter. In order to increase production, this society will need to either expand territorially (invade somebody else) or increase agricultural production . In either case, this investment can pay off substantially in either increased access to already-produced food or increased food production.
But the hunter-gatherers of the above example incur costs as they try to solve their food-shortage problem. If they conquer their neighbors, they have to garrison those territories, thus raising the cost of government. If they start agriculture on a larger or more intense scale in their own territories, they have to create a new class of citizens to man the farms, distribute and store the grain, and guard it from animals and invaders. In either case, the increases in access to energy (food) are offset somewhat by the increased cost of social complexity.
But, as the society gets MORE complex to confront newer challenges, the returns on these increases in complexity diminish. Eventually, the costs of maintaining garrisons (as the Romans found) is so high that both home and occupied populations revolt, and welcome the invaders with their simpler way of life and their lower taxes. Or, agricultural challenges (a massive drought, or degradation of soils) are so great that the society cannot muster the energy reserves to deal with them.
Tainter's book examines the Mayan, Chacoan and Roman collapses in terms of his theory of diminishing marginal returns on investments in complexity. This is the fascinating part of the book; the disturbing sections are Chapter Four and the final chapter. In Chapter 4, Tainter musters a massive array of statistics that show that modern society has been facing diminishing returns on investments in complexity. There is a very simple reason for this: we solve the easiest problems first. Take oil, for example. In 1950, spending the energy equivalent of one barrel of oil in searching for more oil yielded 100 barrels in discovered oil. In 2004, the world's five largest energy companies found less oil energy than they expended in looking for that energy. The per-dollar return on R&D investment has dropped for fifty years. In education, additional investments in programs, technology etc. no longer produce increases in outcomes. In short, industrial society is looking at steadily fewer returns on its investments in both non-human and human capital.
When a new challenge comes, Tainter argues, society will eventually be unable to muster the necessary resources to deal with the crisis, and will revert-- in a painful and unhappy way-- to a much simpler way of life.
In his final chapter, Tainter describes the modern world's "arms race of complexity" and makes some uncomfortable suggestions about our own future. (...). In an age where, for example, the U.S. invasion of Iraq has yielded net negative returns on investment even for the invaders (where's that cheap oil?), and where additional investments in education and health care in industrialised countries make no significant increases in outcomes, the historical focus of Tainter's work starts to become eerily prescient.
The scary thing about this deeply thoughtful and thoroughly researched book is its contention that the future, for all our knowledge and technology, might be an awful lot like the past.
January 22, 2006 To get an idea of the impact this book has had both among scholars and on the general public one has only to look at its publishing record. It was written by an academic for academics and published by a university press (Cambridge no less) yet it is now in its fourteenth printing since its initial release in 1988.
By Allen B. Hundley
Tainter argues that human societies exist to solve problems. He looks at a score of societal collapses, focusing on three: Rome, the Maya, and the Chacoan Indians of the American Southwest. As these societies solved problems - food production, security, public works - they became increasingly complex. Complexity however carries with it overhead costs, e.g. administration, maintaining an army, tax collection, infrastructure maintenance, etc. As the society confronts new problems additional complexity is required to solve them. Eventually a point is reached where the overhead costs that are generated result in diminishing returns in terms of effectiveness. The society wastefully expends its resources trying to maintain its bloated condition until it finally collapses into smaller, simpler, more efficient units. (Does this sound like any contemporary societies we know?)
One of the powerful attractions of this book is that, although written by an academic for a scholarly audience, the author is fully aware of his theory's relevance to the future of our own society, comments upon which he reserves for the final chapter. While Tainter states explicitly (writing in 1988) that he does not believe the collapse of our civilization is imminent, in a remarkably candid passage he characterizes the survivalist movement in the U.S. (excluding the lunatic fringe element) as being a rational response to concerns about the viability of our current political system. The same goes for those in the self reliance, grow you own food movement. "The whole concern with collapse and self-sufficiency may itself be a significant social indicator, the expectable scanning behavior of a social system under stress..." (p.211).
Keep in mind that Tainter is writing before the first Gulf War, Y2K, 9-11 and before our current involvement in Iraq. New energy sources are the key, he says, to maintaining economic well-being. "A new energy subsidy is necessary if a declining standard of living and a future global collapse are to be averted." By subsidy he means the development of new forms of energy. This "development must be an item of the highest priority even if, as predicted, this requires reallocation of resources from other economic sectors." (p. 215).
Almost twenty years have passed since Tainter wrote those words. I leave it for you the reader of this review to judge the capability of our current political system to respond to such a grave and obvious crisis.
I have given this book 5 stars not because it is the final answer to the question of how civilizations or societies collapse but because it represents an important step along the way to that answer. As Jared Diamond correctly points out in his new "Collapse: How Societies Choose to Fail or Succeed," complex societies would be expected to be the best at staving off collapse because they are by definition the most highly organized, with the best information, resource and administrative structures to deal with new challenges. Clearly other factors must be at work. Tainter however dismisses all previous theories of collapse, calling many of them `mystical'. Included in this latter group are many of the world's greatest thinkers from Plato and Polybius to Gibbon and Toynbee.
What Tainter really means is that their explanations are not quantifiable, therefore not scientific, and therefore unworthy of further consideration. This is a most unfortunate mistake. Insight is insight regardless of whether or not it is quantifiable. If a scientific approach to societal decision-making always worked Robert McNamara's faith in body count statistics should surely have resulted in a U.S. victory in Vietnam.
At one point Tainter states that individuals can never alter the course of world history, only powerful long-term societal forces. This flies in the face of overwhelming evidence to the contrary, from the 300 Spartans at Thermopylae to Lee's bungling at Gettysburg, to Winston Churchill and Lord Dowding in the Battle of Britain. (See my review on the latter.) The fact that at critical junctures in history a handful of individuals have made a huge difference is extremely frustrating to those in the `social science' community. They would like to believe that with enough good statistics you can predict the future with precision. This has never been and likely never will be the case, a reality I came to terms with many years ago and the main reason I never completed my doctoral studies in `political science'.
Allowing that Tainter's complexity model really does have considerable explanatory power, the important question is can you have an advanced society that is immune to complexity's dangers? The answer in this reviewer's opinion is a qualified `yes' but such a society would have to be organized very differently with far less interdependence, and hence fragility, than anything we now know. If world events (terrorism, Iran, North Korea, etc.) continue along the track they have taken in recent years, we may soon, for better or worse, have the opportunity to find out. 31 of 31 people found the following review helpful:
March 30, 2006 By Erik D. Curren
In contrast to Jered Diamond's "Collapse," this volume does not just focus on one theory of why societies collapse--depletion of natural resources--but presents in summary several different theories. In academic style, Tainter examines the pros and cons of each, offering a cornucopia of references that would be an invaluable source for future research.
While he sees some merit to most theories, one he holds in complete contempt, while another he tends to prefer. Tainter has no patience for "mystical" notions that societies collapse because their moral fiber has degenerated, a theory made famous by Gibbon, Spengler and Toynbee. What he does believe is that complex societies always at some point reach a stage where they become too complex, where the costs to citizens and elites alike begin to outweigh the benefits of keeping the society together. At that point, the society is vulnerable to breaking up.
This is what happened to the Western Roman Empire in the fifth century. The burden of inflation and taxes became so heavy on the populace that even the Italians began to yearn for "liberation" by barbarian tribes. And collapse is not always a bad thing: tribes like the Vandals actually governed their sections of the old empire more effectively.
So, what about us? Because of globalization, any collapse would affect all industrialized countries together. So, the US cannot collapse without either being taken over by a competitor or bringing everyone else down with us. Oil running out might be the end of our era of complexity, an anomaly in human history, but we still have time to make changes that could forestall collapse. Overall, a fresh view of history key to understanding the present.
Complexity has turned out to be very difficult to define. The dozens of definitions that have been offered all fall short in one respect or another, classifying something as complex which we intuitively would see as simple, or denying an obviously complex phenomenon the label of complexity. Moreover, these definitions are either only applicable to a very restricted domain, such as computer algorithms or genomes, or so vague as to be almost meaningless. Edmonds (1996) gives a good review of the different definitions and their shortcomings, concluding that complexity necessarily depends on the language that is used to model the system. Still, I believe there is a common, "objective" core in the different concepts of complexity. Let us go back to the original Latin word complexus, which signifies "entwined", "twisted together".
This may be interpreted in the following way: in order to have a complex you need two or more components, which are joined in such a way that it is difficult to separate them. Similarly, the Oxford Dictionary defines something as "complex" if it is "made of (usually several) closely connected parts". Here we find the basic duality between parts which are at the same time distinct and connected. Intuitively then, a system would be more complex if more parts could be distinguished, and if more connections between them existed. More parts to be represented means more extensive models, which require more time to be searched or computed. Since the components of a complex cannot be separated without destroying it, the method of analysis or decomposition into independent modules cannot be used to develop or simplify such models. This implies that complex entities will be difficult to model, that eventual models will be difficult to use for prediction or control, and that problems will be difficult to solve. This accounts for the connotation of difficult, which the word "complex" has received in later periods.
The aspects of distinction and connection determine two dimensions characterizing complexity. Distinction corresponds to variety, to heterogeneity, to the fact that different parts of the complex behave differently. Connection corresponds to constraint, to redundancy, to the fact that different parts are not independent, but that the knowledge of one part allows the determination of features of the other parts. Distinction leads in the limit to disorder, chaos or entropy, like in a gas, where the position of any gas molecule is completely independent of the position of the other molecules. Connection leads to order or negentropy, like in a perfect crystal, where the position of a molecule is completely determined by the positions of the neighbouring molecules to which it is bound. Complexity can only exist if both aspects are present: neither perfect disorder (which can be described statistically through the law of large numbers), nor perfect order (which can be described by traditional deterministic methods) are complex. It thus can be said to be situated in between order and disorder, or, using a recently fashionable expression, "on the edge of chaos".
The simplest way to model order is through the concept of symmetry, i.e. invariance of a pattern under a group of transformations. In symmetric patterns one part of the pattern is sufficient to reconstruct the whole. For example, in order to reconstruct a mirror-symmetric pattern, like the human face, you need to know one half and then simply add its mirror image. The larger the group of symmetry transformations, the smaller the part needed to reconstruct the whole, and the more redundant or "ordered" the pattern. For example, a crystal structure is typically invariant under a discrete group of translations and rotations. A small assembly of connected molecules will be a sufficient "seed", out of which the positions of all other molecules can be generated by applying the different transformations. Empty space is maximally symmetric or ordered: it is invariant under any possible transformation, and any part, however small, can be used to generate any other part.
It is interesting to note that maximal disorder too is characterized by symmetry, not of the actual positions of the components, but of the probabilities that a component will be found at a particular position. For example, a gas is statistically homogeneous: any position is as likely to contain a gas molecule as any other position. In actuality, the individual molecules will not be evenly spread. But if we look at averages, e.g. the centers of gravity of large assemblies of molecules, because of the law of large numbers the actual spread will again be symmetric or homogeneous. Similarly, a random process, like Brownian motion, can be defined by the fact that all possible transitions or movements are equally probable.
Complexity can then be characterized by lack of symmetry or "symmetry breaking", by the fact that no part or aspect of a complex entitity can provide sufficient information to actually or statistically predict the properties of the others parts. This again connects to the difficulty of modelling associated with complex systems.
(1996) notes that the definition of complexity as midpoint between order and disorder depends on the level of representation: what seems complex in one representation, may seem ordered or disordered in a representation at a different scale. For example, a pattern of cracks in dried mud may seem very complex. When we zoom out, and look at the mud plain as a whole, though, we may see just a flat, homogeneous surface. When we zoom in and look at the different clay particles forming the mud, we see a completely disordered array. The paradox can be elucidated by noting that scale is just another dimension characterizing space or time (Havel, 1995), and that invariance under geometrical transformations, like rotations or translations, can be similarly extended to scale transformations (homotheties).
Havel (1995) calls a system "scale-thin" if its distinguishable structure extends only over one or a few scales. For example, a perfect geometrical form, like a triangle or circle, is scale-thin: if we zoom out, the circle becomes a dot and disappears from view in the surrounding empty space; if we zoom in, the circle similarly disappears from view and only homogeneous space remains. A typical building seen from the outside has distinguishable structure on 2 or 3 scales: the building as a whole, the windows and doors, and perhaps the individual bricks. A fractal or self-similar shape, on the other hand, has infinite scale extension: however deeply we zoom in, we will always find the same recurrent structure. A fractal is invariant under a discrete group of scale transformations, and is as such orderly or symmetric on the scale dimension. The fractal is somewhat more complex than the triangle, in the same sense that a crystal is more complex than a single molecule: both consist of a multiplicity of parts or levels, but these parts are completely similar.
To find real complexity on the scale dimension, we may look at the human body: if we zoom in we encounter complex structures at least at the levels of complete organism, organs, tissues, cells, organelles, polymers, monomers, atoms, nucleons, and elementary particles. Though there may be superficial similarities between the levels, e.g. between organs and organelles, the relations and dependencies between the different levels are quite heterogeneous, characterized by both distinction and connection, and by symmetry breaking.
We may conclude that complexity increases when the variety (distinction), and dependency (connection) of parts or aspects increase, and this in several dimensions. These include at least the ordinary 3 dimensions of spatial, geometrical structure, the dimension of spatial scale, the dimension of time or dynamics, and the dimension of temporal or dynamical scale. In order to show that complexity has increased overall, it suffices to show, that - all other things being equal - variety and/or connection have increased in at least one dimension.
The process of increase of variety may be called differentiation, the process of increase in the number or strength of connections may be called integration. We will now show that evolution automatically produces differentiation and integration, and this at least along the dimensions of space, spatial scale, time and temporal scale. The complexity produced by differentiation and integration in the spatial dimension may be called "structural", in the temporal dimension "functional", in the spatial scale dimension "structural hierarchical", and in the temporal scale dimension "functional hierarchical".
It may still be objected that distinction and connection are in general not given, objective properties. Variety and constraint will depend upon what is distinguished by the observer, and in realistically complex systems determining what to distinguish is a far from trivial matter. What the observer does is picking up those distinctions which are somehow the most important, creating high-level classes of similar phenomena, and neglecting the differences which exist between the members of those classes (Heylighen, 1990). Depending on which distinctions the observer makes, he or she may see their variety and dependency (and thus the complexity of the model) to be larger or smaller, and this will also determine whether the complexity is seen to increase or decrease.
For example, when I noted that a building has distinguishable structure down to the level of bricks, I implicitly ignored the molecular, atomic and particle structure of those bricks, since it seems irrelevant to how the building is constructed or used. This is possible because the structure of the bricks is independent of the particular molecules out of which they are built: it does not really matter whether they are made out of concrete, clay, plaster or even plastic. On the other hand, in the example of the human body, the functioning of the cells critically depends on which molecular structures are present, and that is why it is much more difficult to ignore the molecular level when building a useful model of the body. In the first case, we might say that the brick is a "closed" structure: its inside components do not really influence its outside appearance or behavior (Heylighen, 1990). In the case of cells, though, there is no pronounced closure, and that makes it difficult to abstract away the inside parts.
Although there will always be a subjective element involved in the observer's choice of which aspects of a system are worth modelling, the reliability of models will critically depend on the degree of independence between the features included in the model and the ones that were not included. That degree of independence will be determined by the "objective" complexity of the system. Though we are in principle unable to build a complete model of a system, the introduction of the different dimensions discussed above helps us at least to get a better grasp of its intrinsic complexity, by reminding us to include at least distinctions on different scales and in different temporal and spatial domains.
References:
- Heylighen F. (1997): "The Growth of Structural and Functional Complexity during Evolution", in: F. Heylighen & D. Aerts (eds.) (1997): "The Evolution of Complexity" (Kluwer, Dordrecht). (in press)
- Edmonds B. (1996): "
- Havel I. (1995): "Scale Dimensions in Nature", International Journal of General Systems 23 (2), p. 303-332.
- Heylighen F. (1990): "Relational Closure: a mathematical concept for distinction-making and complexity analysis", in: Cybernetics and Systems '90 , R. Trappl (ed.), (World Science Publishers), p. 335-342.
See also:
blind variation and selective retention tend to produce increases in both structural and functional complexity of evolving systems
At least since the days of Darwin, evolution has been associated with the increase of complexity: if we go back in time we see originally only simple systems (elementary particles, atoms, molecules, unicellular organisms) while more and more complex systems appear in later stages. However, from the point of view of classical evolutionary theory there is no a priori reason why more complicated systems would be preferred by natural selection. Evolution tends to increase fitness, but fitness can be achieved as well by very complex as by very simple systems. For example, according to some theories, viruses, the simplest of living systems, are degenerated forms of what were initially much more complex organisms. Since viruses live as parasites, using the host organisms as an environment that provides all the resources they need to reproduce themselves, maintaining a metabolism and reproductory systems of their own is just a waste of resources. Eventually, natural selection will eliminate all superfluous structures, and thus partially decrease complexity. Complexity increase for individual (control) systems
The question of why complexity of individual systems appears to increase so strongly during evolution can be easily answered by combining the traditional cybernetic idea of the "Law of Requisite Variety" and a concept of coevolution, as used in the evolutionary "Red Queen Principle".Ashby's Law of Requisite Variety states that in order to achieve complete control, the variety of actions a control system should be able to execute must be at least as great as the variety of environmental perturbations that need to be compensated. Evolutionary systems (organisms, societies, self-organizing processes, ...) obviously would be fitter if they would have greater control over their environments, because that would make it easier for them to survive and reproduce. Thus, evolution through natural selection would tend to increase control, and therefore internal variety. Since we may assume that the environment as a whole has always more variety than the system itself, the evolving system would never be able to achieve complete control, but it would at least be able to gather sufficient variety to more or less control its most direct neighbourhood. We might imagine a continuing process where the variety of an evolving system A slowly increases towards but never actually matches the infinite variety of the environment.
However, according to the complementary principles of selective variety and of requisite constraint, Ashby's law should be restricted in its scope: at a certain point further increases in variety diminish rather than increase the control that system A has over its environment. A will asymptotically reach a trade-off point, depending on the variety of perturbations in its environment, where requisite variety is in balance with requisite constraint. For viruses, the balance point will be characterised by a very low variety, for human beings by a very high one.
This analysis assumes that the environment is stable and a priori given. However, the environment of A itself consists of evolutionary systems (say B, C, D...), which are in general undergoing the same asymptotic increase of variety towards their trade-off points. Since B is in the environment of A, and A in the environment of B, the increase in variety in the one will create a higher need (trade-off point) in variety for the other, since it will now need to control a more complex environment. Thus, instead of an increase in complexity characterised by an asymptotic slowing down, we get a positive feedback process, where the increase in variety in one system creates a stronger need for variety increase in the other. The net result is that many evolutionary systems that are in direct interaction with each other will tend to grow more complex, and this with an ever increasing speed.
As an example, in our present society, individuals and organizations tend to gather more knowledge and more resources, increasing the range of actions they can take, since this will allow them to cope better with the possible problems appearing in their environment. However, if the people you cooperate or compete with (e.g. colleagues) become more knowledgeable and resourceful, you too will have to become more knowledgeable and resourceful in order to respond to the challenges they pose to you. The result is an ever faster race towards more knowledge and better tools, creating the "information explosion" we all know so well.
The present argument does not imply that all evolutionary systems will increase in complexity: those (like viruses, snails or mosses) that have reached a good trade-off point and are not confronted by an environment putting more complex demands on them will maintain their present level of complexity. But it suffices that some systems in the larger ecosystem are involved in the complexity race to see an overall increase of available complexity.
Complexity increase for global (eco)systems
The resoning above explains why individual systems will on average tend to increase in complexity. However, the argument can be extended to show how complexity of the environment as a whole increases. Let us consider a global system, consisting of a multitude of co-evolving subsystems. The typical example would be an ecosystem, where the subsystems are organisms belonging to different species.Now, it is well-documented by ecologists and evolutionary biologists that ecosystems tend to become more complex: the number of different species increases, and the number of dependencies and other linkages between species increases. This has been observed as well over the geological history of the earth, as in specific cases such as island ecologies which initially contained very few species, but where more and more species arose by immigration or by differentiation of a single species specializing on different niches (like the famous Darwin's finches on the Galapagos islands).
As is well explained by E.O. Wilson in his "The Diversity of Life", not only do ecosystems contain typically lots of niches that will eventually be filled by new species, there is a self-reinforcing tendency to create new niches. Indeed, a hypothetical new species (let's call them "bovers") occupying a hitherto empty niche, by its mere presence creates a set of new niches. Different other species can now specialize in somehow using the resources produced by that new species, e.g. as parasites that suck the bover's blood or live in its intestines, as predators that catch and eat bovers, as plants that grow on the bovers excrements, as furrowers that use abandoned bover holes, etc. etc. Each of those new species again creates new niches, that can give rise to even further species, and so on, ad infinitum. These species all depend on each other: take the bovers away and dozens of other species may go extinct.
This principle is not limited to ecosystems or biological species: if in a global system (e.g. the inside of a star, the primordial soup containing different interacting chemicals, ...) a stable system of a new type appears through evolution (e.g. a new element in a star, or new chemical compound), this will in general create a new environment or selector. This means that different variations will either be adapted to the new system (and thus be selected) or not (and thus be eliminated). Elimination of unfit systems may decrease complexity, selection of fit systems is an opportunity for increasing complexity, since it makes it possible for systems to appear which were not able to survive before. For example, the appearance of a new species creates an opportunity for the appearance of species-specific parasites or predators, but it may also cause the extinction of less fit competitors or prey.
However, in general the power for elimination of other systems will be limited in space, since the new system cannot immediately occupy all possible places where other systems exist. E.g. the appearance of a particular molecule in a pool of "primordial soup" will not affect the survival of molecules in other pools. So, though some systems in the neighbourhood of the new system may be eliminated, in general not all systems of that kind will disappear. The power for facilitating the appearance of new systems will similarly be limited to a neighbourhood, but that does not change the fact that it increases the overall variety of systems existing in the global system. The net effect is the creation of a number of new local environments or neighbourhoods containing different types of systems, while other parts of the environment stay unchanged. The environment as a whole becomes more differentiated and, hence, increases its complexity.
What's preventing businesses from realizing better utilization rates is an outbreak of the 1:1:1 ratio - one application per operating environment per server. While this ratio is effective for meeting peak load targets, it's off the mark for achieving IT efficiency. The more things that need to be managed, the more time-consuming and expensive that infrastructure becomes. Clearly, this approach to managing the infrastructure doesn't scale effectively - a big problem when saving IT dollars is the primary goal.
The old paradigm of managing infrastructure resources is largely to blame for the current system bloat. Traditionally, organizations have invested in people to manage this legacy of 1:1:1. So as the business grew, people-management costs significantly increased - a practice that is prohibitively expensive.
Many IT managers also thought having dedicated server environments was a more reliable way to ensure performance and availability while mitigating security risks. But allowing each department to control its own resources has exacerbated the problem of doing more with more, rather than doing more with less. Finally, to meet workload requirements, IT managers often looked to peak workloads as the barometer for system needs. Yet basing server needs on peak usage levels is costly and inefficient, as normal loads typically require just a fraction of those resources and not all applications will peak at the same time.
An obvious way to combat these costly practices is through server consolidation. But simply getting more applications onto fewer servers is not enough. Effective server consolidation is contingent on maintaining the confidence of IT managers that applications will have the resources they need to meet performance levels. It's also important that applications housed on the same server can be isolated to avoid fault propagation.
Said another way, server consolidation is only valuable if IT managers have the same assurance that performance levels will be on par with levels achieved by the 1:1:1 ratio and the confidence that one application will not adversely impact the security or availability of other applications co-hosted on the same server. There is a way to make this a reality. By implementing the technique of virtualization into your data center utilization strategy, you can achieve all the benefits of the 1:1:1 setup while simultaneously reducing IT expenses.
Entrepreneur
Also be aware of the other side of the same coin: excessive debt and overhead. Debt can destroy your start-up, so stick to your business plan, and don't let appetite exceed budget or planned expenditures. "Too many entrepreneurs bring the infrastructure 'bloat' from their previous corporate careers to their start-up," says Pierce Johnson, founder of Chicago-based Johnson Technologies Inc. (which he sold last year to eSkye Solutions). "Most of the failed companies I know added too many employees too soon."
Basic rule: Stick to the business plan, and if a particular expenditure isn't budgeted there, forget about it.
Knowledge@Wharton
Managing Complexity
Wilson points out that complexity can be an organizational drag, consuming resources, diluting focus and impacting profitability. In that way, it can be a drag on innovation efforts. But conversely, he notes, it is important to understand how the current innovation system helps or hinders the issue of complexity. "In many situations, the innovation system itself can be one of the drivers -- a poor innovation system can lead to clutter and complexity," he says.
Next, companies must get a grip on what causes that complexity. "Is it a lack of customer knowledge, or poor understanding of the economics of the situation?" asks Wilson. Additionally, he says, they need to get an accurate picture of the real effects of complexity.
There are corrective strategies for complexity, he notes. "One of them is to reduce complexity in your portfolio or in your processes. But reducing your portfolio is only one strategy, and it may not be the right strategy for your organization."
Another strategy, says Wilson, is to "make your complexity more approachable for the customer and make the choices digestible." Indeed, there exist ways to empower the customer to comfortably deal with the full range of a company's offerings.
Wharton marketing professor Barbara Kahn says discovering that golden mean of how much is not too much is the trick. "If it's too much, they won't deal with it; if it's too little, then they may be able to deal with it," she says of customers' buying patterns.
That's where customer expertise comes into play, according to Kahn. "One of the factors that makes [a higher number of offerings possible] is expertise," she says. "The more people become experts, the more they articulate their preferences -- and the more they have a consumption vocabulary and know what the relevant attributes are, the more variety they will be able to take." She also suggests "arranging [product] assortment in such a way that consumers just see what it is they want and they don't have to see all that they don't want. Websites are really good at that."
Kahn likens the process of empowering customers with how salad bars help patrons navigate a mind-boggling range of options. "If you thought of all the different kinds of salads that you could make, and you presented [customers] all the different options, people wouldn't be able to deal with that -- there would be too much variety," she says. "But if you do it the way [restaurants] do with salad bars, and divide salads up into attributes ... they can deal with that variety because they can deal with those different attributes."
... ... ...
Companies that take the quick route to de-proliferate their offerings in an attempt to reduce complexity might end up returning to the same situation two years later, according to Wilson. That could lead to another danger, he says, of "cutting too shallow or too often." He warns companies not to underestimate customers' memory of portfolio changes. "The last thing you want to do is reduce some of the complexity, and then two years later tell the customer, "We didn't do it properly the last time; we're doing it again."
Oct 25, 2006 | Knowledge@Wharton
Special Section 'Smart Growth': Innovating to Meet the Needs of the Market without Feeding the Beast of Complexity As companies struggle to innovate in today's competitive environment, they need to continually guard against adding to their "clutter" -- the creeping impact of complexity on efficiency and cost-competitiveness. In this three-part special report, experts from Wharton and George Group Consulting discuss how management can approach this problem by thinking "ambidextrously" -- that is, focusing on innovation and broad exploration while minimizing the impact of clutter on operational processes and costs. Also, in the accompanying podcast (with transcript), Mike McCallister, CEO of Humana, discusses balancing innovation and complexity in the health care industry. http://knowledge.wharton.upenn.edu/special_section.cfm?specialID=58
Part I: Innovation vs. Proliferation: Getting to the Heart of the Customer How can companies innovate without falling into the trap of needless proliferation in their products or services? The key, according to Wharton faculty and experts from George Group Consulting, is understanding unmet and unarticulated consumer needs while aligning innovation processes to those insights. http://knowledge.wharton.upenn.edu/article/1585.cfm#part1
Part III: Getting a Grip on the Costs of Complexity Determining the financial impacts of innovation-related complexity begins with taking a close look at existing operations to understand the actual cost incurred and value generated at each step in the process -- all the way from idea generation through product development, manufacturing, marketing and customer support, among other back-office functions. http://knowledge.wharton.upenn.edu/article/1585.cfm#part3
May 1, 2005 | EiffelWorld
The power of simplicity (May 2005)
The best defense against falling prey to technology fashion is to be skeptical of complex solutions. Is the complexity warranted? Sometimes it is, but often it's just a smokescreen to hide the existence of simple and effective answers. Take the basic idea of object technology: to use the power of software modeling techniques -- essentially, abstract data types -- to describe systems of just any kind.
The idea was there from the beginning, and Eiffel took it to its full development thanks to Design by Contract (and multiple inheritance, genericity, deferred classes, Uniform Access, More...
July 04, 2005 | Computerworld
You have warned that we are "hitting a wall of complexity." What do you mean? We once arrogantly thought that any man-made system could be completely understood, because we created it. But we have reached the point where we can't predict how the systems we design will perform, and it's inhibiting our ability to do some really interesting system designs. We are allowing distributed control and intelligent agents to govern the way these systems behave. But that has its own dangers; there are cascading failures and dependencies we don't understand in these automatic protective mechanisms.
Will we see catastrophic failures of complex systems, like the Internet or power grid? Yes. The better you design a system, the more likely it is to fail catastrophically. It's designed to perform very well up to some limit, and if you can't tell how close it is to this limit, the collapse will occur suddenly and surprisingly. On the other hand, if a system slowly erodes, you can tell when it's weakening; typically, a well-designed system doesn't expose that.
So, how can complex systems be made more safe and reliable? Put the protective control functions in one portion of the design, one portion of the code, so you can see it. People, in an ad hoc fashion, add a little control here, a little protocol there, and they can't see the big picture of how these things interact. When you are willy-nilly patching new controls on top of old ones, that's one way you get unpredictable behavior.
The Fishbowl
A storm in a teacup was launched last week by an ONLamp.com article making wild claims about Ruby on Rails:
What would you think if I told you that you could develop a web application at least ten times faster with Rails than you could with a typical Java framework? You can-without making any sacrifices in the quality of your application! How is this possible?
I'm not going to be drawn into the Rails vs The World debate. Rails may be wonderful. It may make me significantly more efficient than I would be coding in Webwork. and Java. I've not tried it beyond throwing together a toy application, and I'm going to withhold judgement until I've done something serious with it. But I can categorically say that Rails is not going to make me ten times more efficient. When I encounter this sort of hyperbole, I always find myself returning to the words of Fred Brooks:
But, as we look to the horizon of a decade hence, we see no silver bullet. There is no single development, in either technology or in management technique, that by itself promises even one order-of-magnitude improvement in productivity, in reliability, in simplicity. - Fred Brooks, No Silver Bullet
The core of Brooks' argument concerns complexity. Writing software is a complex business, and it essentially comes down to the combination of two types of complexity: Essential complexity is the complexity inherent in the problem being solved. Accidental complexity is the complexity that derives from the environment that the problem is being solved in.
Consider an impossibly perfect tool that reduces accidental complexity to zero. For this magical tool to give you a ten-fold increase in productivity, that would have to mean that you are spending 90% of your time fighting your current tools, and only 10% of your time solving the problem you are coding.
I've been in one or two truly pathological environments where I've felt like this (usually involving EJB 1.1), but you have to do a lot of concerted work applying layer upon layer of antipatterns to get the ratio that high.
This is precisely why demonstrations are to be taken with a grain of salt. Any task that can be performed in a demo must necessarily have an essential complexity close to zero: it's a solved problem before the demo even begins. So if one vendor's demonstration takes a tenth of the time as another vendor's, all that time is accidental complexity.
And even the accidental complexity of a demo is usually of a totally different nature to that you'd encounter on a real project: the kind of complexity that accrues around a task that can be completed in the course of a lecture is vastly different to that which is encountered in a year-long multiple-developer project.
to tie pre-built web services together with the click of two buttons. Configuration is a much more significant overhead for a 45 minute "from scratch" or "here's something I prepared earlier" demo than it is over the lifetime of a real project.
It's like those debates about optimisation. "I just made this loop 10 times faster!" "Great, except we only call that method once a day."
A few years ago, a marketroid visited my then employer to give a demo of a recently re-launched IDE. The demo was very slick, showing how you could throw together an EJB project or a SOAP interface in a few clicks of the mouse.
Then, we started asking about the product's refactoring support, and the answer was "Oh, we don't have that." It was at this point the developers in the audience switched off. The IDE might have made it really easy to set up a web application skeleton or add new actions, but in any reasonably complex task you're going to be spending most of your time dealing with code. Refactoring tools only become necessary when you are iteratively refining your code: something you do constantly as you move towards the solution to the essential challenges of the programming task, but totally irrelevant to a slick, pre-packaged demo.
This isn't to say that improving processes, using more powerful languages and so on can't give you a significant advantage. If something makes you even ten percent more efficient, that's a huge advantage to have over your competition. But if anyone promises to make you ten times more efficient, they're discrediting themselves before they start, which is a disservice to all involved.
... ... ...
Why Do Research on Open Source Software?
Bill Thomas: Why do you think that open source software warrants research at this time?
Chuck Weinstock: One reason is that it appears that the community is treating open source software as the next silver bullet. We all know that silver bullets very seldom find their target, and the community moves on to the next silver bullet.
Pat Place: I would add that there is a substantial amount of software available these days that is open source. If you are interested in building systems out of existing components-be they open source or any other form of source-you need to understand at least the risks as well as the benefits of doing so. If we can say anything that helps, then I think that's a good thing.
Scott Hissam: The phenomenon that is happening with the Linux environment is getting everybody's attention to open source software-more attention than has ever been paid to it before, at least in the media. People are enamored and believe that Linux is a successful, stable development environment, and that somehow every piece of open source software that they get is going to be just as stable and just as reliable as the Linux platform-if you believe that it is as stable and reliable as it is touted to be in the press.
Jed Pickel: Open source has been around for a long time-probably more than 20 years. I think one of the reasons why it's getting so much attention now is because commercial interests are developing it. That's why we're seeing the media interest.
Is There a Community of Developers?
Dan Plakosh: You can release your source code, but I'm not sure people really know what to do with it. I released open source software two years ago and I've had very few people dive into developing it.
Place: It gets even worse when you get something that is hundreds of thousands of lines or a million lines. The historical aspect is interesting because you can look back at the history of programs that were open source, or close to open source, with lots of people helping and providing fixes. You can start to see what was successful about them and what is different about what is becoming the current open source movement, which I honestly believe is going to lead to disaster. I can provide anecdotal evidence of examples where you've got something like a tcsh [an expanded version of the original C shell for the UNIX operating system] which is not that complicated a program, but has features and peculiarities that are so weird that you'd never even want them. And yet somebody has said, "Oh, I'll just go and stick this thing into the system." For example, in tcsh, if you have time displayed as part of your prompt and it happens to hit the hour, it'll go "ding" instead of printing the time. I mean, this is insanity: feature upon feature upon feature that leads to code that's got more junk in it than you can possibly be interested in. It ends up becoming ultimately unmaintainable code.
Hissam: But I would say that the tcsh example that you gave is an unbounded development activity that nobody really paid attention to. Nobody really cared about it and that's why it got unwieldy. Not every piece of open source software is developed in that way.
Place: That's exactly true. I think that's the key to the difference between those things that have been and will be successful and those things that will not be successful. Somebody or some very small group of people have a very clear idea as to what that system is going to be, what it's going to do, and how it's going to be architected. And they keep it that way.
Weinstock: Some people refer to those people as the "arbiters of good taste."
Place: That's the phrase that was used primarily about the original UNIX developers. They were arbiters of good taste. With all of the stuff that people from all the universities shipped to them back in the mid-1970s and early '80s, they decided what went into the source and what was not in the source. For the longest time with Linux, Linus Torvalds [the Finnish graduate student who created the original Linux operating system] was the person who did that. He had a vision as to what it was going to be. That seems to be drifting out. Linux is perhaps losing some of that arbiter-of-good-taste quality.
Pickel: On your tcsh example: there are plenty of examples of closed source software having very similar things. For example, one commercial product is such that if you hit certain key sequences, you can end up with a flight simulator-which is a little bit different from tcsh beeping at the end of a line. The difference, though, is that should the community come across that item in tcsh, and feel like it needs to be removed, and there are enough people who agree with that, then it would be removed from tcsh. You can easily go and change that if it bothered you enough.
Place: Absolutely. I've done that because I wanted tcsh to be as small as possible and I've used it as small as possible.
Hissam: So you removed a whole bunch of things out of tcsh that you didn't like. Right? Now let's say the next version of tcsh comes out and you want to adopt it.
Place: I have developed the version of the shell that has the capabilities I need. If anything does come out in tcsh that I'm interested in, I might take that as a patch file and patch my source with those changes. But I'm not taking all their stuff again.
Weinstock: You now own the problem.
Place: Yes, absolutely. I willingly accept that. Of course, the advantage is that it was open source. I could choose to take on the risk and build something that was what I wanted.
Who Has Accountability for Open Source Software?
Thomas: It seems that no one has any accountability with open source software. It's strictly "buyer beware."
Pickel: I would disagree with that. Let's go back to the tcsh example again, because I think that's a good one in that a person maintains it and is accountable for listening to the users. Pat didn't speak up in this case. He decided to split off his own version and now he's accountable for that.
Someone wants the X widget or the Y widget, so they just go and put that fix in, and you get this loss of sanity.
Place: If you look at the actual source code, you'll see all of these different names of people who've added this and added that. The risk I see with open source is that all of these features are getting thrown into a basically good system. Someone wants the X widget or the Y widget, so they just go and put that fix in and you get this loss of a sense of stability of the project-this loss of sanity. tcsh going "ding" is kind of stupid. It goes to my notion of good taste; it's below the cut line.
Pickel: What you're describing is an example of open source working in the most optimal sense in that there are people who have different goals from a project than you do. You decide to split off your own version; that's open source working right there.
Hissam: It depends on what your own goals are. If your own goals are to keep up with the latest and greatest, then him vectoring off his own version-he's stuck.
Place: That's disaster if you want to keep up with the latest.
Plakosh: I don't think people develop open source software with the intent that people will take it and go off and build their own products from it. I think it's more so that people will contribute to mature whatever piece of software that they're doing.
Place: The freedom for anyone to make a change leads to the fact that the product will never mature because it will always be in a state of flux.
Plakosh: There is not the freedom for anybody to make a change. I really think you're looking at isolated cases. For example, take Linux. The majority of people who use Linux never look at the source. In the majority of most open source products, I would bet that people do not look at the source. They don't care. They don't recompile it. They don't want to have anything to do with it. It's only the people who are working toward the development of Linux who are looking at the source, or occasionally someone who has the in-depth knowledge finds a bug and looks at the source. They may fix it but they may also submit it to one of the Linux working groups to have it corrected.
What does it mean to be accountable?
Hissam: Let's go back to the earlier question about accountability. We disagreed about whether anyone is accountable. What does it mean to be accountable? It means that there's liability on the part of somebody.
Place: I wouldn't even go as far as that. Dan has released source. He's put his name up saying, "I think this is a good piece of source." In an open source project, other than a couple of special cases, there's a substantial body of existing code that gets released and then people can work on it, rather than working on stuff from scratch. I see a potential split there. Take Linux. Who is accountable for Linux these days? Does Linus put his name on it saying, "I think this is all good source code"? I don't think so anymore.
Hissam: No. The worst thing that can happen to the people who are "accountable" for Linux is that the world turns their back on it. But concerning accountability: I think the answer is that no one is accountable outright and I think it is buyer beware.
Weinstock: So that's why people go to places like [Linux vendor] Red Hat instead of just downloading it off the Web.
Hissam: Because they want to hand money to somebody. They want to be able to say, "Give me this and give me that."
Weinstock: Red Hat also sells support. You can go just buy a Red Hat CD and you get nothing with it other than the CD. But you can also go to them and get support for Linux.
Pickel: That's how Linux has made it into the corporate world: doing support.
Plakosh: I've dealt with support before and support is not typically all that it's cracked up to be. Support is usually geared toward people who have problems in reading the documentation or who don't understand things. Linux got into the commercial domain mainly due to the attractiveness of it being free and being somewhat reliable.
What Are the Benefits and Drawbacks of Developing Open Source?
Thomas: Let's backtrack a little bit here. What would you say are the benefits and drawbacks of developing software in an open source environment, from the standpoint of the developer?
Weinstock: There are different ways of looking at that. Why would I want to participate in the development or why would I want to put myself more out there for free...
Place: I'll tell you at least one person's motivation for the latter. For the last two years, he's been unable to further his software at all, so since it was previously freely available, he said, "Okay, let's make this an open source project in the official open source project way. We'll get people who have ideas and have some suggestions for developing this further, and/or who have bug fixes to be able to maintain this thing."
Hissam: So, would you say that the rate of change on this project has increased or decreased, and have those changes been dramatic?
Place: Well, it's certainly increased. There's also one place where you can get an official source version that has the bug fixes in it, which you couldn't do previously.
Thomas: Would you say that putting out a program with open source code is a way of testing the market for it?
Pickel: Exactly. That's another good point that I wanted to make. One of the interesting things about open source is that you build on other people's software. When you release something, you never quite know how other people are going to make use of it. You learn quickly that way because they give you immediate feedback and contribute changes. It's a great way to figure out market demand.
Hissam: That would be a benefit. But if that evolution is unchecked, you're going to get the tcsh phenomenon. It's almost like a cancer: cancerous features.
Pickel: You choose the branch of the code that most suits your goals at a given time.
Weinstock: But that presents the consumer with a real problem, right? Which branch? What happens to the uneducated consumer who doesn't have a basis for picking a branch?
Pickel: They go to places like Red Hat.
Place: If you want a version of BSD [a popular version of UNIX; BSD stands for Berkeley Software Distribution], which one do you pick right now? There are three versions of BSD that are all based upon 4.4, BSD Light, which was the last release. So which one do you choose?
Weinstock: Getting back to what you said about consumers going to Red Hat because they don't know how to make that choice: That's fine for an open source project where there is a Red Hat, but my guess is that most of them don't have a Red Hat. I mean, how do I know which Emacs to choose, for instance?
Plakosh: The only reason you have companies like Red Hat out there is because the distribution package for Linux is so large and so complicated-or at least it's viewed that way by the consumer. For a small piece of software, you're not going to have these distributors.
Pickel: Going back to your point about what to do if there is no Red Hat: I think these companies are out there for the purpose of infiltrating the corporate world-getting this kind of software into the corporate world. The techies and the geeks aren't necessarily interested in a Red Hat, though they may use it because they don't necessarily care to package all the software. But there are projects that don't have corporate backing behind them, or a very organized way of going about things. They're just not going to make it to as large an audience. They won't make it into the corporate world quite as easily.
Hissam: Every techie and geek on the planet right now, and every open source activity, started with dreams of IPOs [initial public offerings of stock]. They want to be the next millionaire. They want to start the next company.
Pickel: If you look at the past year or so, that might be one of the motivations behind open source software: people think they're going to make a killing off it. If you look over the past 20 years, there haven't necessarily been financial reasons. One of the ways you get paid for leading a successful open source project is by getting your name out there, by getting well known, by becoming the guy who started that project.
Is Open Source Right for the Department of Defense?
Weinstock: Let's talk about open source as applied to our Department of Defense client. What are the advantages of developing something using the open source model? When applied to the DoD, the notoriety factor is probably not important to them.
Place: There's another question that I should like to raise with respect to DoD customers. What systems do you envision the DoD would like to build with open source? Is it the weapons systems? Is it the payroll systems? How many people out there are interested in the payroll system?
Weinstock: It would seem to me that we're probably talking about subsystems first of all. Pieces of systems.
Place: So we're talking back at the level of things like the operating system (OS), the database, the underlying components-the bits that we take for granted. That's one of the issues, when we talk about DoD customers. We need to understand that they're not going to build systems with this stuff.
Weinstock: But they will build systems that contain parts.
Place: Then the question is, which parts? Clearly it's going to be exactly those things-the OS parts, the database parts, the GUI [graphical user interface] parts.
What Are the Criteria for Success in Open Source Development?
Hissam: We can go back to the premise that these large organizations, be they DoD or not, think that they can get something done with access to a large, talented pool of engineers. There's some belief that they can get access to a lot of peer reviews, beta testers, people out there to look at their software and make it better and get it done quicker. That seems to be the running belief. If that's a model of success in Linux, then it must be true for every piece of open source software. But we should debunk that. Past performance should not be used as an indicator of future performance. That's one of the reasons that the Software Engineering Institute has to start looking at the processes that are used in open source development. What are the criteria that have to be there in order for it to be successful?
Past performance should not be used as an indicator of future performance.
Place: There are instances of projects that have been very successful. I would claim that Linux certainly has been one of them. It has achieved a level of reliability. The BSDs are reasonably successful, and some other open source things are reasonably successful. One of the common themes I've seen through either open or freely available source projects over the last 20 years is that there has been a substantial body of software-i.e., the system is basically there-before its release. People are bug fixing rather than developing new features, so that you've got a system with a structure and a design, and other people are now fixing the things that "he forgot" or that "he got wrong."
Weinstock: That suggests that it should start off with a user base or some sort of base of people who care about it.
Place: You certainly need people to care about it, and the people who care about this typically are the users.
The user base of Linux was people who developed software, not users of software, per se.
Plakosh: But if you look at how Linux kicked off, it kicked off by being more or less the toy of software engineers to build upon. It came with a lot of people's research projects. There were a lot of people looking at this functionality and that functionality. The user base of Linux was people who developed software, not users of software, per se.
Place: That's a good point. The other thing, in thinking about what has been successful, is that the initial release was something that was a well-designed system.
What Are the Advantages to the User?
Thomas: Let's talk a little bit about open source from the user's perspective. What are the advantages to using open source software?
Hissam: Let me start off by cutting to the chase. It's a two-edged sword. The advantages are that users can get the latest and greatest and the fastest fixes. The disadvantages are that they have to get the latest and greatest and the fastest fixes. They might spend 75% of their time using a product and 25% of their time upgrading the product.
Just because a product is out in open source doesn't mean that I, as a user, have to track it.
Plakosh: That's not necessarily true. Just because a product is out in open source doesn't mean that I, as a user, have to track it. There are a lot of internal releases that I don't need to worry about or that I may not want to worry about. That perspective is somewhat from the mentality of the world that we live in, developing software.
What Are the Security Implications of Using Open Source Software?
Pickel: From a security perspective, you could look at it from a couple of standpoints. You really have to pay close attention to the software because if the community becomes aware of a vulnerability, then they're going to exploit it. So you need to beat them.
When you were talking about the double-edged sword, I realized that it also applies to the perspective of the developers in that there's an advantage to having people working on your software, but you also have to be ready to deal with them. If you have a lot of demand, and a lot of people developing your software, it's going to be tough to deal with them.
If the community becomes aware of a vulnerability, then they're going to exploit it.
Place: You raised the issue of security. What trust do you place in open source software, given that it's changing so rapidly? How much analysis can you do on the 5,000 fixes that came in last week?
Weinstock: Do you use Linux in a secure environment?
Pickel: Absolutely. Actually, I run Linux on all my machines. I'm not going to look at every single line of code. I'm not going to look at every update. But the thing is that there are people out there who are.
Weinstock: You hope. Do you believe that every nook and cranny of Linux has been looked at with that in mind?
Pickel: Not necessarily. But I believe that a lot more nooks and crannies have been looked at than are looked at in closed source environments.
Plakosh: That's an interesting statement because I would tend to bet that there is a difference between theory and practice. In theory, you would think that you're releasing source and you would have people combing over the code looking for security holes and trying to fix them. In practice, I don't think that's necessarily the case. In theory, it sounds great: the more people have it, the more people are looking at the source code and the more people are going to try to find bugs or security holes so that they can try to fix them. That sounds great. In practice, I think the only people who are trying to do that are maybe people who are trying to break into a system.
Pickel: Exactly. And they're part of the community. If they identify a hole and start exploiting it, people will notice that.
Hissam: You're saying that even the bad guys, in a sense...
Pickel: ...they're part of your development.
Place: But you only find out after the fact.
Pickel: That's still a better environment than closed source.
Plakosh: Actually, that's not necessarily much better because some of these holes that you can find in open source code you never would have found if it was closed source. They never would have existed.
Hissam: If I were a hacker, I could get the latest distribution from Red Hat, go to my garage, close the doors, get a lot of Twinkies and Coke, and start mulling over it until I can find a hack. Then I can just turn on my modem and go attack somebody who's using Linux.
Pickel: Certainly, there's some potential of administrators not noticing. This is an issue that we deal with every day in the CERT® Coordination Center. It's quite common that somebody will break into a site and the site administrators don't know how it happened. But when you deal with the sophisticated administrator, you can usually track down what program was the source, the problem. Then, maybe there's a new vulnerability in that. So, a lot of times, we look through the vulnerabilities, get in contact with vendors, and have the problem fixed. So there, in that situation, a few people were compromised. But the community as a whole is now operating on more secure software.
Place: Then there is the difficulty of getting customers to upgrade with the patch. Don't underestimate the number of people who are behind the curve.
Thomas: Is it any better in a closed source situation?
Hissam: Closed or open source, when a vulnerability is discovered, people have to react. I think the other thing that is interesting is that a hacker can become very intimate with some of the underlying protocols that are used. There may be that somewhere in the code it says, "You'd better check for null value here and the packet header for this because if you don't you could lock up the machine." The hacker says, "Wow! I hadn't thought of that before. If I tried this against Windows, I wonder what it would do?" Just by reading the source code, they could learn some very sophisticated, obscure attack.
What Comparisons Can Be Made Between Open Source and COTS?
Weinstock: There's also a big push to use COTS [commercial off-the-shelf] software, and widely using COTS raises all sorts of problems. At least some of the same arguments that apply to COTS apply to open source software.
Place: You might get an instability argument more so with open source than with COTS.
Plakosh: You'll get quality arguments too.
Weinstock: But it's the argument that "you own the solution if you try to modify it in any way."
Hissam: Let's say a contractor is using open source in a government program and they're having some success. Then they run into a roadblock. They decide, "All I have to do is change this one line of code and we'll save the government millions of dollars." And they do it. Now let's say the open source community doesn't want to adopt that change because it's very specific to whatever the government is doing. Now the government-by virtue of a contractor-is in the business of maintaining and competing with that open source.
Plakosh: That may or may not be true. I think one of the best advantages to me as a software developer is to take somebody else's open source and save development time, if it does do that for me. And I don't intend to track it in the future.
Weinstock: Yes, but suppose there's a security compromise that's found in some future version and the four-star says, "That rolls back to the version you modified seven years ago-or six months ago." Now you've got to find someone who's even smart enough to put the changes in.
Plakosh: No you don't. You've taken over maintenance of that. That's fine, and you move on.
Weinstock: And the technician who worked on it seven years ago is still there, on the payroll, and there ready to help?
Plakosh: No. But we're just talking about another method of software reuse. You're equating it to a product and having to track versions, rather than someone looking at open source software and saying, "Man, I could use these features. Let me rip them out and use them." You've taken the code from an open source product and reused it elsewhere.
Weinstock: But you've lost a supposed benefit of open source, which is that vast community of developers.
Plakosh: But if you weren't interested in that, it doesn't matter. You've gained. You didn't have to write that. You didn't lose anything. That's the benefit to a lot of people who are using open source. They don't have to reinvent the wheel. Somebody's already invented it. Yeah, I have to maintain it. Yeah, I'd better take a look at what I'm getting. Yeah, I'd better check the quality of it.
Weinstock: I'm not disagreeing with you. That's certainly a valid, good thing about open source. But if the whole world had that view of open source, there wouldn't be open source. All I'm saying is that it's sort of outside the spirit of open source as I see it.
Plakosh: What's the spirit of open source? Open source has two motives. One is that you want other people to work on your code; you want resources. So you want to obtain free resources.
Weinstock: Right. And you taking the code and going you own way and not feeding back to the community does not accomplish that.
Plakosh: But that's one motive. It's for your own-how can I put it-personal glory, corporate gain, whatever. The second advantage is for other people just to advance technology and to advance people's growth. People give things out so that some other people can learn how to do something. For other people, it fosters new ideas. That's why I give out source code. I don't do it for my personal gain. I do it so that other people can look at it and use it for whatever they want to use it for.
Weinstock: That's from a developer's perspective.
Plakosh: I think it's great if someone reuses and finds benefit from something that I wrote, and if it saves them some time. Just like if I'm going to write a piece of software, I go out looking. I'm not going to try writing everything from scratch when I know that there is software that I can lift.
Pickel: The real benefit of open source, in my opinion, is that you build on things that are already available. You're furthering technology, and then people build on what you've done.
Place: You get the function you want as well. That's the other thing. If you're buying from Chuck's House of Software, you get what Chuck wants to sell you, not what you want.
Pickel: But you do have to be a developer to get that. I've been a user/developer of these things for a long time. If you're not a developer, you don't get it. I suspect that one of the results of this is that there will be more people who are developers out there. It's going to convince more people to look at the source code.
dec.bournemouth.ac.uk
Forth is not just a language, its more of a philosophy for solving problems. This can be summarised with the acronym K.I.S.S. (Keep It Simple and Stupid). To quote from Jerry Boutelle (owner of Nautilus Systems in Santa Cruz, California) when asked "How does using Forth affect your thinking?" replied:
Forth has changed my thinking in many ways. Since learning Forth I've coded in other languages, including assembler, Basic and Fortran. I've found that I use the same kind of decomposition we do in Forth, in the sense of creating words and grouping them together. For example, in handling strings I would define subroutines analogous to Forth'sCMOVE,-TRAILING,FILL, etc. More fundamentally, Forth has reaffirmed my faith in simplicity. Most people go out and attack problems with complicated tools. But simpler tools are available and more useful. I try to simplify all the aspects of my life. There's a quote I like from Tao Te Ching by the Chinese philosopher Lao Tzu: "To attain knowledge, add things every day; to obtain wisdom, remove things every day".
reese.king-online.com
If we as a species are going to survive, we are going to have to learn to live simpler lives. By that I mean consume less stuff. The world's poor are already living simpler lives, and not by their own choice, so it's up to us in the industrialized countries to set the example.
OK, I know this sounds preachy and far-fetched, not to mention being highly unlikely to influence anybody. Nevertheless, sooner by choice or later by necessity, we will have to recognize that we are, if we continue the present trend and lifestyle, going to consume our own planet. Our ancestors will look mighty funny one day clinging to the solar system's only orbiting trash dump while trying to choose between garbage and cannibalism as a source of food.
Consult any almanac and look at the exorbitant rate at which we are pumping oil, mining coal and other minerals, cutting forests, catching fish and dousing the land with ever-increasing amounts of fertilizers, pesticides and herbicides. There's no question we are just now beginning to run short of a lot of natural resources. The price of oil is just one example of what's in store for us unless we curb our appetites.
Ravenous consumption was rather all right when the world population was only a billion, and few of them wealthy enough to afford much stuff. The Industrial Revolution changed all that. Utilizing fossil-fuel energy, it did raise the standard of living, and people began breeding ever more prolifically. Today, there are 6 billion people, and practically every one of them aspires to consume at the Donald Trump level. Cheap electronics make sure that nobody is ignorant of how the fat cats live. Even in the Amazon jungle, they watch "Baywatch.''
Europe, Russia, the United States and Japan have long been consuming at a rapid rate, and now two more giants are coming on line, so to speak, as India and China develop their massive economies, which is to say their appetites for energy and commodities. Then there are the so-called Asian tigers - Malaysia, the Philippines, Indonesia and Korea - all determined to raise their standard of living to the level of the West.
Well, we'd get nowhere asking anyone to remain poor as a conservation measure. What the world needs is a new lifestyle of elegant simplicity, so that people will learn to aspire to a few well-made items that can be used and passed on instead of junk, which is discarded as soon as it begins to wear or break down.
I include myself in criticism of overconsumption. I fancy myself on the low end of consumption. I care nothing for jewelry, clothes, fancy cars or furniture. The latter two things I tend to keep until they fall apart. But I have a weakness for books. There are books all over my little condo - five bookshelves, one covering a whole wall to the ceiling, and more books stacked on coffee tables, end tables and the floor.
On one little shelf between my dining/living room and the kitchen, I can see six sandstone coasters, a plastic timer, a bottle of glass cleaner, two candy dishes, a plastic globe, a rack for hanging bananas, a flashlight, four candles, a plaster-of-Paris Nefertiti, a bottle of Tabasco, a plastic watering jug, 11 cookbooks, a pipe rack with pipes and tobacco, a plate with a portrait of Robert E. Lee, and a kerosene lamp. That's one stinking little shelf. What do I really need? Maybe the flashlight and the Tabasco sauce. I haven't smoked a pipe in years and never cook anything more elaborate than fried eggs and baloney sandwiches.
Let's face it: Most of us, even us lower-middle-class types, lack consumption discipline. We get led astray by the singing sirens - new, more, bigger and upgraded. We need to seriously cut back, lest our grandchildren inherit a used-up, worn-out planet. And not just us - the whole world must reduce consumption, though of course about a fifth of the people still need basic food and housing.
Let us all try to simplify by decluttering and then avoid recluttering. Good luck to us all. We'll need it.
discuss.fogcreek.com
On the topic of software bloat, it would help to distinguish between size bloat and processor cycle bloat. With regards to size, the more features you pile on, the bigger your code footprint will become. Just as mentioned by Joel, the cheaper disk space becomes, size bloat becomes more and more negligible. Processor cycle bloat is typically brought about by software layering. To get something done, you end up calling layers and layers of software.... most of which add little to what you need to do. I come from a c/c++ background so yes, I did knock VB, Perl, and other scripting languages around for a while with regards to their performance aspect. However, I am finally recognizing that all the above languages have become so pervasive in the programming world.
In the miniscule world where microseconds matter, size and speed matter. This used to be the perception and programming accumen used to be how tight you can keep your code. You tell me what the new perception is.
www.tek-tips.com
I'm going to start with a tip before I rant. The Acrobat Reader speedup tool available here ( http://www.tnk-bootblock.co.uk/ )really works. It disables loading a unnecessary plug-ins at startup.
<rant>
Why is this tool even necessary? This proves that code bloat exists everywhere, not just at MS. Why in the world would you need to load 75 plug-ins by default at startup - in a simple reader? This is just pure lazy progamming.I understand the pressures of time-to-market quick delivery. I also understand that there is a lot of overhead involved when you are trying to develop re-usable OO code versus hand-crafting an application. This type of thing is inexcusable however. IMHO Adobe is worse than Microsoft lately in producing applications that give you time for a beer break while you're waiting for them to load. AutoCad and other are not necessarily speed demons either.
I've read estimates that the final Longhorn, running full Aero, Indigo and WinFS will need a base machine with 1GB of RAM to run decently.
Linux may be cleaner and more stable , but if you go look at recommended systems, the requirements aren't that much different than Windows.
There's got to be a better way.
</rant>Oops, I have to start a program up - might as well go have a beer....
Tarwn (Programmer)
Sep 10, 2004 Uh oh, you brought up Linux vs Windows :)
I'd argue the point on requirements but I am sure someone else will bring it up.
I agree on insane bloat though, I'm noticing it everywhere. Load the new ATI hardware drivers and the .Net-based control panel will eat up some more windows loading time as well as huge chunks of memory...it's a settings util, why would a settings util be forced to load on startup? Obviously I need the drivers, but please, I shouldn't be forced to hack my registray just to make the settings console stop eating my memory...
Firefox: I love the browser, I hate the fact that is is sitting on 67Mb of RAM right now...
STEAM: (for half-life players) Choke, cough cough...the release version wasn't even adequate to call a beta version but that aside, we have hidden loadup when the system starts and 23-24Mb while running in the taskbar (dunno about normal background, I killed that reg entry :P)
MS Word...Outlook still takes foever to start up, word takes a litle while, so what is MS Word doing with 22Mb of my memory?
MS Outlook: Apparently not everything is covered by MS Words 22Mb, so here's another 13Mb for my mail program...
WinVNC: Now this is what I'm talking about...4Mb. VNC is running as a server and using less then 1/5th of the memory that MS Word is....and I haven't opened anything since rebooting except Outlook, Editplus (1mb), and Firefox...
So yeah, I agree that bloat is everywhere...but machines keep getting faster and RAM keeps getting cheaper so companies feel justified in cutting corners to bang out bloated software, the bloating probably isn't even an effect of time limits anymore, probably bloated by design (or lack thereof)...
Our mission is to provide fast, efficient, reliable software that exceeds peoples' expectations.
...yadda, yadda, yadda.
Okay, almost every software company has a similar mission statement, and in most cases it's a hollow sentiment that flies in the face of how it really does business. How many times have you bought software that was so buggy that you thought you must've accidentally installed a pre-beta version? And how many hours have you wasted downloading bloated software that made your high-powered system run like a narcoleptic slug on downers?
If you're like us, you're tired of this. So, rather than bore you with our mission, we'll tell you...
- Our products will go through extensive beta testing involving dozens of external testers. We will not release our software until these testers tell us it's ready.
- If serious bugs are reported in the current version of our software, we will not make you wait (and pay!) for the next version to see them fixed. Fixing bugs in the current version will always take priority over the release of the next version.
- We will build our software based on the needs of our customers. We maintain an online forum where we take feature requests, and when it comes time to work on the next version, we enable you to vote for which of these features you want to see.
- Our software will always be system-friendly. TopStyle and FeedDemon are perfect examples of this. They install no shared DLLs, ActiveX controls or other system files. Since they're self-contained, you can install them without fear of them interfering with your system or with other applications.
- We will keep our software fast and compact. Too many products are extremely slow and bloated beyond reason, filling your hard drive and wasting system resources. TopStyle and FeedDemon load very quickly so you can start using them immediately, and they're also surprisingly compact.
Builder UK
Light methodologies rely on quickly iterative design cycles to fulfill their promise of rapid development and smart solutions. But how quick can you be if you're using plodding design tools or wading through reams of cumbersome, overwrought code?
A key aspect of light methodologies is their need for simplicity. All light methodologies value simplicity over complexity whenever possible. Use that one tool that satisfies 80 percent of your needs instead of adopting three tools to cover 100 percent of your wish list. If you can use 50 lines of simple code to substitute for 25 lines of elegant code that only you can understand, go with the 50 lines. When you design an application, do it as cleanly and simply as possible.
Simple design and coding
The overall design of your application needs to be simple and flexible. Avoid design decisions that are perfect for your first iterations but then don't allow you to add features and functions in later iterations. This can happen if you tie program components too closely together, instead of maintaining a level of independence.
You also don't want to overengineer a solution. If you're building 100 reports for your application, you probably need some sort of user library structure to keep track of the reports and what they do. But if your solution requires just 10 reports, drop the library.
Your code needs to be simple to review and to understand by others who follow you. If you look at the total life cycle of an application, only about 20 percent of cost is spent during the development phase. The remaining 80 percent is spent in the support and maintenance phases. If you build a no-frills application, the code might run in production for 10 years or more. Simple and straightforward code written up front allows easier learning curves, error fixes, and enhancements over the entire life cycle.
Simple program documentation
Writing documentation is the bane of many programmers. First of all, many programmers are great with computer languages but aren't very strong with English. Secondly, programmers tend to write their comments and notes for themselves, not someone else who will need to understand them.Light methodologies tend to advocate essential documentation, but no more. This minimalist approach recognises the inherent limitations of documentation.
Take program documentation, for instance. If you're trying to track down problems in code, you're not going to be able to find the problem in a programmer's manual. The only place you'll find the bug is in the code itself. Even if the customer asks you to investigate how a feature works, you typically can't rely on an external programmer's manual. The only way to know for sure is to check the code. So having a stand-alone programmer's manual that describes the code probably doesn't make sense.
On the other hand, the code itself should have plenty of comments. These comments shouldn't reflect the obvious but instead should point out creative techniques or describe major sections of code that enable certain features and functions.
Programmers might also be asked to assist with users' manuals and help features. Again, you should convey a basic understanding to others that are not involved in the project. In many cases, large users' manuals are created but only certain parts are ever referred to again. Work with your customer to anticipate the basic documentation needed and build at that level. The more extravagant the documentation, the more content will never be referred to again.
Simple specifications
All of us have heard about the 80/20 rule. Perhaps 80 percent of an application's business logic can be coded in 20 percent of the total development and testing time. Light methodologies rely on users really accepting the 80/20 philosophy. It's true that you don't want any sequence of user logic to result in errors or an application failure. However, you may not need to create an elegant recovery strategy for every possible input combination. For obscure error combinations, maybe it's acceptable to simply point out to users that they have made a mistake and need to start the transaction again.
In the same way, users sometimes ask for every feature and function that they might possibly need over time. The better approach is to look at must-have requirements and then build the application to those specifications. In many cases, extra features will not be utilised often. If some borderline features do prove to be absolutely necessary, they can be added into future iterations or as enhancements after the project is complete.
Rank priorities as low, medium, and high, and then agree that no low-priority work will be incorporated in the project. You can note the requirement to show that it was considered, but there's always something more important to work on than a speculative feature that will not be needed when the application goes live. Again, if the requirement is important, write it down, but as an item to be considered later, not to work on at this time.
It's as easy as you make it
Light methodologies tend to falter when applied to very large and very complex projects, which require more rigor and structure. On the other hand, sometimes we make projects larger and more complex than they need to be. When you are working with your customer on a development project, try to always think simply. Think about implementing the basic requirements, in a simplistic manner, rather than trying to create a solution that meets 120 percent of the business needs. You may have heard the saying that "better is the enemy of good." You can always make things better and better, but your sponsor will be more than happy with a good solution that is delivered on time and on schedule.
discuss.fogcreek.com
The recent threads posted on quality of life balance, software overcomplexity (which diminishes job satisfaction), and the repetitive nature of SW practice, impels me to comment.
Basically, it seems that when topics like this arise, the opinions that most programmers contribute all tend toward pretty much the same set of conclusions and values. (note, I didn't say "all". The insightful few who question the status quo are usually torn to ribbons and personally attacked.)
My conclusion is that most programmers are personally half satisfied to miserable, but due to peer or self imposed pressure decided a long time ago that beating their heads against a brick wall was the only honorable thing to do. It's kind of a Spartan code of ethics, among an occupational group that never seems to have any profile with anyone outside the field.
Basically, it's the falling on a sword and impaling yourself while nobody else gives a sh*t.
And the sameness of most people's opinions forces me to conclude that we're a bunch of robots. Most of us adopt the thinking of our age group.
A few gems that always come up:
- Career "should be" about survival through a series of projects, not about growing personally, self satisfaction, fulfillment, or feeling that the work is ultimately important.
- Burnout doesn't and shouldn't count. If you are burned out it's because you are too stupid to find cool new things to do. Keep doing your job even if you hate it.
- "More" technology and newer technology is always, invariably better. If the newer technology is more fragile and less reliable than legacy technology, then deny that the older technology ever solved worthwhile problems or was cost-effective.
- Countless hours of self-directed learning that is only an arbitrage against a *POSSIBLE* (not even a likely) future job is expected. We can't ever know what the next technology fad will be, so we are expected to devote training time blindly.
- Overwork, 24x7 standby, and long hours for nominal salary are your duty.
- Abstractions are always good. More abstractions and levels of indirection are better than fewer. The reason for this is that the more abstract code becomes, the more that you feel that you're the lord and master of an intricate little universe. The "best" code in this vein is written around the platform that assures you that you have absolutely no idea what a programming statement will do in the real world.
- Identify people's value and personalities with their implementation technology of choice. IE: An Access guy is shallow. A COBOL or RPG developer is too stupid to learn new stuff. A device driver or kernel developer is a weirdo.
- Anyone older than you in this field, with more experience, is always a dated loser. They are "jaded", "negative", not with it, and are complaining because they have been screwed because they really deserved to be screwed. And, because everything is altogether different today, their opinion on past projects is *NEVER* to be considered. After all, much smarter people develop J2EE or Win32 applications today than those who developed COBOL in the old days.
- Anyone younger than you has no right to their own opinion. Someone younger than you is shallow, lacking wisdom, hasn't worked on enough dozens of projects to finally develop the chops to be able to comment. Once that person does "ascend bodily into heaven", they drop into the "old loser" category described above.
ZDNet PC Week
These days, more and more IT managers are discovering that, in the age of pedal-to-the-metal e-business, architectural complexity doesn't work. Historically, many organizations have, like SIAC, created multiple networks, each with its own firewall and security system. To get e-business efforts off the ground, for example, many enterprises ended up supporting two network architectures: a legacy network supporting internal processes-finance, inventory management, etc.-and another for extranet operations that link to customers, suppliers and partners. However, that kind of complexity makes it difficult for companies to transform themselves into e-businesses. Multiple layers of security and authentication, for example, make it all but impossible to open inventory and other back-end systems to customers, partners and suppliers online. And maintaining all that architectural complexity is becoming increasingly expensive, IT managers say.
So, like Solomon, many organizations are seeking to simplify. They're trying to build unified IT architectures that provide common, enterprisewide security, authentication and data exchange services using Web-oriented technologies such as LDAP (Lightweight Directory Access Protocol), metadirectories, XML (Extensible Markup Language), the CORBA (Common Object Request Broker Architecture) distributed object framework, PKI (public-key infrastructure) security and authentication schemes (see chart.) That means giving users-whether employees, customers or partners-a single way to get to corporate information. And it means a single, less expensive approach to system management.
There are still plenty of roadblocks between enterprises and unified architectural simplicity. Standards such as LDAP, XML and PKI must be more completely defined and implemented in products. Many IT managers also admit that they still have concerns about security, concerns that loom large as they contemplate building simpler, unified architectures. And, as some IT managers are finding, business managers can become impatient with the expense and time it takes. For those reasons, the simpler, unified architecture is still a few years off for most companies. However, according to experts, many are moving in that direction.
"From a trend standpoint, we've seen a number of companies who've begun the process of collapsing and standardizing their architectures," said Andrew Kelemen, an analyst with CNS Group, in Norwalk, Conn. "All of a sudden comes this blurring of the lines between intranets and extranets."
...Some vendors are taking note of IT managers' desires for simple, unified architectures based on Web technologies that can run across multiple platforms. Companies such as Entrust Technologies Inc., Netscape Communications Corp. and Novell Inc. have touted versions of key services that will run on a number of operating systems. Entrust's PKI products, for example, can work with directory services from Netscape, Novell and a variety of vendors via LDAP.
"The maturity of newer technologies will have to happen before enterprises fully deploy such an infrastructure," CNS Group's Kelemen said. "But as users begin to push for this infrastructure, they will in turn push vendors to adopt standards by requiring compatibility, integration and support."
...But why change something that already works? Anderson said the cost benefits of a more unified network architecture are too high to overlook. Staff and training expenses alone could be trimmed significantly if Duke could deploy unified, centrally managed architectures, he said.
Besides politics and a lack of vendor support for standards, concerns about security continue to pose a barrier to the merging of extranet and intranet architectures, Kelemen said. Although companies have willingly allowed partners to access information via extranets, the idea of extending their own infrastructures into somebody else's enterprise is still viewed as risky, he said.
"Right now, it's simple if you have two network architectures," Kelemen said. "You're going to authenticate at the account level, maybe using some kind of directory service. But as far as actually allowing some third party to access proprietary information within their own organizations, many IT managers are still balking."
Now, CIOs at a group of large companies are joining to pressure IT vendors to help solve the problem. Last year, 15 member companies of the Society for Information Management formed a working group to reduce the level of complexity in IT systems. They want vendors to support standards that will help make building simpler, unified IT architectures easier. The group includes companies such as AT&T Corp. and Kraft Foods Inc.
Not every member of the SIM working group is moving toward the goal of a unified architecture capable of handling both intranet and extranet needs. But each company has a stake in making it simpler, less costly and less time-consuming to integrate systems from multiple vendors, said Steve Michaele, district manager of foundation architecture at AT&T and the group's leader.
"We've got legacy environments we need to connect to and multiple hardware platforms that we're supporting. All of that is a complex infrastructure to manage," Michaele said. "Now that we're trying to leverage that infrastructure in a Web environment, we need these applications to be interoperable."
The IT Complexity Reduction Group's goal is to develop a series of standards documents to send to key hardware and software vendors. The documents give vendors outlines of which member companies want vendors to provide interoperability for products and languages.
At SIM's annual meeting last month, the working group presented areas where a unified approach is required and some of the standards it wants vendors to adopt. Every area of concentration is one with which members have problems with integration and standards such as directory services and security.
For more information, go to www.simnet.org.
Dec 17, 2001 | InformationWeek
Reader Randy King recently performed an unusual experiment that provided some really good end-of-the-year food for thought:
I have an old Gateway here (120 MHz, 32 Mbytes RAM) that I "beefed up" to 128 Mbytes and loaded with -- get ready -- Win 95 OSR2. OMIGOD! This thing screams. I was in tears laughing at how darn fast that old operating system is.
When you really look at it, there's not a whole lot missing from later operating systems that you can't add through some free or low-cost tools (such as an Advanced Launcher toolbar). Of course, Win95 is years before all the slop and bloat was added.
I am saddened that more engineering for good solutions isn't performed in Redmond. Instead, it seems to be "code fast, make it work, hardware will catch up with anything we do" mentality.
It was interesting to read about Randy's experiment, but it started an itch somewhere in the back of my mind. Something about it nagged at me, and I concluded there might be more to this than meets the eye. So, in search of an answer, I went digging in the closet where I store old software.
Factors Of 100
It took some rummaging, but there in a dusty 5.25" floppy tray was my set of install floppies for the first truly successful version of Windows--Windows 3.0--from more than a decade ago.
When Windows 3.0 shipped, systems typically operated at around 25 MHz or so. Consider that today's top-of-the-line systems run at about 2 GHz. That's two orders of magnitude--100 times--faster.
But today's software doesn't feel 100 times faster. Some things are faster than I remember in Windows 3.0, yes, but little (if anything) in the routine operations seems to echo the speed gains of the underlying hardware. Why?
The answer--on the surface, no surprise--is in the size and complexity of the software. The complete Windows 3.0 operating system was a little less than 5 Mbytes total; it fit on four 1.2-Mbyte floppies. Compare that to current software. Today's Windows XP Professional comes on a setup CD filled with roughly 100 times as much code, a little less than 500 Mbytes total.
That's an amazing symmetry. Today, we have a new operating system with roughly 100 times as much code as a decade ago, running on systems roughly 100 times as fast as a decade ago.
By itself, those "factors of 100" are worthy of note, but they beg the question: Are we 100 times more productive than a decade ago? Are our systems 100 times more stable? Are we 100 times better off?
While I believe that today's software is indeed better than that of a decade ago, I can't see how it's anywhere near 100 times better. Mostly, that two-orders-of-magnitude increase in hardware speed is not matched by anything close to an equal increase in code quality. And software growth without obvious benefit is the very definition of "code bloat."
What's Behind Today's Bloated Code?
Some of the bloat we commonly see in today's software is, no doubt, due to the tools used to create it. For example, a decade ago, low-level assembly-language programming was far more common. Assembly-language code is compact and blazingly fast, but is hard to produce, is tightly tied to specific platforms, is difficult to debug, and isn't well suited for very large projects. All those factors contribute to the reason why assembly language programs--and programmers--are relatively scarce these days.Instead, most of today's software is produced with high-level programming languages that often include code-automation tools, debugging routines, the ability to support projects of arbitrary scale, and so on. These tools can add an astonishing amount of baggage to the final code.
This real-life example from the Association for Computing Machinery clearly shows the effects of bloat: A simple "Hello, World" program written in assembly comprises just 408 bytes. But the same "Hello, World" program written in Visual C++ takes fully 10,369 bytes--that's 25 times as much code! (For many more examples, see http://www.latech.edu/~acm/HelloWorld.shtml. Or, for a more humorous but less-accurate look at the same phenomenon, see http://www.infiltec.com/j-h-wrld.htm. And, if you want to dive into Assembly language programming in any depth, you'll find this list of links helpful.)
Human skill also affects bloat. Programming is wonderfully open-ended, with a multitude of ways to accomplish any given task. All the programming solutions may work, but some are far more efficient than others. A true master programmer may be able to accomplish in a couple lines of Zen-pure code what a less-skillful programmer might take dozens of lines to do. But true master programmers are also few and far between. The result is that code libraries get loaded with routines that work, but are less than optimal. The software produced with these libraries then institutionalizes and propagates these inefficiencies.
You And I Are To Blame, Too!
All the above reasons matter, but I suspect that "featuritis"--the tendency to add feature after feature with each new software release--probably has more to do with code bloat than any other single factor. And it's hard to pin the blame for this entirely on the software vendors.Take Windows. That lean 5-Mbyte version of Windows 3.0 was small, all right, but it couldn't even play a CD without add-on third-party software. Today's Windows can play data and music CDs, and even burn new ones. Windows 3.0 could only make primitive noises (bleeps and bloops) through the system speaker; today's Windows handles all manner of audio and video with relative ease. Early Windows had no built-in networking support; today's version natively supports a wide range of networking types and protocols. These--and many more built-in tools and capabilities we've come to expect--all help bulk up the operating system.
What's more, as each version of Windows gained new features, we insisted that it also retain compatibility with most of the hardware and software that had gone before. This never-ending aggregation of new code atop old eventually resulted in Windows 98, by far the most generally compatible operating system ever--able to run a huge range of software on a vast array of hardware. But what Windows 98 delivered in utility and compatibility came at the expense of simplicity, efficiency, and stability.
It's not just Windows. No operating system is immune to this kind of featuritis. Take Linux, for example. Although Linux can do more with less hardware than can Windows, a full-blown, general-purpose Linux workstation installation (complete with graphical interface and an array of the same kinds of tools and features that we've come to expect on our desktops) is hardly what you'd call "svelte." The current mainstream Red Hat 7.2 distribution, for example, calls for 64 Mbytes of RAM and 1.5-2 Gbytes of disk space, which also happens to be the rock-bottom minimum requirement for Windows XP. Other Linux distributions ship on as many as seven CDs. That's right: Seven! If that's not rampant featuritis, I don't know what is.
Is The Future Fat Or Lean?
So: Some of what we see in today's huge software packages is indeed simple code bloat, and some of it also is the bundling of the features that we want on our desktops. I don't see the latter changing any time soon. We want the features and conveniences to which we've become accustomed.
But there are signs that we may have reached some kind of plateau with the simpler forms of code bloat. For example, with Windows XP, Microsoft has abandoned portions of its legacy support. With fewer variables to contend with, the result is a more stable, reliable operating system. And over time, with fewer and fewer legacy products to support, there's at least the potential for Windows bloat to slow or even stop.
Linux tends to be self-correcting. If code-bloat becomes an issue within the Linux community, someone will develop some kind of a "skinny penguin" distribution that will pare away the needless code. (Indeed, there already are special-purpose Linux distributions that fit on just a floppy or two.)
While it's way too soon to declare that we've seen the end of code bloat, I believe the signs are hopeful. Maybe, just maybe, the "code fast, make it work, hardware will catch up" mentality will die out, and our hardware can finally get ahead of the curve. Maybe, just maybe, software inefficiency won't consume the next couple orders of magnitude of hardware horsepower.
What's your take? What's the worst example of bloat you know of? Are any companies producing lean, tight code anymore? Do you think code bloat is the result of the forces Fred outlines, or it more a matter of institutional sloppiness on the part of Microsoft and other software vendors? Do you think code bloat will reach a plateau, or will it continue indefinitely? Join in the discussion!
Software Bloat and Moore's Law
Regarding a line in the recent interview of Joel - How can Moore's Law justify software bloat? Software can grow *at least* as fast as hardware can. So no matter how much better your next computer is, bloated software will *still* run slowly. And what's worse, you'll have to upgrade *everyone's* workstation to the new model, in order to keep compatible with the new bloated office suite.
When using software you're trying to complete a task, and the cost of completing that task is worker time, the hardware, and any software development or licensing. When the software adds 100 useless "features", and ends up needing a system with a processor 18 months newer and 32MB more RAM, that adds to the total cost to use the software. Bloatware simply costs too much.
When it comes to software that is always incompatible with the previous version (Linux kernel, Microsoft Office), this leads to a perpetual cycle of hardware upgrades. Why should an organization have to keep buying boatloads of new PCs, when most of the people are trying to complete the same tasks?
Neil STevens
Wednesday, December 05, 2001I definitely respect this point of view, that we're going nuts with new features. However, the consumers have spoken, and while they say they want speed, they pay for bloat.
Things may change though, since it's only been a decade or two that we've had PCs. It is very hard to find meaningful long-term patterns in such a small time period. Perhaps the economic slowdown will make things more clear.
Basically, I think that any discussion of bloat requires a discussion of consumers as well as software companies.
forgotten gentleman
Wednesday, December 05, 2001Software bloats faster than hardware capacity expands. Why ? We have all experienced situations where the user demands interconnection between functions which mess up our nice logical deconstruction of the system. If you think of a system as a circle with functions at the edge, the interconnectedness of the system is related to the area. Adding a little extra to the circumference (user functions) inflates the area (interconnectedness) to a much greater degree. Increasing the power of a computer simply allows your computer to run bigger circles of functionality with an exponential increase in complexity.
Ian sanders
Wednesday, December 05, 2001On the topic of software bloat, it would help to distinguish between size bloat and processor cycle bloat. With regards to size, the more features you pile on, the bigger your code footprint will become. Just as mentioned by Joel, the cheaper disk space becomes, size bloat becomes more and more negligible. Processor cycle bloat is typically brought about by software layering. To get something done, you end up calling layers and layers of software.... most of which add little to what you need to do. I come from a c/c++ background so yes, I did knock VB, Perl, and other scripting languages around for a while with regards to their performance aspect. However, I am finally recognizing that all the above languages have become so pervasive in the programming world.
In the miniscule world where microseconds matter, size and speed matter. This used to be the perception and programming accumen used to be how tight you can keep your code. You tell me what the new perception is.
Hoang Do
Wednesday, December 05, 2001On Size vs Speed, remember that it's not just disk space that is affected by size bloat. The more code and data your application has to use, the more RAM your application uses up, the more swapping the user has to endure, and the slower the entire system runs as a result.
Yes, disk space is cheap, but disk space isn't a substitute for RAM.
Neil Stevens
Wednesday, December 05, 2001Yes, but RAM is cheap, too. And so are CPU cycles.
Besides, hardware capacity hasn't just grown faster than software has expanded, it's left it in the dust and lapped it a few times. 512 MB of RAM is less than $100. A 1 GHz CPU is less than $100. A 20 GB hard drive is less than $100.
Dave Rothgery
Thursday, December 06, 2001RAM/HD not withstanding, it's worth noting that bandwidth for ESD (electronic software distribution) is expensive. And in large enterprises, the ability to have a clean installation process (e.g., not ripping up registry settings or installing system DLLs - a common trait of bloatware) is also key.
We market a small P2P web server ([plug]BadBlue[/plug]) for file sharing that at one point was so small (161K) that Lucas Gonze of O'Reilly Network entitled his column about it "161K". I guess journalists are sick of bloatware as well.
But I do think that's one of the things people like about this type of software: tiny, easy to install and functional for the purpose at hand.
D Ross
Thursday, December 06, 2001What about all the junk in the background... In the Operating Systems course I am doing they teach you that the more programs that run at once the more CPU cycles have to be split in between programs. This causes overhead of which older operating systems had trouble with. The new operating systems like windows 2000 and XP don't have such a problem but in saying that they have a higher overhead regardless.
Phillip Kilby
Sunday, December 16, 2001
30 Apr 1999
From: [address deleted] (RA Downes)
Subject: The Bloatware DebateOne of the chief hallmarks of early UNIX was how simple, compact programs worked well together. Brian W. Kernighan's definition of a good program was a program so good and so consistent that it could be used for an entirely different purpose and be expected to work well. UNIX, they said, was a way of thinking more than an operating system. And, with Brian's Software Tools series, it was surely so.
Microsoft Windows is also a way of thinking - or not thinking, to be more exact. In almost every possible sense it is the anathema of the programming community, if that community still abides by and adheres to the solid thinking delineated by Brian so many years ago.
MS Windows programming is considered too difficult to attempt head on. Where we come from most major corporations, financial institutions and the like promised a smooth transition from UNIX or DOS to Windows 3.1x within a matter of weeks. Management talking of course. When they found this would not work they decided to invest heavily in 16-bit Visual Basic applications. Operative word "heavily". These bloatware masters sunk almost any machine made. Clearly this was not the answer either.
People looked to Kahn. Borland, with its Turbo C, saw the opening and released Borland C, and shortly thereafter Scott Randell who a year earlier had toured with MSC 7.0 (which admittedly never worked) was out rocking again, this time with Visual C++. The environment was unbelievable; the executables were extremely bloated; but still and all it was Microsoft talking, and still and all they were smaller than the corresponding Borland images. COBOL programmers everywhere were suddenly encouraged to learn C++, develop code browsing skills, learn about preprocessors, assembly language, CodeView and subsequent debuggers, and the world entered into a tailspin.
What originally started as a rather feeble but lucky attempt to get on the OO bandwagon, the MFC soon became something you'd like to see Steve McQueen kill. Patches and work-arounds and bugs and more bugs, and bloat and more bloat. The current splash screen module is a case in point: Microsoft includes a 16-color bitmap which weighs in at nearly 200KB for you. This bitmap can be compressed with RLE encoding to less than half that size. The idea of banging a 100KB splash bitmap in an application is still, however, sickening. Yet Microsoft gladly gives you the bitmap at 200KB, happy if you don't understand what you are doing by using it. Your application will be more sluggish than their own bloatware, and people will be less inclined to complain about what they themselves do.
Microsoft's RegClean, a popular product for fixing corruptions in the MS Windows Registry is another case in point. When this application was originally introduced I downloaded it and wondered about its size. It weighed in then at nearly a megabyte. Similar applications out there were 20KB and hardly more. What was inside this monster? I opened it and looked inside.
Remember all those stories about how surgeons in the old days just threw their rubber gloves inside the patient's stomach before sewing them back up again? Well here you had it. There were humungoid bitmaps never used. There were dozens of icons never referenced. There were tens of kilobytes of entries in the string table that had no meaning for the application whatsoever.
I honed the app down and came to the conclusion that the actual size of RegClean should be about 45KB. That as compared to its distribution size of nearly one megabyte. Clearly bloat is not only a question of adding features almost no one wants. Bloat is a condition of the mind, permeating software houses everywhere.
Clearly again the distribution of RegClean was highly irresponsible. But remember, MS Windows is not just an operating system - it is a way of thinking, or not thinking as you may have it. And it has permeated the entire industry today. Our hats off to Microsoft.
In conclusion: there are few application domains even today that require executables of over 100KB, and most ordinary tasks can be adequately managed by executables in the 20KB range. This is simply a fact.
There are no excuses. Either we think or we don't. There is no in between.
RA Downes Radsoft Laboratories <http://www.radsoft.net> ------------------------------
End of RISKS-FORUM Digest 20.35
************************
Date: Tue, 4 May 1999 09:06:59 -0700 (PDT)From: risks at csl.sri.com
RISKS-LIST: Risks-Forum Digest Tuesday 4 May 1999 Volume 20 : Issue 37
FORUM ON RISKS TO THE PUBLIC IN COMPUTERS AND RELATED SYSTEMS (comp.risks) ACM Committee on Computers and Public Policy, Peter G. Neumann, moderator
Date: Sun, 02 May 1999 16:12:13 +0000
From: [address deleted] (RA Downes)
Subject: Re: Bloatware Debate (Downes, RISKS-20.35)A certain "Johnny" has written to me from Microsoft because of my posting in RISKS-20.35 about MS bloat. The tone was a thinly disguised threat. In his opening, "Johnny" stated that the "bloat" of MS RegClean was due no doubt to having static links. Discussing the sweeping ramifications of such a statement is unnecessary here. The mind boggles, it is sufficient to state. The MSVC runtime is a mere 250,000 bytes and in fact is not statically linked anyway to MS RegClean, AFAIK [as far as I know]. MS RegClean is an MFC app and will by default use the dynamically linked MFC libraries. And even if its static code links were an overhead here they would add but a small fraction of the total bloat, say 40KB at most.
For whatever reason, I decided to download the latest version of MS RegClean from BHS again and pluck it apart. This is what I found. I have tried - and it has been difficult - to keep subjective comments out of this report.
Current Status of RegClean Version 4.1a Build 7364.1
====================================================
Image Size (Unzipped and ready to run): 837,632 bytes (818KB)
=============================================================
(Subjective comment removed.)
Import Tables
The import section in the PE header. This gives an indication of just how (in)effective the use of Bjarne's C++ has been. In this case, the verdict is: "pretty horrible". A walloping 7,680 bytes are used for the names of the relocatable Win32 imports. These are the actual names of the functions (supposedly) called. MS RegClean does not call most of these functions - they remain because an MFC template was originally used, most likely borrowed from another application, and it was never "cleaned". This is corroborated by what is found among the "Windows resources": over half a dozen standard menus, assorted graphic images, print preview resources, etc. that have nothing to do with the application at hand.
Resources
Please understand that resources not only bloat an executable with their own size, but with additional reference data, in other words the bloat factor of an unused or bad resource is always somewhat larger than the size of the bloating resource itself.
Accelerators
Sixteen (16) unused accelerators from an MFC template were found: Copy, New, Open, Print, Save, Paste, "Old Undo", "Old Cut", Help, Context Help, "Old Copy", "Old Insert", Cut, Undo, Page Up, Page Down. MS RegClean uses only one accelerator itself, not listed here.
Bitmaps
This was a particularly sorry lot. The main bloat here was a splash screen bitmap weighing in (no RLE compression of course) at over 150KB. Further, Ctl32 static library bitmaps were found, meaning MS RegClean is still linking with the old Ctl32v2 static library which was obsolete five years ago and which automatically adds another 41KB to the image size.
Cursors
Six (6) cursors were found, none of which have anything to do with this application.
Dialogs
A very messy chapter indeed. MS RegClean walks around with eighteen (18) hidden dialogs, of which only one or at the most two are ever used. The others are just - you took the words out of my mouth - junk. The findings (read it and weep):
*) Eleven (11) empty dialogs with the caption "My Page" and the static text "Todo", all identical, all empty, and of course all unused. This is a wonder in and of itself.
*) The main "wizard" dialog actually used by the application is left with comment fields to help the programmers reference the right controls in their code (subjective comment removed).
*) A "RegClean Options" dialog which AFAIK is never used.
*) A "New (Resource)" dialog, probably a part of the development process, just stuffed in the stomach at sew-up time and left there for posterity.
*) A "Printing in Progress" dialog.
*) A "Print Preview" control bar dialog.
Icons
MS RegClean has three icons, all with images of 48x48 in 256 colors (of course). The funniest thing here is that the authors of MS RegClean have extracted the default desktop icon from shell32.dll, which is available at runtime as a resident resource anyway and at no image bloat overhead at all, and included it in toto in their executable.
Menus
MS RegClean has eight (8) menus, at least half of these are simply junk left around by the MFC template. Another menu indicates that the authors of RegClean have in fact worked from an internal Microsoft Registry tool - rather bloated in itself it seems.
String Table(s)
Actually it need only be one string table, but Microsoft itself has never learned this. The findings here were atrocious. And you must remember that strings stored in a string table are stored in Unicode, which means that their bloat automatically doubles. Further, MS's way of indexing strings in a string table means a 512 byte header block must be created for every string grouping, and strings are grouped according to the high 12 bits of their numerical identifiers (yes they are 16-bit WORD identifiers). Meaning indiscriminate or random numbering of string table entries will make an otherwise innocent application literally explode.
347 (three hundred forty seven, yep, your video driver is not playing tricks on you) string table entries were found in MS RegClean, including 16 identical string entries with the MS classic "Open this document" as well as archaic MFC template toggle keys texts which are not used here (or almost anywhere else today). Most of these strings have - of course - nothing to do with the application at hand.
Toolbars
Toolbars are a funny MS way of looking at glyph bitmaps for use in toolbar controls. MS RegClean has two - one which may be used by the application, and one which was part of the original MFC template and never removed.
Total Accountable Resource Bloat
The total accountable (i.e. what can be directly calculated at this stage) resource bloat of MS RegClean 4.1a Build 7364.1 is over 360,000 bytes (350KB).
Total Accountable Code Bloat
Harder to estimate, but considering that most of the code is never used, only part of an MFC template that the authors of MS RegClean lack the wherewithal to remove, the original estimate of a total necessary image size of 45KB for the entire application must still stand.
In Conclusion
Bloat is not a technical issue, but verily a way of thinking, a "state of mind". Its cure is a simple refusal to accept, and a well directed, resounding "clean up your act and clean up your code!"
PS. Send feedback on RegClean to regclean at microsoft.com
RA Downes, Radsoft Laboratories http://www.radsoft.net
-- I have a shoehorn, the kind with teeth. --
Christopher R. Hertel -)----- University of Minnesota
Nov 29, 1999 | eWEEK
As the pace of e-business accelerates, however, supporting all of that architectural diversity is getting tough, so Solomon has begun to seek simplicity. He is examining the idea of one type of network architecture, where all systems share a common set of services, such as security, authentication and system management.
He's beginning by unifying disparate network and system components and integrating Web-based technology into SIAC's core legacy back-end systems. Right now, for example, he's blending into SIAC's core trading-floor networks Web technologies that will allow traders to check quotes and communicate with customers on the outside.
These days, more and more IT managers are discovering that, in the age of pedal-to-the-metal e-business, architectural complexity doesn't work. Historically, many organizations have, like SIAC, created multiple networks, each with its own firewall and security system. To get e-business efforts off the ground, for example, many enterprises ended up supporting two network architectures: a legacy network supporting internal processes-finance, inventory management, etc.-and another for extranet operations that link to customers, suppliers and partners. However, that kind of complexity makes it difficult for companies to transform themselves into e-businesses. Multiple layers of security and authentication, for example, make it all but impossible to open inventory and other back-end systems to customers, partners and suppliers online. And maintaining all that architectural complexity is becoming increasingly expensive, IT managers say.
So, like Solomon, many organizations are seeking to simplify. They're trying to build unified IT architectures that provide common, enterprisewide security, authentication and data exchange services using Web-oriented technologies such as LDAP (Lightweight Directory Access Protocol), metadirectories, XML (Extensible Markup Language), the CORBA (Common Object Request Broker Architecture) distributed object framework, PKI (public-key infrastructure) security and authentication schemes (see chart.) That means giving users-whether employees, customers or partners-a single way to get to corporate information. And it means a single, less expensive approach to system management.
There are still plenty of roadblocks between enterprises and unified architectural simplicity. Standards such as LDAP, XML and PKI must be more completely defined and implemented in products. Many IT managers also admit that they still have concerns about security, concerns that loom large as they contemplate building simpler, unified architectures. And, as some IT managers are finding, business managers can become impatient with the expense and time it takes. For those reasons, the simpler, unified architecture is still a few years off for most companies. However, according to experts, many are moving in that direction.
"From a trend standpoint, we've seen a number of companies who've begun the process of collapsing and standardizing their architectures," said Andrew Kelemen, an analyst with CNS Group, in Norwalk, Conn. "All of a sudden comes this blurring of the lines between intranets and extranets."
Shifting investments
One such organization is Franklin Covey Co., a Salt Lake City-based provider of management tools and professional services. Eighteen months ago, Franklin Covey CIO Niel Nickolaisen decided to stop investing in the company's internal network architecture-a combination of Windows NT and Unix systems-and instead direct spending to Web-based applications that would enable his organization and its partners to more easily tap into disparate information over the Internet.
Nickolaisen sat down with his retail point-of-sale software provider, Tomax Technology Inc., also of Salt Lake City. Tomax understood the benefits of converging retail applications and the Internet architecture and agreed to develop a Java-enabled version of its system that would take advantage of the distributed intranet infrastructure. Using that version, running on his CORBA-based Internet architecture, Nickolaisen's plan is to be able to deploy a system that lets various parts of his organization tap into the same, up-to-date customer information.
From a browser, for example, Franklin Covey call center reps can tap into customer purchase history records, and suppliers can access their sales history information. By connecting and integrating with customers and suppliers over the Web, Nickolaisen said, his IT department can move away from constantly integrating applications and work on developing tools that provide value to the company.
"I put the current network into maintenance mode and decided that all investments, projects and initiatives would be built on an Internet infrastructure that we can leverage in the future," he said. "Single-point management would be ideal. Ideally, it wouldn't matter what format the data is in. It could be standardized and subscribed to by everybody who needed that data."
As more packaged applications become Java- and CORBA-enabled, Nickolaisen said he would like to use them to connect his current legacy systems to exchange information.
Since, like Franklin Covey, most enterprises aren't prepared to throw out the networks, directories and firewalls they already have in place, many will start by building Web-oriented technologies into current networks and legacy systems, experts say.
Many large enterprises, in fact, are beginning to apply increased pressure to get vendors to support such cross-platform standards.
Some vendors are taking note of IT managers' desires for simple, unified architectures based on Web technologies that can run across multiple platforms. Companies such as Entrust Technologies Inc., Netscape Communications Corp. and Novell Inc. have touted versions of key services that will run on a number of operating systems. Entrust's PKI products, for example, can work with directory services from Netscape, Novell and a variety of vendors via LDAP.
"The maturity of newer technologies will have to happen before enterprises fully deploy such an infrastructure," CNS Group's Kelemen said. "But as users begin to push for this infrastructure, they will in turn push vendors to adopt standards by requiring compatibility, integration and support."
At Duke Energy Corp., in Charlotte, N.C., for example, Bruce Anderson, the manager of technology planning and application services, has a goal of standardizing on a network architecture capable of handling both intranet and extranet capabilities. Anderson knows, however, that such a move will not happen overnight. That's because at Duke there is already a legacy environment that operates effectively. The company is running a complex network that includes a number of platforms, including Oracle Corp.'s manufacturing software running on Unix and some IBM mainframe applications running DB2. Duke also has a couple of hundred EDI (electronic data interchange) connections in place. The company won't be replacing those systems any time soon.
A single network
In building a new intranet architecture, Anderson is using tools that will allow him to eventually move to a single network infrastructure. He is currently implementing XML where possible, with an eye toward replacing some EDI connections when business partners are ready. He's also deploying directory services in various parts of his intranet in an effort to build an architecture that will eventually allow him to increase reliability and accessibility while lowering support costs.
"Everyone is trying to provide the most value to their customers," Anderson said. "One of our IT principles is to really try to leverage a single data network. That does not mean that it's either one physical standard or nothing at all; it means that there are certain physical characteristics users from inside and outside of the company will be able to see [that] will be standardized."
But why change something that already works? Anderson said the cost benefits of a more unified network architecture are too high to overlook. Staff and training expenses alone could be trimmed significantly if Duke could deploy unified, centrally managed architectures, he said.
So, Anderson is leveraging what he's learned from building business-to-business and business-to-consumer e-commerce applications to rebuild his internal network infrastructure.
Duke, for example, has already built Web-based call center applications that handle calls during disaster situations anywhere in the world. The company has learned how to use directory services and other Web technologies to make those systems scalable and reliable. Now, Anderson said, Duke will use that experience and some of the same technologies to enhance its intranet, which supports 25,000 employees worldwide. Anderson and Duke employees are evaluating metadirectories, certificates and PKI in a lab environment.
"Using an extranet application like our call center allows us to see how we can build a stable intranet accessible on a worldwide scope that is not only scalable but also reliable," Anderson said.
Political risks
However, focusing resources on creating a simplified, unified IT architecture can carry political risks, IT managers say. Franklin Covey's Nickolaisen, for example, has taken heat for pushing investments into Internet technologies. After all, that means he's less eager to spend money on, for example, a new customer relationship management application that some business managers are pushing for. Instead he is more eager to invest in LDAP or other technologies that end users don't see but that the company can leverage long-term. The hard part is explaining to business managers why applications that don't take advantage of the new Web-enabled architecture are not a good buy.
"I tend to push back and say, 'Let's not implement new applications. Let's not replace that call center we've had for 12 years because we can replace it and get increased functionality, but we can't leapfrog into the future with it because it is not designed to run on the open and flexible infrastructure of the future,'" he said. "I take incredible heat for my position." Nickolaisen recently decided to leave Franklin Covey. Although he said the decision had nothing do with differences that may exist over IT investment philosophy, he said his new position launching an Internet site will allow him to build an integrated architecture from scratch.
Driving for simplicity via a unified architecture also often means taking a more active role in pushing vendors to support Web-based standards. Duke's Anderson, for example, has become active in the Society for Information Management's IT Complexity Reduction Working Group, of which Duke's CIO, Cecil Smith, is a founding member. Using guidelines decided upon by the group, Anderson is pushing vendors to provide tools that will work seamlessly with tools from other vendors using standard interfaces and technologies such as XML (see related story).
"We are interested in the connectivity," Anderson said. "We'll sacrifice the absolute uptime in terms of performance and productivity if the collaborative nature of the environment allows us to be more adaptive. Our goal is to build a network that will enable us to exchange information seamlessly with our customers and vice versa."
The security barrier
Besides politics and a lack of vendor support for standards, concerns about security continue to pose a barrier to the merging of extranet and intranet architectures, Kelemen said. Although companies have willingly allowed partners to access information via extranets, the idea of extending their own infrastructures into somebody else's enterprise is still viewed as risky, he said.
"Right now, it's simple if you have two network architectures," Kelemen said. "You're going to authenticate at the account level, maybe using some kind of directory service. But as far as actually allowing some third party to access proprietary information within their own organizations, many IT managers are still balking."
In fact, said Duke's Anderson, merging intranet and extranet architectures will not only require new technology, it will force Duke's IT organization to change the way it implements security, replacing a series of application-specific firewall- and password-based systems with a unified approach that grants users access to applications based on predefined profiles and authentication.
At SIAC, Solomon has the same concerns about security. With billions of dollars at stake on trading floors, Solomon said he cannot afford a network security breach. That's why he's convinced that, while merging intranet and extranet architectures around something like PKI is feasible for some applications, he won't be doing it any time soon for critical applications such as SIAC's trading networks.
There, for the time being, he'll stick with the Kerberos security protocol, which, using defined boundaries, closes the network from the outside world.
Solomon may be a speed demon in the race to tomorrow's e-business architecture but, he said, he's not about to drive without a seat belt just yet if he doesn't have to
November 29, 1999 | eWEEK
November 29, 1999 (eWEEK) IT managers have long endured the arduous task of connecting disparate operating systems, applications and network protocols to build network architectures. That task is becoming even more burdensome as e-business increases the need for companies' systems to become accessible to customers, partners and suppliers.
Now, CIOs at a group of large companies are joining to pressure IT vendors to help solve the problem. Last year, 15 member companies of the Society for Information Management formed a working group to reduce the level of complexity in IT systems. They want vendors to support standards that will help make building simpler, unified IT architectures easier. The group includes companies such as AT&T Corp. and Kraft Foods Inc.
Not every member of the SIM working group is moving toward the goal of a unified architecture capable of handling both intranet and extranet needs. But each company has a stake in making it simpler, less costly and less time-consuming to integrate systems from multiple vendors, said Steve Michaele, district manager of foundation architecture at AT&T and the group's leader.
"We've got legacy environments we need to connect to and multiple hardware platforms that we're supporting. All of that is a complex infrastructure to manage," Michaele said. "Now that we're trying to leverage that infrastructure in a Web environment, we need these applications to be interoperable."
The IT Complexity Reduction Group's goal is to develop a series of standards documents to send to key hardware and software vendors. The documents give vendors outlines of which member companies want vendors to provide interoperability for products and languages.
At SIM's annual meeting last month, the working group presented areas where a unified approach is required and some of the standards it wants vendors to adopt. Every area of concentration is one with which members have problems with integration and standards such as directory services and security.
How have vendors reacted? Bruce Anderson, a member of the working group, has brought the group's white papers to vendors and asked if they'd consider following the group's specifications. Many vendors are open to the idea, said Anderson, manager of technology planning and application services for Duke Energy Corp., in Charlotte, N.C.
They'll have to do more than explore to meet the SIM working group's goals. The group is after nothing less than removing barriers to collaborative e-business for the future.
"We're not trying to optimize niches or segments of technology but to remove the barriers to interoperability and interconnectivity," Michaele said. "We're trying to be visionary in that way and build a successful path to the infrastructure of tomorrow."
Here's information for managers interested SIM's Complexity Reduction Working Group:
- How to qualify: Your company must be a member of SIM. You also must be either a network architect or a CIO involved in the planning of corporate networks.
- What's involved: All members commit to one conference call a month and five on-site meetings. There is also a fee of $500 to cover the group's expenses. All travel, meals, accommodations and time are volunteered.
For more information, go to www.simnet.org.
I was talking to some people in IRC today, mostly about open source projects such as perl, linux, and mozilla, and it occured to me that the collaborative model of open source (where many developers from all over the Internet can contribute to a project) encourages programs to become bloated and unwieldy.
I started using Linux during 1998. I wasn't very adept at computing, and I didn't know much. But it was an interesting concept to me that a computer could actually turn on and proceed to run something other than DOS or Microsoft Windows (two products which I was convinced were intimately related, by popular myth). So back in 1998, I got a book on Linux. With the book came three CDs. Slackware, Red Hat, and Caldera. Red Hat's installer didn't really like my computer too much, and Caldera (according to the book) didn't seem to be a full version. So I pulled out the slackware CD and proceeded to install it on my 486.
Back in 1998, Slackware installed just fine on my 486 DX2, with 8 megs of ram and a 300mb hard disk. And after a bit of tinkering, so did Red Hat. Today, their installers won't even run on that computer.
Tales of the golden age of computing aside, what has happened to these pieces of software? Looking at things like the Linux kernel, there haven't been all that many significant changes in functionality, yet the size of both the compiled binary and the source have gone up dramatically. Sure they have journalling filesystems, encryption, IPv6 support, and all that. But can I do anything significantly different than what I could before? Not really.
While Microsoft has been accused of bloated software (a claim I do not dispute), it worries me to see open source projects progressing in their bloat at a much faster rate than Microsoft products.
This is my theory, and you're free to dispute it. But I believe it makes at least some sense. Monolithic development houses such as Microsoft usually set goals and keep to them. They say: "Let's make this software more accessible to people that are not familiar with computers," and so they develop a more intuitive user interface. They say: "Let's integrate a picture album, people like that", or "Almost everyone that uses our OS browses the web, let's put our own browser in". While this model of meeting demands and pushing out new features does lead to considerable bloat, as is obvious by the increasingly powerful computers required to run even the simplest of applications (or even the operating system itself), it is generally controlled. Because the team of people is generally constrained to a few design goals, and is also limited by the practicability of their upgrades or enhancements, the bloat too is limited.
Enter collaborative open source, as demonstrated by the Linux kernel. Because of the open source model, many people are encouraged to modify the source to fit their specific needs. And because of the general spirit of open source, they are encouraged to submit their modifications back to the community so that others in similar predicaments can benefit from their work. What this generally creates is uncontrolled and exponential bloat. Some of these submitted features are genuinely useful, such as drivers for hardware, or a refinement of the virtual memory manager. Additions and modifications that the majority of the people using the software can benefit from. However, this model also encourages excessive bloat because of the niche 'enhancements' submitted that are only used by a few, but distributed to everyone.
Take for example, the HTTP server integrated into the Linux kernel. Most sane administrators realize that not only would a user space webserver such as Apache better fit their needs, but a HTTP server that is integrated with the kernel may pose a serious security threat. Granted, when you compile your kernel, there is no need to include this piece of code. Such an arrangement is an optimal way of dealing with bloat.
However, this arrangement is made merely out of necessity. If everything everyone submitted into the Linux kernel code was automatically included, it would be a practically disasterous situation. But take, for example, open source projects where this is less important. Perhaps Mozilla.
One of the people in an IRC room I frequent was recently singing the praises of Mozilla and it's extensions system. It was so great, in fact, that he was using ChatZilla to talk to me. ChatZilla, for those who do not know, is an IRC client scripted entirely within Mozilla's extension system. And included by default. Mozilla comes by default with extensions such as a mail and news (NNTP) client, a visual HTML editor, and now, an IRC client. While features such as mail and news are perhaps acceptable default inclusions, due to their entanglement with many existing documents on the web, and an addressbook goes hand in hand with the mail client, features such as a page editor and especially an IRC client are largely extraneous bloat. Most sane people will use a more suitable, dedicated IRC client such as BitchX, mIRC, or X-Chat. Clients that are most often small compiled applications that run quickly and use very little memory/CPU time, as an IRC client should. Why, except for convenience, would the majority of mozilla users wish to run a scripted (which also suggests that it is inherantly slow and less efficient than possible) IRC client that depends also on the mozilla browser being loaded into memory? The point here is not to overly criticize chatzilla. The point is that it is an unnecessary piece of software designed to satisfy the needs of a very small percentage of the user group. It is bloat. Despite all its shortcomings, does Internet Explorer include an IRC client? The collaborative open source model encourages software to become bloated.
The general collaborative open-source attitude (although to be fair, only after the project has reached maturity) is to submit anything and everything that you can come up with. "Someone, somewhere will find a use for it," is the general mantra. Also causing the phenomenon of bloat is conflicting goals. Many want Linux to be a desktop OS. Many more (I hope) want it to be a server OS. Some don't understand why it can't be both. This creates odd situations, like having a "generic" kernel with USB and sound drivers, and KDE, running on a server with no sound card, USB devices, or a monitor.
Why do I care? Computers are fast enough to handle large software. Disk drives are big enough to store large software. Networks are fast enough to transfer large software. Why does it matter? It matters because:
* That software is not always the only thing running. People don't start up 'perl' and say "I think I'll sit here and watch the output of perl until it's done doing what it does. Then I can run other software." Look at a moderately loaded webserver running CGI scripts that rely on perl. Hundreds of perl invocations may be running at any given time. An increase in the size of the perl binary or the processing time it eats up while doing a specific function may not seem so significant until you too run a server like this. You upgrade perl and suddenly you find yourself needing another gigabyte of ram, or another processor. And server owners aren't the only ones suffering. Even people that participate in simple activities such as playing games suffer from software bloat. When you have a computer that is a few months behind state of the art and every meg of memory you can squeeze out helps your online gaming session look less like a slide show, things like a huge web browser binary residing in memory start to tick you off a bit.
* Bloated software is one of the main reasons why computers get 'outdated'. Not everyone compresses video or renders 3d movies. Some people like to do simple things like check their e-mail, or take a peek at the web. These people find their older computers woefully inadequate for the same tasks the computers were doing when they bought them. For example, I can no longer load up linux and mozilla on my 486 and browse the Internet. And don't tell me that's because of advances in the HTML standard. Why should I have to shell out a few thousand dollars because someone wants to add an IRC client to a web browser here, and a HTTP server to the kernel there, and slap a flashier graphical interface on an installer? If developers who submitted these little jewels of software delight to open source projects had to pay for the accumulation of hardware upgrades they were causing, they probably wouldn't do it.
Failing to upgrade your software is no solution to this problem. As can be seen from the myriad of websites dedicated to security problems and vulnerabilities, it is irresponsible not to regularly upgrade your applications.
What's the solution? Either developers need to be more conscious about the features that they integrate into their software (for example, if you're using C, #ifdef's around possibly unnecessary pieces of code, and configure script/Makefile choices), or they need to back-port bug fixes and more important upgrades into their old code. The first solution seems better.
There's nothing wrong with ChatZilla. I just don't want it. (And personally, I think it should be a separate piece of software.)
Note that entire Linux distributions such as Gentoo have been founded around the concept of choice, largely as a reaction against open source bloat. And me? I use FreeBSD, an OS that has a development team whose goals seem clearer than most, and who have designed what is very obviously a server/workstation OS as opposed to trying to cater to old grannies that don't want to pay for windows.
Discussion
> who is guilty of software bloat??????
Most software programs are getting large because consumers want more and more features. Software companies need to add more and more features to create reasons for people to upgrade. On top of that the market today demands that software be released earlier and earlier... software companies cannot spend months optimizing code. In addition the benefits of code optimizations are becoming less and less because of how fast computers are and how much storage we have available.
Just the other day I was looking through some old Commodore magazines (circa 1984) and was chuckling at how much time they spent optimizing the little BASIC programs. One article even talked about the future of gaming and mentioned something like.... "some day we may have computers so powerful that we don't have to worry about how much storage we can use".
For the most part I don't think software is all that bloated. There are a few programs that seem needlessly slow, but most operate quite quickly. Even MS Office 2000 apps seem to start quickly and run without much hesitation at all.
And my argument when someone complains about software bloat is usually "use an older version!" You don't HAVE to upgrade!
I think consumers and the media are to blame. They harrass software manufacturers when they're "late". This forces software manufacturers to reduce time spent debugging or optimizing code so they can get a program out the door.
It always cracks me up... the same people that complain when software is late will complain if it's buggy. IMO I'd rather have software be a little "late" so that it can be higher quality.
Google matched content |
n. The results of second-system effect or creeping featuritis. Commonly cited examples include `ls(1)', X, BSD, Missed'em-five, and OS/2.
Wikipedia
Strategy Letter IV Bloatware and the 80-20 Myth - Joel on Software
software bloat Software bloat is an instance of Parkinson's Law: resource requirements expand to consume the resources available.
Manton Reece Smart software bloat One way is to differenciate between visible and hidden bloat. For example, Microsoft products used to have a tendency to take every major bullet point on the side of the box and make a toolbar icon for it. Even if the user only uses 5% of those features, they have easy access to far too many of them, and they needlessly have access to them all at once.
The Old Joel on Software Forum: Part 3 (of 5) - Define bloat: by ...
IBM developerWorks Blogs building tools to support software development teams
Software bloat, beware the server-managed rich client!Bob Zurek: Software Bloat! Ever get the feeling that you've had enough of the upgrade after upgrade and sometime continuous stream of hundreds of new features coming in the software you use? How many of these new features do you truely need? In fact it seems like some of these "new features" are not really new, they are just things that needed to be fixed or improved that are now called "new features". New features also sometimes mean more complexity, more disks, longer downloads, bigger help systems, more documents, more trips to the bookstore, etc. (more)
Bob, I agree with you in principal, but it's not such an open and shut case.
Simplify iT Innovations, 100% Australian owned and operated, located in Perth, Western Australia. As our name implies, we provide leading edge innovative ...
Processor Editorial Article - Simplify IT Network Management ...
Processor Editorial Article - Simplify IT Network Management & Monitoring.
HP Feature Story: Simplify IT: Smart Office, Smart advice ...
Whether you're a small business with limited information technology (IT) support or a midsize company trying to get the most from your IT infrastructure, ...
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: June 05, 2021