RHEL6 and RHEL7 should be viewed two distinct flavors of Linux much like RHEL and Suse. Most network operations are
completely different and use different utilities. So Network configuration is discussed in two separate pages:
20210312 : How to Set a Static IP Address in CentOS Linux by an IP Address. Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . An IP ( Internet Protocol ) Address is a unique numerical representation of a computer on a network. Every computer connected to the Internet is identified by an IP Address. Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . Today, we will learn how to set a static IP address on a local network in CentOS . Today, we will learn how to set a static IP address on a local network in CentOS . List Network Interface Name A computer can be connected to one or more network interfaces, for example to a WiFi device and a LAN device, which has different IP addresses for each interface. Run the following command to show the interface names. A computer can be connected to one or more network interfaces, for example to a WiFi device and a LAN device, which has different IP addresses for each interface. Run the following command to show the interface names. Run the following command to show the interface names. Run the following command to show the interface names.
# ifconfig OR # ip addr
List Network Interface Names The interface ' enp0s3 ' is the LAN device connected to my computer and the IP Address is ' 10.0.2.15 '. The other interface ' lo ' ( Loopback ) which is nothing but the local network of the computer within itself. Thus my computer is only connected to one interface, ' enp0s3 '. The interface ' enp0s3 ' is the LAN device connected to my computer and the IP Address is ' 10.0.2.15 '. The other interface ' lo ' ( Loopback ) which is nothing but the local network of the computer within itself. Thus my computer is only connected to one interface, ' enp0s3 '. Configuring Static IP Address in CentOS Go to directory ' /etc/sysconfig/network-scripts ' and list the files; you should see a file corresponding to your network interface. Go to directory ' /etc/sysconfig/network-scripts ' and list the files; you should see a file corresponding to your network interface.
$ cd /etc/sysconfig/network-scripts $ ls
List Network Interface Files Open the file 'ifcfg-enp0s3' using ' Open the file 'ifcfg-enp0s3' using ' Vim ' or any editor of your choice. Set the following values for the variables. Change the values according to the IP address and subnet that you need to set. Set the following values for the variables. Change the values according to the IP address and subnet that you need to set. Set the following values for the variables. Change the values according to the IP address and subnet that you need to set. Set IP Address in CentOS Save and exit the file. Restart the networking service with the following commands: Save and exit the file. Restart the networking service with the following commands:
# nmcli networking off # nmcli networking on
Finally, run ' ifconfig ' again to verify if static IP has been set. Finally, run ' ifconfig ' again to verify if static IP has been set.
I had a client who was losing network connectivity intermittently recently and it turns out they needed to increase the high limit
for network connections. Centos7 has some variable name changes from previous versions so here are some helpful tips on how to increase
the limits.
In older Centos you might have seen these error messages:
ip_conntrack version 2.4 (8192 buckets, 65536 max) – 304 bytes per conntrack
To make it permanent after reboot, please add these values to the /etc/sysctl.conf
net.ipv4.netfilter.ip_conntrack_max=196608
Hope this helps!
Tags
[Mar 12, 2021] How to Set a Static IP Address in CentOS Linux by an IP Address. Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . An IP ( Internet Protocol ) Address is a unique numerical representation of a computer on a network. Every computer connected to the Internet is identified by an IP Address. Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . Usually, IP addresses are dynamically assigned to a computer by a dedicated server called DHCP Server ( Dynamic Host Control Protocol ), and hence change from time to time as and when the connection is lost and reestablished. However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . However, there are scenarios where a static IP address is more preferable; Eg. In large corporations, where it removes the load of using DHCP for each computer in the organization. Today, we will learn how to set a static IP address on a local network in CentOS . Today, we will learn how to set a static IP address on a local network in CentOS . Today, we will learn how to set a static IP address on a local network in CentOS . List Network Interface Name A computer can be connected to one or more network interfaces, for example to a WiFi device and a LAN device, which has different IP addresses for each interface. Run the following command to show the interface names. A computer can be connected to one or more network interfaces, for example to a WiFi device and a LAN device, which has different IP addresses for each interface. Run the following command to show the interface names. Run the following command to show the interface names. Run the following command to show the interface names.
# ifconfig OR # ip addr
List Network Interface Names The interface ' enp0s3 ' is the LAN device connected to my computer and the IP Address is ' 10.0.2.15 '. The other interface ' lo ' ( Loopback ) which is nothing but the local network of the computer within itself. Thus my computer is only connected to one interface, ' enp0s3 '. The interface ' enp0s3 ' is the LAN device connected to my computer and the IP Address is ' 10.0.2.15 '. The other interface ' lo ' ( Loopback ) which is nothing but the local network of the computer within itself. Thus my computer is only connected to one interface, ' enp0s3 '. Configuring Static IP Address in CentOS Go to directory ' /etc/sysconfig/network-scripts ' and list the files; you should see a file corresponding to your network interface. Go to directory ' /etc/sysconfig/network-scripts ' and list the files; you should see a file corresponding to your network interface.
$ cd /etc/sysconfig/network-scripts $ ls
List Network Interface Files Open the file 'ifcfg-enp0s3' using ' Open the file 'ifcfg-enp0s3' using ' Vim ' or any editor of your choice. Set the following values for the variables. Change the values according to the IP address and subnet that you need to set. Set the following values for the variables. Change the values according to the IP address and subnet that you need to set. Set the following values for the variables. Change the values according to the IP address and subnet that you need to set. Set IP Address in CentOS Save and exit the file. Restart the networking service with the following commands: Save and exit the file. Restart the networking service with the following commands:
# nmcli networking off # nmcli networking on
Finally, run ' ifconfig ' again to verify if static IP has been set. Finally, run ' ifconfig ' again to verify if static IP has been set.
In this
article, we saw an easy way to set an IP address in CentOS. The example, in this case, is a static IP on the local network,
i.e., it is not a static public IP over the Internet.
To set a
static public IP address over the Internet, you need to purchase the IP Address and configure it in the file as shown above,
along with other details like DNS server, network prefix, which will be provided by your Internet Service Provider.
Thanks a lot for reading and let us know your thoughts in the comments
below!
To change the ethernet connection BOOTPROTO directive static to DHCP to static using the
following command:
nmcli con mod "System eth1" ipv4.method manual ipv4.address 192.168.0.10/24 ipv4.gateway 192.168.0.1
7. Disable IPv6 Address with nmcli
By default, both IPv6 and IPv4 connection is enabled in CentOS 8. You can disable the IPv6
connection wiht the following command: Advertisements
nmcli con mod "System eth1" ipv6.method ignore
8. Add DNS Server to Existing Connection
To add a new DNS server to an existing connection with the following command:
nmcli con mod "System eth1" ipv4.dns 8.8.4.4
You can verify the changes with the following command:
cat /etc/sysconfig/network-scripts/ifcfg-eth1 | grep DNS
Output:
DNS1=8.8.4.4
You can also append a new DNS server using the +ipv4.dns option:
nmcli con mod "System eth1" +ipv4.dns 4.4.4.4
9. Remove DNS Server from Existing Connection
To remove the single DNS server from the connection, run the following command:
Advertisements
nmcli con mod "System eth1" -ipv4.dns 8.8.4.4
To remove the multiple DNS servers from the connection, run the following command:
nmcli con mod "System eth1" -ipv4.dns 8.8.4.4,8.8.2.2
10. Add/Edit Connection Interactively
You can also create a new connection or edit an existing connection using an interactive
editor.
For example, edit an existing connection, run the following command:
nmcli con edit "System eth1"
You should see the following output:
===| nmcli interactive connection editor |===
Editing existing '802-3-ethernet' connection: 'System eth1'
Type 'help' or '?' for available commands.
Type 'print' to show all the connection properties.
Type 'describe [.]' for detailed property description.
You may edit the following settings: connection, 802-3-ethernet (ethernet), 802-1x, dcb, sriov, ethtool, match, ipv4, ipv6, tc, proxy
nmcli>
Now, display an existing IP address, run the following command:
nmcli> print ipv4.address
Output:
ipv4.addresses: 192.168.0.10/32
To set a new IP address, run the following command:
nmcli> set ipv4.address 192.168.0.11
You can verify and save the connection with the following command:
You can also monitor NetworkManager activity using nmcli like, changes in connection state,
profiles, devices, etc.
After modifying the ethernet connection, run the following command to monitor it:
nmcli con monitor "System eth1"
12. Create a New Connection with Static IP
You can also create a new static ethernet connection with nmcli. For example, create a new
ethernet connection named eth2, IP 192.168.0.12/24, Gateway 192.168.0.1, "onboot=yes" by
running the following command:
nmcli con add con-name eth2 type ethernet ifname eth2 ipv4.method manual ipv4.address 192.168.0.15/24 ipv4.gateway 192.168.0.1
Now, verify the connection with the following command:
nmcli con
Output:
NAME UUID TYPE DEVICE
System eth0 5fb06bd0-0bb0-7ffb-45f1-d6edd65f3e03 ethernet eth0
System eth1 9c92fad9-6ecb-3e6c-eb4d-8a47c6f50c04 ethernet eth1
eth2 cefb3f7d-424c-42f8-b4e8-ed54e7dcb880 ethernet eth2
13. Create a New Connection with DHCP
You can also create a new DHCP connection with nmcli. For example, create a new DHCP
ethernet connection named eth3 with the following command:
nmcli con add con-name eth3 type ethernet ifname eth3 ipv4.method auto
To activate the new ethernet connection eth2, run the following command:
nmcli con up eth2
You should see the following output:
Connection successfully activated
You can now verify the active connection with the following command:
nmcli con show --active
You should see the following output:
Output:
NAME UUID TYPE DEVICE
System eth0 5fb06bd0-0bb0-7ffb-45f1-d6edd65f3e03 ethernet eth0
System eth1 9c92fad9-6ecb-3e6c-eb4d-8a47c6f50c04 ethernet eth1
eth2 cefb3f7d-424c-42f8-b4e8-ed54e7dcb880 ethernet eth2
15. Deactivate a Connection
To deactivate the connection eth2, run the following command:
nmcli con down eth2
16. Delete a Connection
You can also delete a specific ethernet connection with nmcli.
For example, to delete a connection eth2, run the following command:
To find the current hostname of your system, run the following command:
nmcli general hostname
You should see the following output:
centos8
Next, change the hostname from centos8 to linux using the following command:
Advertisements
nmcli general hostname linux
Next, verify the hostname with the following command:
nmcli general hostname
You should see the following output:
linux
18. Change the DEFROUTE Directive
The DEFROUTE directive is used to disable and enable the default gateway of your ethernet
connection.
To enable the DEFROUTE directove for eth2 run the following command:
nmcli con mod "System eth2" ipv4.never-default yes
19. Restart Ethernet Connection
You can restart or reload your ethernet connection with the following command:
nmcli con reload
20. nmcli help
To get more information about nmcli command, run the following command:
nmcli --help
You should see the following output:
Usage: nmcli [OPTIONS] OBJECT { COMMAND | help }
OPTIONS
-a, --ask ask for missing parameters
-c, --colors auto|yes|no whether to use colors in output
-e, --escape yes|no escape columns separators in values
-f, --fields <field,...>|all|common specify fields to output
-g, --get-values <field,...>|all|common shortcut for -m tabular -t -f
-h, --help print this help
-m, --mode tabular|multiline output mode
-o, --overview overview mode
-p, --pretty pretty output
-s, --show-secrets allow displaying passwords
-t, --terse terse output
-v, --version show program version
-w, --wait set timeout waiting for finishing operations
OBJECT
g[eneral] NetworkManager's general status and operations
n[etworking] overall networking control
r[adio] NetworkManager radio switches
c[onnection] NetworkManager's connections
d[evice] devices managed by NetworkManager
a[gent] NetworkManager secret agent or polkit agent
m[onitor] monitor NetworkManager changes
Conclusion
In the above guide, we learned how to use nmcli to manage and control ethernet connection in
CentOS 8. I hope you can now easily add, edit or create a new connection with nmcli. Feel free
to ask me if you have any questions.
About Hitesh Jethva
Over 8 years of experience as a Linux system administrator. My skills include a depth
knowledge of Redhat/Centos, Ubuntu Nginx and Apache, Mysql, Subversion, Linux, Ubuntu, web
hosting, web server, Squid proxy, NFS, FTP, DNS, Samba, LDAP, OpenVPN, Haproxy, Amazon web
services, WHMCS, OpenStack Cloud, Postfix Mail Server, Security etc.
Type the following netstat command sudo netstat -tulpn | grep LISTEN
... ... ...
For example, TCP port 631 opened by cupsd process and cupsd only listing on the loopback
address (127.0.0.1). Similarly, TCP port 22 opened by sshd process and sshd listing on all IP
address for ssh connections:
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 0 43385 1821/cupsd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 0 44064 1823/sshd
Where,
-t : All TCP ports
-u : All UDP ports
-l : Display listening server sockets
-p : Show the PID and name of the program to which each socket belongs
-n : Don't resolve names
| grep LISTEN : Only display open ports by applying grep command filter.
Use ss to list open ports
The ss command is used to dump socket statistics. It allows showing information similar to
netstat. It can display more TCP and state information than other tools. The syntax is: sudo ss -tulpn
... ... ...
Vivek Gite is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a
trainer for the Linux operating system/Unix shell scripting. Get the latest tutorials on
SysAdmin, Linux/Unix and open source topics via RSS/XML feed or weekly email newsletter.
IP Aliasing : Assigning multiple IP addresses to single NIC
by Shusain ·
Published April 3, 2019 · Updated April 4, 2019
In this tutorial, we are going to
learn to assign multiple IP addresses to a single NIC (Network Interface Card). This process of
assigning multiple addresses to a single network interface is called IP aliasing.
Main advantage of using IP aliasing is that we don't need multiple NICs to configure
multiple IPs, hence saving us cost & configuration time. IP aliasing is most useful when
using Apache IP based virtual hosting.
For this tutorial, we are going to use RHEL/CentOS 7 but the same process can also be used
older versions of RHEL/CentOS, the only change being the name of the network interfaces other
than that process is same.
Network interfaces files in RHEL/CentOS 7(on older versions as well) are located at '
/etc/sysconfig/network-scripts ' & name of the interfaces are usually ' ifcfg-en0sX ',
where ' X ' is the number of the interface. In my case, its ' ifcfg-en0s0' . So we will be
using the same for the purpose of this tutorial.
Using Network Manager
We will be using a tool called 'nmtui' for this method. NMTUI is command line based user
interface for Network Manager & even works for the system that does not have GUI installed.
Open terminal & enter the command,
Click on 'Edit a connection', & then select the network interface from the list of
interfaces & press ENTER key,
<img
src="https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-2.png?resize=795%2C618&ssl=1"
alt="IP aliasing" width="795" height="618"
srcset="https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-2.png?w=795&ssl=1
795w,
https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-2.png?resize=768%2C597&ssl=1
768w" sizes="(max-width: 795px) 100vw, 795px" data-recalc-dims="1" />
Now we add the required number of IP address here & once done, we can click on 'OK' &
then exit from the nmtui menu. Restart the NetworkManager service & we will have our IP
aliasing ready.
Manual Method
For this method, we will manually create the necessary files needed. We will assign two
different IPs in addition to the one we have already assigned to our interface '
ifcfg-en0s0' . To create IP alias, we are going to use our default network interface
file & then will create two copies of the file with names 'ifcfg-en0s0:1 ' &
'ifcfg-en0s0:2'
Move your dotfiles to version controlBack up or sync your custom configurations
across your systems by sharing dotfiles on GitLab or GitHub. 20 Mar 2019 Matthew Broberg (Red Hat)Feed 11
up4
comments x Get the newsletter
Join the 85,000 open source advocates who receive our giveaway alerts and article
roundups.
What a Shell Dotfile Can Do For
You , H. "Waldo" Grunenwald goes into excellent detail about the why and how of setting
up your dotfiles. Let's dig into the why and how of sharing them. What's a dotfile?
"Dotfiles" is a common term for all the configuration files we have floating around our
machines. These files usually start with a . at the beginning of the filename, like .gitconfig
, and operating systems often hide them by default. For example, when I use ls -a on MacOS, it
shows all the lovely dotfiles that would otherwise not be in the output.
dotfiles on
master
➜ ls
README.md Rakefile bin misc profiles zsh-custom
dotfiles on master
➜ ls -a
. .gitignore .oh-my-zsh README.md zsh-custom
.. .gitmodules .tmux Rakefile
.gemrc .global_ignore .vimrc bin
.git .gvimrc .zlogin misc
.gitconfig .maid .zshrc profiles
If I take a look at one, .gitconfig , which I use for Git configuration, I see a ton of
customization. I have account information, terminal color preferences, and tons of aliases that
make my command-line interface feel like mine. Here's a snippet from the [alias] block:
87 #
Show the diff between the latest commit and the current state
88 d = !"git diff-index --quiet HEAD -- || clear; git --no-pager diff --patch-with-stat"
89
90 # `git di $number` shows the diff between the state `$number` revisions ago and the current
state
91 di = !"d() { git diff --patch-with-stat HEAD~$1; }; git diff-index --quiet HEAD -- || clear;
d"
92
93 # Pull in remote changes for the current repository and all its submodules
94 p = !"git pull; git submodule foreach git pull origin master"
95
96 # Checkout a pull request from origin (of a github repository)
97 pr = !"pr() { git fetch origin pull/$1/head:pr-$1; git checkout pr-$1; }; pr"
Since my .gitconfig has over 200 lines of customization, I have no interest in rewriting it
on every new computer or system I use, and either does anyone else. This is one reason sharing
dotfiles has become more and more popular, especially with the rise of the social coding site
GitHub. The canonical article advocating for sharing dotfiles is Zach Holman's Dotfiles Are
Meant to Be Forked from 2008. The premise is true to this day: I want to share them, with
myself, with those new to dotfiles, and with those who have taught me so much by sharing their
customizations.
Sharing dotfiles
Many of us have multiple systems or know hard drives are fickle enough that we want to back
up our carefully curated customizations. How do we keep these wonderful files in sync across
environments?
My favorite answer is distributed version control, preferably a service that will handle the
heavy lifting for me. I regularly use GitHub and continue to enjoy GitLab as I get more
experienced with it. Either one is a perfect place to share your information. To set yourself
up:
Sign into your preferred Git-based service.
Create a repository called "dotfiles." (Make it public! Sharing is caring.)
Step 4 above is the crux of this effort and can be a bit tricky. Whether you use a script or
do it by hand, the workflow is to symlink from your dotfiles folder to the dotfiles destination
so that any updates to your dotfiles are easily pushed to the remote repository. To do this for
my .gitconfig file, I would enter:
The flags added to the symlinking command offer a few additional benefits:
-s creates a symbolic link instead of a hard link
-f continues with other symlinking when an error occurs (not needed here, but useful in
loops)
-n avoids symlinking a symlink (same as -h for other versions of ln )
You can review the IEEE and Open Group specification of ln and
the version on MacOS
10.14.3 if you want to dig deeper into the available parameters. I had to look up these
flags since I pulled them from someone else's dotfiles.
You can also make updating simpler with a little additional code, like the Rakefile I
forked from Brad Parbs .
Alternatively, you can keep it incredibly simple, as Jeff Geerling does in his dotfiles . He symlinks files using
this Ansible
playbook . Keeping everything in sync at this point is easy: you can cron job or
occasionally git push from your dotfiles folder.
Quick aside: What not to share
Before we move on, it is worth noting what you should not add to a shared dotfile
repository -- even if it starts with a dot. Anything that is a security risk, like files in
your .ssh/ folder, is not a good choice to share using this method. Be sure to double-check
your configuration files before publishing them online and triple-check that no API tokens are
in your files.
There are other incredible resources to help you get started with dotfiles. Years ago, I
came across dotfiles.github.io and
continue to go back to it for a broader look at what people are doing. There is a lot of tribal
knowledge hidden in other people's dotfiles. Take the time to scroll through some and don't be
shy about adding them to your own.
I hope this will get you started on the joy of having consistent dotfiles across your
computers.
What's your favorite dotfile trick? Add a comment or tweet me @mbbroberg . TopicsGitGitHubGitLabAbout the author
Matthew Broberg - Matt loves working with technology communities to develop products and
content that invite delightful engagement. He's a serial podcaster, best known for the
Geek Whisperers podcast , is on the
board of the Influence
Marketing Council , co-maintains the DevRel Collective , and often shares his thoughts on
Twitter and GitHub ... More
about me
See also the rcm suite for managing dotfiles from a central location. This provides the
subdirectory from which you can put your dotfiles into revision control.
An interesting article, Matt, thanks! I was glad to see "what not to share".
While most of my dot files hold no secrets, as you note some do - .ssh, .gnupg,
.local/share among others... could be some others. Thinking about this, my dot files are kind
of like my sock drawer - plenty of serviceable socks there, not sure I would want to share
them! Anyway a neat idea.
If you own a Raspberry Pi, chances are you may already have experimented with physical
computing -- writing code to interact with the real, physical world, like blinking some LEDs or
controlling a servo motor .
You may also have used GPIO Zero , a Python library that provides a
simple interface to GPIO devices from Raspberry Pi with a friendly Python API. GPIO Zero is
developed by Opensource.com community
moderator Ben Nuttall
.
I am working on rust_gpiozero , a port of the awesome GPIO Zero
library that uses the Rust programming language. It is still a work in progress, but it already
includes some useful components.
Rust is a systems programming
language developed at Mozilla. It is focused on performance, reliability, and productivity. The
Rust website has great resources
if you'd like to learn more about it.
Getting started
Before starting with rust_gpiozero, it's smart to have a basic grasp of the Rust programming
language. I recommend working through at least the first three chapters in The Rust Programming Language book.
I recommend installing
Rust on your Raspberry Pi using rustup .
Alternatively, you can set up a cross-compilation environment using cross (which works only on an x86_64 Linux host)
or
this how-to .
After you've installed Rust, create a new Rust project by entering:
Virtual filesystems in Linux: Why we need them and how they work
Virtual filesystems are the magic abstraction that makes the "everything is a file" philosophy of
Linux possible.
08 Mar 2019
Alison Chaiken
Feed
18
up
6 comments
x
Get the newsletter
Join the 85,000 open source advocates who receive our
giveaway alerts and article roundups.
Robert Love
, "A filesystem is a hierarchical storage of data adhering to a specific structure."
However, this description applies equally well to VFAT (Virtual File Allocation Table), Git, and
Cassandra
(a
NoSQL database
). So what
distinguishes a filesystem?
Filesystem basics
The Linux kernel requires that for an entity to be a filesystem, it must also implement the
open()
,
read()
, and
write()
methods on persistent objects
that have names associated with them. From the point of view of
object-oriented programming
, the kernel
treats the generic filesystem as an abstract interface, and these big-three functions are "virtual,"
with no default definition. Accordingly, the kernel's default filesystem implementation is called a
virtual filesystem (VFS).
If
we can open(), read(), and write(), it is a file as this console session shows.
VFS underlies the famous observation that in Unix-like systems "everything is a file." Consider how
weird it is that the tiny demo above featuring the character device
/dev/console
actually
works. The image shows an interactive Bash session on a virtual teletype (tty). Sending a string into
the virtual console device makes it appear on the virtual screen. VFS has other, even odder
properties. For example, it's
possible to
seek in them
.
The familiar filesystems like ext4, NFS, and /proc all provide definitions of the big-three functions
in a C-language data structure called
file_operations
. In addition, particular filesystems extend and override the VFS functions in the
familiar object-oriented way. As Robert Love points out, the abstraction of VFS enables Linux users to
blithely copy files to and from foreign operating systems or abstract entities like pipes without
worrying about their internal data format. On behalf of userspace, via a system call, a process can
copy from a file into the kernel's data structures with the read() method of one filesystem, then use
the write() method of another kind of filesystem to output the data.
The function definitions that belong to the VFS base type itself are found in the
fs/*.c files
in kernel source, while the subdirectories of fs/ contain the specific filesystems.
The kernel also contains filesystem-like entities such as cgroups, /dev, and tmpfs, which are needed
early in the boot process and are therefore defined in the kernel's init/ subdirectory. Note that
cgroups, /dev, and tmpfs do not call the file_operations big-three functions, but directly read from
and write to memory instead.
The diagram below roughly illustrates how userspace accesses various types of filesystems commonly
mounted on Linux systems. Not shown are constructs like pipes, dmesg, and POSIX clocks that also
implement struct file_operations and whose accesses therefore pass through the VFS layer.
VFS
are a "shim layer" between system calls and implementors of specific file_operations like ext4 and
procfs
. The file_operations functions can then communicate either with device-specific drivers or
with memory accessors.
tmpfs
,
devtmpfs
and
cgroups
don't make use of file_operations but access memory directly.
VFS's existence promotes code reuse, as the basic methods associated with filesystems need not be
re-implemented by every filesystem type. Code reuse is a widely accepted software engineering best
practice! Alas, if the reused code
introduces serious bugs
, then all the implementations that inherit the common methods suffer from
them.
/tmp: A simple tip
An easy way to find out what VFSes are present on a system is to type
mount | grep -v sd |
grep -v :/
, which will list all mounted filesystems that are not resident on a disk and not
NFS on most computers. One of the listed VFS mounts will assuredly be /tmp, right?
Why is keeping /tmp on storage
inadvisable? Because the files in /tmp are temporary(!), and storage devices are slower than memory,
where tmpfs are created. Further, physical devices are more subject to wear from frequent writing than
memory is. Last, files in /tmp may contain sensitive information, so having them disappear at every
reboot is a feature.
Unfortunately, installation scripts for some Linux distros still create /tmp on a storage device by
default. Do not despair should this be the case with your system. Follow simple instructions on the
always excellent
Arch Wiki
to
fix the problem, keeping in mind that memory allocated to tmpfs is not available for other purposes.
In other words, a system with a gigantic tmpfs with large files in it can run out of memory and crash.
Another tip: when editing the /etc/fstab file, be sure to end it with a newline, as your system will
not boot otherwise. (Guess how I know.)
/proc and /sys
Besides /tmp, the VFSes with which most Linux users are most familiar are /proc and /sys. (/dev
relies on shared memory and has no file_operations). Why two flavors? Let's have a look in more
detail.
The procfs offers a snapshot into the instantaneous state of the kernel and the processes that it
controls for userspace. In /proc, the kernel publishes information about the facilities it provides,
like interrupts, virtual memory, and the scheduler. In addition, /proc/sys is where the settings that
are configurable via the
sysctl command
are accessible to userspace. Status and statistics on individual processes are
reported in /proc/<PID> directories.
/proc/
meminfo
is an empty file that nonetheless contains valuable information.
The
behavior of /proc files illustrates how unlike on-disk filesystems VFS can be. On the one hand,
/proc/meminfo contains the information presented by the command
free
. On the other
hand, it's also empty! How can this be? The situation is reminiscent of a famous article written by
Cornell University physicist N. David Mermin in 1985 called "
Is
the moon there when nobody looks?
Reality and the quantum theory." The truth is that the kernel
gathers statistics about memory when a process requests them from /proc, and there actually
is
nothing in the files in /proc when no one is looking. As
Mermin said
, "It is a
fundamental quantum doctrine that a measurement does not, in general, reveal a preexisting value of
the measured property." (The answer to the question about the moon is left as an exercise.)
The
files in /proc are empty when no process accesses them. (
Source
)
The apparent emptiness of procfs makes sense, as the information available there is dynamic. The
situation with sysfs is different. Let's compare how many files of at least one byte in size there are
in /proc versus /sys.
Procfs has precisely one, namely the exported kernel configuration, which is an exception since it
needs to be generated only once per boot. On the other hand, /sys has lots of larger files, most of
which comprise one page of memory. Typically, sysfs files contain exactly one number or string, in
contrast to the tables of information produced by reading files like /proc/meminfo.
The purpose of sysfs is to expose the readable and writable properties of what the kernel calls
"kobjects" to userspace. The only purpose of kobjects is reference-counting: when the last reference
to a kobject is deleted, the system will reclaim the resources associated with it. Yet, /sys
constitutes most of the kernel's famous "
stable
ABI to userspace
" which
no one may
ever, under any circumstances, "break."
That doesn't mean the files in sysfs are static, which
would be contrary to reference-counting of volatile objects.
The kernel's stable ABI instead constrains what
can
appear in /sys, not what is actually
present at any given instant. Listing the permissions on files in sysfs gives an idea of how the
configurable, tunable parameters of devices, modules, filesystems, etc. can be set or read. Logic
compels the conclusion that procfs is also part of the kernel's stable ABI, although the kernel's
documentation
doesn't state so explicitly.
Files
in
sysfs
describe exactly one property each for an entity and may be readable, writable or both. The
"0" in the file reveals that the SSD is not removable.
Snooping on VFS with eBPF and bcc tools
The easiest way to learn how the kernel manages sysfs files is to watch it in action, and the
simplest way to watch on ARM64 or x86_64 is to use eBPF. eBPF (extended Berkeley Packet Filter)
consists of a
virtual machine running inside the kernel
that privileged users can query from the command line.
Kernel source tells the reader what the kernel
can
do; running eBPF tools on a booted system
shows instead what the kernel actually
does
.
Happily, getting started with eBPF is pretty easy via the
bcc
tools, which are available as
packages from major
Linux distros
and have been
amply
documented
by Brendan Gregg. The bcc tools are Python scripts with small embedded snippets of C,
meaning anyone who is comfortable with either language can readily modify them. At this count,
there are 80 Python scripts
in bcc/tools
, making it highly likely that a system administrator or developer will find an
existing one relevant to her/his needs.
To get a very crude idea about what work VFSes are performing on a running system, try the simple
vfscount
or
vfsstat
, which show that dozens of calls to vfs_open() and its friends occur every second.
vfsstat.py
is a Python script with an embedded C snippet that simply counts VFS function calls.
For a less trivial example, let's watch what happens in sysfs when a USB stick is inserted on a
running system.
Watch
with eBPF what happens in /sys when a USB stick is inserted, with simple and complex examples.
In the first simple example above, the
trace.py
bcc tools script prints out a message whenever the sysfs_create_files() command runs. We see that
sysfs_create_files() was started by a kworker thread in response to the USB stick insertion, but what
file was created? The second example illustrates the full power of eBPF. Here, trace.py is printing
the kernel backtrace (-K option) plus the name of the file created by sysfs_create_files(). The
snippet inside the single quotes is some C source code, including an easily recognizable format
string, that the provided Python script
induces a LLVM just-in-time compiler
to compile and execute inside an in-kernel virtual machine.
The full sysfs_create_files() function signature must be reproduced in the second command so that the
format string can refer to one of the parameters. Making mistakes in this C snippet results in
recognizable C-compiler errors. For example, if the
-I
parameter is omitted, the
result is "Failed to compile BPF text." Developers who are conversant with either C or Python will
find the bcc tools easy to extend and modify.
When the USB stick is inserted, the kernel backtrace appears showing that PID 7711 is a kworker
thread that created a file called "events" in sysfs. A corresponding invocation with
sysfs_remove_files() shows that removal of the USB stick results in removal of the events file, in
keeping with the idea of reference counting. Watching sysfs_create_link() with eBPF during USB stick
insertion (not shown) reveals that no fewer than 48 symbolic links are created.
What is the purpose of the events file anyway? Using
cscope
to find the function
__device_add_disk()
reveals that it calls disk_add_events(), and either "media_change" or
"eject_request" may be written to the events file. Here, the kernel's block layer is informing
userspace about the appearance and disappearance of the "disk." Consider how quickly informative this
method of investigating how USB stick insertion works is compared to trying to figure out the process
solely from the source.
Read-only root filesystems make
embedded devices possible
Assuredly, no one shuts down a server or desktop system by pulling out the power plug. Why? Because
mounted filesystems on the physical storage devices may have pending writes, and the data structures
that record their state may become out of sync with what is written on the storage. When that happens,
system owners will have to wait at next boot for the
fsck
filesystem-recovery tool
to run and, in the worst case, will actually lose data.
Yet, aficionados will have heard that many IoT and embedded devices like routers, thermostats, and
automobiles now run Linux. Many of these devices almost entirely lack a user interface, and there's no
way to "unboot" them cleanly. Consider jump-starting a car with a dead battery where the power to the
Linux-running head unit
goes up and down repeatedly. How is it that the system boots without a
long fsck when the engine finally starts running? The answer is that embedded devices rely on
a read-only root
fileystem
(ro-rootfs for short).
ro-rootfs
are why embedded systems don't frequently need to fsck. Credit (with permission):
https://tinyurl.com/yxoauoub
A
ro-rootfs offers many advantages that are less obvious than incorruptibility. One is that malware
cannot write to /usr or /lib if no Linux process can write there. Another is that a largely immutable
filesystem is critical for field support of remote devices, as support personnel possess local systems
that are nominally identical to those in the field. Perhaps the most important (but also most subtle)
advantage is that ro-rootfs forces developers to decide during a project's design phase which system
objects will be immutable. Dealing with ro-rootfs may often be inconvenient or even painful, as
const variables in
programming languages
often are, but the benefits easily repay the extra overhead.
Creating a read-only rootfs does require some additional amount of effort for embedded developers,
and that's where VFS comes in. Linux needs files in /var to be writable, and in addition, many popular
applications that embedded systems run will try to create configuration dot-files in $HOME. One
solution for configuration files in the home directory is typically to pregenerate them and build them
into the rootfs. For /var, one approach is to mount it on a separate writable partition while / itself
is mounted as read-only. Using bind or overlay mounts is another popular alternative.
Bind and overlay mounts and their use by
containers
Running
man
mount
is the best place to learn about bind and overlay mounts, which give embedded
developers and system administrators the power to create a filesystem in one path location and then
provide it to applications at a second one. For embedded systems, the implication is that it's
possible to store the files in /var on an unwritable flash device but overlay- or bind-mount a path in
a tmpfs onto the /var path at boot so that applications can scrawl there to their heart's delight. At
next power-on, the changes in /var will be gone. Overlay mounts provide a union between the tmpfs and
the underlying filesystem and allow apparent modification to an existing file in a ro-rootfs, while
bind mounts can make new empty tmpfs directories show up as writable at ro-rootfs paths. While
overlayfs is a proper filesystem type, bind mounts are implemented by the
VFS namespace facility
.
Based on the description of overlay and bind mounts, no one will be surprised that
Linux containers
make heavy use of them. Let's spy on what happens when we employ
systemd-nspawn
to start up a container by running bcc's mountsnoop tool:
The
system-
nspawn
invocation fires up the container while mountsnoop.py runs.
And let's see
what happened:
Running
mountsnoop
during the container "boot" reveals that the container runtime relies heavily on bind
mounts. (Only the beginning of the lengthy output is displayed)
Here,
systemd-nspawn is providing selected files in the host's procfs and sysfs to the container at paths in
its rootfs. Besides the MS_BIND flag that sets bind-mounting, some of the other flags that the "mount"
system call invokes determine the relationship between changes in the host namespace and in the
container. For example, the bind-mount can either propagate changes in /proc and /sys to the
container, or hide them, depending on the invocation.
Summary
Understanding Linux internals can seem an impossible task, as the kernel itself contains a gigantic
amount of code, leaving aside Linux userspace applications and the system-call interface in C
libraries like glibc. One way to make progress is to read the source code of one kernel subsystem with
an emphasis on understanding the userspace-facing system calls and headers plus major kernel internal
interfaces, exemplified here by the file_operations table. The file operations are what makes
"everything is a file" actually work, so getting a handle on them is particularly satisfying. The
kernel C source files in the top-level fs/ directory constitute its implementation of virtual
filesystems, which are the shim layer that enables broad and relatively straightforward
interoperability of popular filesystems and storage devices. Bind and overlay mounts via Linux
namespaces are the VFS magic that makes containers and read-only root filesystems possible. In
combination with a study of source code, the eBPF kernel facility and its bcc interface makes probing
the kernel simpler than ever before.
Many years ago while I was still a Wind*ws user, I tried the same thing. It was a total failure,
so I ditched that idea. Now reading your article, my first thought was "this is not going to..."
and then I realized that indeed it would work! I'm such a chump. Thank you for your article!
The idea of virtual filesystems appears to originate in a 1986 USENIX paper called "Vnodes:
An Architecture for Multiple File System Types in Sun UNIX." You can find it at
Figure 1 looks remarkably like one of the diagrams I made. I thank my co-worker Sam Cramer
for pointing this out. You can find the figure in the slides that accompany the talk at
http://she-devel.com/ChaikenSCALE2019.pdf
Alison, this presentation at SCaLE 17x was my favorite over all 4 days and 15 sessions! Awesome
lecture and live demos. I learned an incredible amount, even as a Linux kernel noob. Really
appreciate the bcc/eBPF demo as well - it was really encouraging to see how easy it is to get
started.
So grateful that you also created this blog post... the recording from SCaLE was totally
botched! Ugh.
Cat can also number a file's lines during output. There are two commands to do this, as shown in the help documentation: -b, --number-nonblank
number nonempty output lines, overrides -n
-n, --number number all output lines
If I use the -b command with the hello.world file, the output will be numbered like this:
$ cat -b hello.world
1 Hello World !
In the example above, there is an empty line. We can determine why this empty line appears by using the -n argument:
$ cat -n hello.world
1 Hello World !
2
$
Now we see that there is an extra empty line. These two arguments are operating on the final output rather than the file contents,
so if we were to use the -n option with both files, numbering will count lines as follows:
$ cat -n hello.world goodbye.world
1 Hello World !
2
3 Good Bye World !
4
$
One other option that can be useful is -s for squeeze-blank . This argument tells cat to reduce repeated empty line output
down to one line. This is helpful when reviewing files that have a lot of empty lines, because it effectively fits more text on the
screen. Suppose I have a file with three lines that are spaced apart by several empty lines, such as in this example, greetings.world
:
$ cat greetings.world
Greetings World !
Take me to your Leader !
We Come in Peace !
$
Using the -s option saves screen space:
$ cat -s greetings.world
Cat is often used to copy contents of one file to another file. You may be asking, "Why not just use cp ?" Here is how I could
create a new file, called both.files , that contains the contents of the hello and goodbye files:
$ cat hello.world goodbye.world > both.files
$ cat both.files
Hello World !
Good Bye World !
$
zcat
There is another variation on the cat command known as zcat . This command is capable of displaying files that have been compressed
with Gzip without needing to uncompress the files with the gunzip
command. As an aside, this also preserves disk space, which is the entire reason files are compressed!
The zcat command is a bit more exciting because it can be a huge time saver for system administrators who spend a lot of time
reviewing system log files. Where can we find compressed log files? Take a look at /var/log on most Linux systems. On my system,
/var/log contains several files, such as syslog.2.gz and syslog.3.gz . These files are the result of the log
management system, which rotates and compresses log files to save disk space and prevent logs from growing to unmanageable file sizes.
Without zcat , I would have to uncompress these files with the gunzip command before viewing them. Thankfully, I can use zcat :
$ cd / var / log
$ ls * .gz
syslog.2.gz syslog.3.gz
$
$ zcat syslog.2.gz | more
Jan 30 00:02: 26 workstation systemd [ 1850 ] : Starting GNOME Terminal Server...
Jan 30 00:02: 26 workstation dbus-daemon [ 1920 ] : [ session uid = 2112 pid = 1920 ] Successful
ly activated service 'org.gnome.Terminal'
Jan 30 00:02: 26 workstation systemd [ 1850 ] : Started GNOME Terminal Server.
Jan 30 00:02: 26 workstation org.gnome.Terminal.desktop [ 2059 ] : # watch_fast: "/org/gno
me / terminal / legacy / " (establishing: 0, active: 0)
Jan 30 00:02:26 workstation org.gnome.Terminal.desktop[2059]: # unwatch_fast: " / org / g
nome / terminal / legacy / " (active: 0, establishing: 1)
Jan 30 00:02:26 workstation org.gnome.Terminal.desktop[2059]: # watch_established: " /
org / gnome / terminal / legacy / " (establishing: 0)
--More--
We can also pass both files to zcat if we want to review both of them uninterrupted. Due to how log rotation works, you need to
pass the filenames in reverse order to preserve the chronological order of the log contents:
$ ls -l * .gz
-rw-r----- 1 syslog adm 196383 Jan 31 00:00 syslog.2.gz
-rw-r----- 1 syslog adm 1137176 Jan 30 00:00 syslog.3.gz
$ zcat syslog.3.gz syslog.2.gz | more
The cat command seems simple but is very useful. I use it regularly. You also don't need to feed or pet it like a real cat. As
always, I suggest you review the man pages ( man cat ) for the cat and zcat commands to learn more about how it can be used. You
can also use the --help argument for a quick synopsis of command line arguments.
Interesting article but please don't misuse cat to pipe to more......
I am trying to teach people to use less pipes and here you go abusing cat to pipe to other commands. IMHO, 99.9% of the time
this is not necessary!
In stead of "cat file | command" most of the time, you can use "command file" (yes, I am an old dinosaur
from a time where memory was very expensive and forking multiple commands could fill it all up)
The following steps will disable NetworkManager service and allows the interface to be
managed only by network service.
1. To check which are the interfaces managed by NetworkManager
# nmcli device status
This displays a table that lists all network interfaces along with their STATE. If Network
Manager is not controlling an interface, its STATE will be listed as unmanaged . Any other
value indicates the interface is under Network Manager control.
2. Stop the NetworkManager service:
# systemctl stop NetworkManager
3. Disable the service permanently:
# systemctl disable NetworkManager
4. To confirm the NetworkManager service has been disabled
# systemctl list-unit-files | grep NetworkManager
5. Add the below parameter in /etc/sysconfig/network-scripts/ifcfg-ethX of interfaces that
are managed by NetworkManager to make it unmanaged.
NM_CONTROLLED="no"
Note: Be sure to change the NM_CONTROLLED="yes" to " no " or the network service may complain
about "Connection activation failed" when it cannot find an interface to start Switching to
"network" service
When the NetworkManager is disabled, the interface can be configured for use with the
network service. Follow the steps below to configure and interface using network services.
1. Set the IP address in the configuration file: /etc/sysconfig/network-scripts/ifcfg-eth0.
Set the NM_CONTROLLED value to no and assign a static IP address in the file.
NetworkManager is by far the most common auto-configuration tool for the entire networking stack including DNS resolution. It's
responsible for /etc/resolv.conf on many popular distribution including Debian and Fedora. After you've disable other programs that
manages resolv.conf, you may also discover that NetworkManager will jump in to fill the job -- as happens on Ubuntu 16.10 and later.
Set the dns option in the main configuration section to none to disable DNS handling in NetworkManager. The below commands sets
this option in a new conf.d/no-dns.conf configuration file, restarts the NetworkManager service, and deletes the NetworkManager-generated
resolv.conf file.
If you discover that NetworkManager is still managing your resolv.conf, then you may have a configuration conflict (usually caused
by dnsmasq). Recursively search through your NetworkManager configuration to discover any conflicts.
grep -ir /etc/NetworkManager/
Refer to the last section of this article for instructions on recreating a /etc/resolv.conf file with manual configuration
TCP / IP communication of RHEL 7 is extremely slow compared with RHEL 6 and earlier.
My application transferd from RHEL 5 to RHEL 7.
That application makes TCP / IP communication with another application on the same server.
That communication speed is about twice slower.
Apart from that, we compared it with "ping localhost". RHEL 7 averaged 0.04 ms, RHEL 6 and
RHEL 5 average 0.02 ms. RHEL 7 is twice as slow as RHEL 6 or earlier.
The environment is the minimum installation, stop firewalld and postfix, then do "ping
localhost".
Why was communication delayed like this?
Or, what is going on late?
Is not it worth it?
Guesses: differences in process scheduling, memory fragmentation, other CPU workload,
timing inaccuracy, incorrect test method, firewall behaviour, system performance differences,
code difference like the security vulnerability mentioned above, probably much more that I
have not thought of.
A good troubleshooting path forward is to identify:
the specific behaviour in your application which is different
what you expect performance to be
what performance measurement you are currently getting
And then look into possible causes. I would start with perf collection during an application run,
and possibly strace of the
application although that can negatively affect performance too.
I see you have "L3 support" through your hardware vendor, possibly you bought RHEL
pre-installed on your system, so the hardware vendor's tech support would be the first place
to ask. The vendor will contact us if they identify a bug in RHEL.
One side note, make sure you really have your dns resolver /etc/resolv.conf set properly.
The suggestions above are of course indeed good, but if your dns is not set properly, you'll
have another round of slowness. Remember that /etc/resolv.conf is populated generally from
the "DNSx" and "DOMAIN" directives found in the active
'/etc/sysconfig/netowrk-scripts/ifcfg-XYZ" file. You can find what interfaces are actually
active by using ip -o -4 a s which will reveal all IPV4 active interfaces with
the interface name in the results at the very far left.
There are instances where if you have a system that is doing a lot of actions that rely on
dns, you could make a dns caching server at your location that would assist with lookups and
cache relevant things for your system.
Again, the other answers above are very useful, on spot, but if your /etc/resolv.conf is
off, or not optimal, it could cause issue.
I have not fully vetted this article where
someone did some additional tuning and it would be good to validate what is in that
article for legitimacy, and make backups of any configurations before making changes.
One last thing, using the rpm iftop can give you an idea of what systems are
hitting your server, or visa versa.
and yes, it is exhaustive, the Red Hat tuning guide
For reference, the Network Performance Tuning Guide PDF is only the original publish. We
have updated the knowledgebase article a couple of times since then:
Using tuned is a good idea... if the tuning profile matches your use case. Users are
encouraged to think of the shipped profiles as just a starting point and develop their own
more customised tuning profile.
sysctl is an interface that allows you to make changes to a running Linux kernel. With
/etc/sysctl.conf you can configure various Linux networking and system settings such as:
Limit network-transmitted configuration for IPv4
Limit network-transmitted configuration for IPv6
Turn on execshield protection
Prevent against the common 'syn flood attack'
Turn on source IP address verification
Prevents a cracker from using a spoofing attack against the IP address of the
server.
Logs several types of suspicious packets, such as spoofed packets, source-routed packets,
and redirects.
Linux
Kernel /etc/sysctl.conf Security Hardening with sysctl
The sysctl command is used to modify kernel parameters at runtime. /etc/sysctl.conf is a
text file containing sysctl values to be read in and set by sysct at boot time. To view current
values, enter: # sysctl -a
# sysctl -A
# sysctl mib
# sysctl net.ipv4.conf.all.rp_filter
# sysctl -a --pattern 'net.ipv4.conf.(eth|wlan)0.arp'
To load settings, enter: # sysctl -p
Sample /etc/sysctl.conf for Linux server hardening
Edit /etc/sysctl.conf or /etc/sysctl.d/99-custom.conf and update it as follows. The file is
documented with comments. However, I recommend reading the official Linux kernel sysctl tuning
help file (see below):
# The following is suitable for dedicated web server, mail, ftp server etc.
# ---------------------------------------
# BOOLEAN Values:
# a) 0 (zero) - disabled / no / false
# b) Non zero - enabled / yes / true
# --------------------------------------
# Controls IP packet forwarding
net.ipv4.ip_forward = 0
# Do not accept source routing
net.ipv4.conf.default.accept_source_route = 0
# Controls the System Request debugging functionality of the kernel
kernel.sysrq = 0
# Controls whether core dumps will append the PID to the core filename
# Useful for debugging multi-threaded applications
kernel.core_uses_pid = 1
# Controls the use of TCP syncookies
# Turn on SYN-flood protections
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_synack_retries = 5
########## IPv4 networking start ##############
# Send redirects, if router, but this is just server
# So no routing allowed
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.default.send_redirects = 0
# Accept packets with SRR option? No
net.ipv4.conf.all.accept_source_route = 0
# Accept Redirects? No, this is not router
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.all.secure_redirects = 0
# Log packets with impossible addresses to kernel log? yes
net.ipv4.conf.all.log_martians = 1
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.default.secure_redirects = 0
# Ignore all ICMP ECHO and TIMESTAMP requests sent to it via broadcast/multicast
net.ipv4.icmp_echo_ignore_broadcasts = 1
# Prevent against the common 'syn flood attack'
net.ipv4.tcp_syncookies = 1
# Enable source validation by reversed path, as specified in RFC1812
net.ipv4.conf.all.rp_filter = 1
# Controls source route verification
net.ipv4.conf.default.rp_filter = 1
########## IPv6 networking start ##############
# Number of Router Solicitations to send until assuming no routers are present.
# This is host and not router
net.ipv6.conf.default.router_solicitations = 0
# Accept Router Preference in RA?
net.ipv6.conf.default.accept_ra_rtr_pref = 0
# Learn Prefix Information in Router Advertisement
net.ipv6.conf.default.accept_ra_pinfo = 0
# Setting controls whether the system will accept Hop Limit settings from a router advertisement
net.ipv6.conf.default.accept_ra_defrtr = 0
#router advertisements can cause the system to assign a global unicast address to an interface
net.ipv6.conf.default.autoconf = 0
#how many neighbor solicitations to send out per address?
net.ipv6.conf.default.dad_transmits = 0
# How many global unicast IPv6 addresses can be assigned to each interface?
net.ipv6.conf.default.max_addresses = 1
########## IPv6 networking ends ##############
#Enable ExecShield protection
#Set value to 1 or 2 (recommended)
#kernel.exec-shield = 2
#kernel.randomize_va_space=2
# TCP and memory optimization
# increase TCP max buffer size setable using setsockopt()
#net.ipv4.tcp_rmem = 4096 87380 8388608
#net.ipv4.tcp_wmem = 4096 87380 8388608
# increase Linux auto tuning TCP buffer limits
#net.core.rmem_max = 8388608
#net.core.wmem_max = 8388608
#net.core.netdev_max_backlog = 5000
#net.ipv4.tcp_window_scaling = 1
# increase system file descriptor limit
fs.file-max = 65535
#Allow for more PIDs
kernel.pid_max = 65536
#Increase system IP port limits
net.ipv4.ip_local_port_range = 2000 65000
# RFC 1337 fix
net.ipv4.tcp_rfc1337=1
Reboot the machine soon after a kernel
panic
kernel.panic=10
Addresses of mmap base, heap, stack and VDSO page are randomized
kernel.randomize_va_space=2
Ignore bad ICMP errors
net.ipv4.icmp_ignore_bogus_error_responses=1
Protects against creating or following links under certain conditions
I was setting up a RHEL7 server in vmware vSphere and I'm having trouble getting it on the network without NetworkManager.
I configured the server to have a static IP during the install process and it set everything up using NetworkManager. While this
does work we do not use NetworkManager in my office, so I went and entered what we usually put the config file to get RHEL6 servers
online without NetworkManager.
/etc/sysconfig/network-scripts/ifcfg-ens192 is the following:
I recently debugged an issue with network.service and the best way to track the ip commands was strace
. You shouldn't generally get this type of error. It might be worth reporting (ideally via support). –
Check your MAC Address for the VM. It should be 08:00:27:98:8e:df since that is what is shown you ran ip addr. If it's anything
else, you will need to set it in your ifcfg-ens192 file with the following, but replace the address with the actual.
If you are not sure of the hardware address you can find it in.
cat /sys/class/net/ens192/address
you should put that information (GATEWAY=10.0.2.2) in /etc/sysconfig/network once it's done, restarting the service should succeed
Try to go to the virtual machine network settings and make sure the network cable is connected and check if you have blocked this
with a firewall
NetworkManager dictates the default route ( ip route ) even though your interface has nm disabled, it is just that interface not
the whole system.
ps aux | grep -I net # will probably find NetworkManager still running.
chkconfig NetworkManager off
systemctl disable NetworkManager.service
systemctl disable doesn't stop a service, nor does chkconfig ... off which basically translates to the
same command anyway. – Pavel Šimerda
I too came across "Failed to start LSB: Bring up/down networking" error, since disabling NetworkManager. It took two minutes to be
brought up interfaces after boot. The cause of confusion was "... LSB". It turned out the message comes out from just the traditional
/etc/rc.d/init.d/network script. In my case, following solved the problem;
To network-scripts/ifcfg-eth0 added
NMCONTROLLED=no
Removed unnecessary ifcfg-* files which NetworkManager has left behind
Now edit /etc/sysconfig/network-scripts/ifcfg-eth0,
Add new HWADDR generated or remove it
Remove UUID line
-Restart the networking service
#systemctl restart network.service
NOW! Working.
I was having the same issue. So I just delete the backup files I made in /etc/sysconfig/network-scripts , such as
ifcfg-Bridge_connection_1.home and ifcfg-Bridge_connection_1.office which I created for backup usage. They
should not be created there. The /etc/init.d/network restart could work well after delete those useless ifcfg-*.
Okay community, let's see if we can figure this one out, cause I'm out of answers.
Where I work I am setting up a bunch of RedHat Enterprise Linux servers. There is a collection of RHEL6 and RHEL7 servers.
On the RHEL6 servers, I am using the standard network configuration tool by configuring it in /etc/sysconfig/network-scripts/ifcfg-eth0
and a dhclient configuration file in /etc/dhclient-eth0.conf . Everything works properly, I am assigned the custom
FQDN by our DNS servers (e.g. hostname.ad.company.tld ) and when the DHCP lease is up, it is renewed automatically.
Here is the issue:
In RHEL7, NetworkManager is enabled by default. On our Kickstart, I have removed NetworkManager and went back to configuring
network and dhcp the way it is done in RHEL6. All of the configuration is the same (sans using /etc/sysconfig/network-scripts/ifcfg-ens192
instead of eth0) and works fine for the first DHCP lease.
Once the lease is up, it seemingly doesn't renew it until I issue a systemctl restart network command.
I have looked and looked and I am coming up short. There must be something different in RHEL7 or something not configured when
you disable NetworkManager , but I cannot for the life of me figure it out.
Anyone have any thoughts?
As I know these usually help, I'll post my RHEL7 configuration files, and the snippet from the logs where it loses the DHCP
lease.
Jun 27 23:06:09 sa-kbwiki01 avahi-daemon[591]: Withdrawing address record for 129.89.78.221 on ens192.
Jun 27 23:06:09 sa-kbwiki01 avahi-daemon[591]: Leaving mDNS multicast group on interface ens192.IPv4 with address xxx.xx.xx.xxx.
Jun 27 23:06:09 sa-kbwiki01 avahi-daemon[591]: Interface ens192.IPv4 no longer relevant for mDNS.
That log snippet doesn't show your DHCP lease being lost. Keep looking, there should be other more relevant entries. –
Michael Hampton ♦
Jul 2 '14 at 15:24
From what I recall hearing pre-launch is that networkManager is not the same PoS it was years ago and Red Hat more or less forces
you to learn to live with it. Having said that, the
documentation mentions that NetworkManager has been made responsible for starting dhclient, so it could be that without NM, dhclient
is run with the -1 option and doesn't become a daemon. –
HBruijn ♦
Jul 2 '14 at 15:36
@MichaelHampton I do not see anything else in /var/log/messages. Other things that use the network are operating fine until that
line, at which point everything starts saying no network available. –
cjmaio
Jul 2 '14 at 15:59
@HBruijn That gives me somewhere to start... though when doing a ps aux | grep dhclient I do see that the -1
flag is being set... is there anywhere else that dhclient would log to other than /var/log/messages ? –
cjmaio
Jul 2 '14 at 16:00
Yeah, NM is fairly safe to use these days unless you have a very complicated setup. I do wonder why you're running Avahi
though. – Michael Hampton ♦
Jul 2 '14 at 16:01
One of the things I quickly found to be bothering me is the fact that there was an apparently long and unexplicable
delay for all new network connections which resembled to a dns resolving. No reason for lengthy dns resolving though.
So I did a strace:
the results shows a connection to a avahi-daemon which I have no ideea what is good for so I should not need it.
I disabled it in /etc/default/avahi-daemon
vi /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=myhostname
GATEWAY=10.10.1.1
Make sure your DNS entries are correct. Set them to the correct values, whatever those are. For example:
vi /etc/resolv.conf
nameserver 10.10.1.13
nameserver 10.10.1.14
search mydomain.com
Save the file & restart the network service:
service network restart
The GUI Tool
You can also launch the system-config-network tool in GUI mode. From a command line where you are running
X-Windows, type system-config-network, or chose System / Administration / Network from the menu
A couple of commands are used to configure the network interfaces and initialize the routing table.
These tasks are usually performed from the network initialization script each time you boot the system. The basic tools
for this process are called ifconfig (where "if" stands for interface) and
route.
ifconfig is used to make an interface accessible to the kernel networking
layer. This involves the assignment of an IP address and other parameters, and activation of the interface, also known
as "bringing up" the interface. Being active here means that the kernel will send and receive IP datagrams through the
interface. The simplest way to invoke it is with:
ifconfig interfaceip-address
This command assigns ip-address to interface and
activates it. All other parameters are set to default values. For instance, the default network mask is derived from
the network class of the IP address, such as 255.255.0.0 for a class B address.
ifconfig is described in detail in the section "All About ifconfig".
route allows you to add or remove routes from the kernel routing table. It
can be invoked as:
route [add|del] [-net|-host] target [if]
The add and del arguments determine whether to add or delete
the route to target. The -net and -host arguments
tell the route command whether the target is a network or a host (a host is assumed if you don't specify). The
if argument is again optional, and allows you to specify to which network interface the route
should be directed -- the Linux kernel makes a sensible guess if you don't supply this information. This topic will
be explained in more detail in succeeding sections.
The very first interface to be activated is the loopback interface:
# ifconfig lo 127.0.0.1
Occasionally, you will see the dummy hostname localhost being used
instead of the IP address. ifconfig will look up the name in the hosts
file, where an entry should declare it as the hostname for 127.0.0.1:
# Sample /etc/hosts entry for localhost
localhost 127.0.0.1
To view the configuration of an interface, you invoke ifconfig, giving it
only the interface name as argument:
$ ifconfig lo
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:3924 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
Collisions:0
As you can see, the loopback interface has been assigned a netmask of
255.0.0.0, since 127.0.0.1 is a class A address.
Now you can almost start playing with your mini-network. What is still missing is an entry in the routing
table that tells IP that it may use this interface as a route to destination 127.0.0.1.
This is accomplished by using:
# route add 127.0.0.1
Again, you can use localhost instead of the IP address, provided
you've entered it into your /etc/hosts.
Next, you should check that everything works fine, for example by using ping.
# ping localhost
PING localhost (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=255 time=0.4 ms
64 bytes from 127.0.0.1: icmp_seq=1 ttl=255 time=0.4 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=255 time=0.4 ms
^C
--- localhost ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.4/0.4/0.4 ms
#
When you invoke ping as shown here, it will continue emitting packets forever,
unless interrupted by the user. The ^C marks the place where we pressed Ctrl-C.
The previous example shows that packets for 127.0.0.1 are properly
delivered and a reply is returned to ping almost instantaneously. This shows that you have
successfully set up your first network interface.
If the output you get from ping does not resemble that shown in the previous
example, you are in trouble. Check any errors if they indicate that some file hasn't been installed properly. Check
that the ifconfig and route binaries you use are compatible with
the kernel release you run, and above all, that the kernel has been compiled with networking enabled (you see this from
the presence of the /proc/net directory). If you get an error message saying "Network unreachable,"
you probably got the route command wrong. Make sure you use the same address you gave to
ifconfig.
The steps previously described are enough to use networking applications on a standalone host. After
adding the lines mentioned earlier to your network initialization script and making sure it will be executed at boot
time, you may reboot your machine and try out various applications. For instance, telnet localhost
should establish a telnet connection to your host, giving you a login:
prompt.
However, the loopback interface is useful not only as an example in networking books, or as a test bed
during development, but is actually used by some applications during normal operation.[5]
Therefore, you always have to configure it, regardless of whether your machine is attached to a network or not.
[5] For example, all applications based
on RPC use the loopback interface to register themselves with the portmapper daemon at
startup. These applications include NIS and NFS.
Configuring an Ethernet interface is pretty much the same as the loopback interface; it just requires
a few more parameters when you are using subnetting.
At the Virtual Brewery, we have subnetted the IP network, which was originally a class B network, into
class C subnetworks. To make the interface recognize this, the ifconfig incantation would
look like this:
# ifconfig eth0 vstout netmask 255.255.255.0
This command assigns the eth0 interface the IP address of
vstout (172.16.1.2). If we omitted the netmask,
ifconfig would deduce the netmask from the IP network class, which would result in an incorrect
netmask of 255.255.0.0. Now a quick check shows:
You can see that ifconfig automatically sets the broadcast address (the
Bcast field) to the usual value, which is the host's network number with all the host
bits set. Also, the maximum transmission unit (the maximum size of IP datagrams the kernel will generate for this interface)
has been set to the maximum size of Ethernet packets: 1,500 bytes. The defaults are usually what you will use, but all
these values can be overidden if required, with special options that will be described under "All About ifconfig".
Just as for the loopback interface, you now have to install a routing entry that informs the kernel
about the network that can be reached through eth0. For the Virtual Brewery, you might invoke
route as:
# route add -net 172.16.1.0
At first this looks a little like magic, because it's not really clear how route
detects which interface to route through. However, the trick is rather simple: the kernel checks all interfaces that
have been configured so far and compares the destination address (172.16.1.0 in this
case) to the network part of the interface address (that is, the bitwise AND of the interface address and the netmask).
The only interface that matches is eth0.
Now, what's that -net option for? This is used because route
can handle both routes to networks and routes to single hosts (as you saw before with
localhost). When given an address in dotted quad notation, route attempts to guess whether
it is a network or a hostname by looking at the host part bits. If the address's host part is zero,
route assumes it denotes a network; otherwise, route takes it
as a host address. Therefore, route would think that 172.16.1.0
is a host address rather than a network number, because it cannot know that we use subnetting. We have to tell
route explicitly that it denotes a network, so we give it the -net
flag.
Of course, the route command is a little tedious to type, and it's prone
to spelling mistakes. A more convenient approach is to use the network names we defined in /etc/networks.
This approach makes the command much more readable; even the -net flag can be omitted because
route knows that 172.16.1.0 denotes a network:
# route add brew-net
Now that you've finished the basic configuration steps, we want to make sure that your Ethernet interface
is indeed running happily. Choose a host from your Ethernet, for instance vlager,
and type:
# ping vlager
PING vlager: 64 byte packets
64 bytes from 172.16.1.1: icmp_seq=0. time=11. ms
64 bytes from 172.16.1.1: icmp_seq=1. time=7. ms
64 bytes from 172.16.1.1: icmp_seq=2. time=12. ms
64 bytes from 172.16.1.1: icmp_seq=3. time=3. ms
^C
----vstout.vbrew.com PING Statistics----
4 packets transmitted, 4 packets received, 0
round-trip (ms) min/avg/max = 3/8/12
If you don't see similar output, something is broken. If you encounter unusual packet loss rates, this
hints at a hardware problem, like bad or missing terminators. If you don't receive any replies at all, you should check
the interface configuration with netstat described later in "The netstat Command". The packet
statistics displayed by ifconfig should tell you whether any packets have been sent out on
the interface at all. If you have access to the remote host too, you should go over to that machine and check the interface
statistics. This way you can determine exactly where the packets got dropped. In addition, you should display the routing
information with route to see if both hosts have the correct routing entry.
route prints out the complete kernel routing table when invoked without any arguments (-n
just makes it print addresses as dotted quad instead of using the hostname):
# route -n
Kernel routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
127.0.0.1 * 255.255.255.255 UH 1 0 112 lo
172.16.1.0 * 255.255.255.0 U 1 0 10 eth0
The detailed meaning of these fields is explained later in "The netstat Command". The
Flags column contains a list of flags set for each interface.
U is always set for active interfaces, and H says
the destination address denotes a host. If the H flag is set for a route that you
meant to be a network route, you have to reissue the route command with the
-net option. To check whether a route you have entered is used at all, check to see if the
Use field in the second to last column increases between two invocations of
ping.
In the previous section, we covered only the case of setting up a host on a single Ethernet. Quite frequently,
however, one encounters networks connected to one another by gateways. These gateways may simply link two or more Ethernets,
but may also provide a link to the outside world, such as the Internet. In order to use a gateway, you have to provide
additional routing information to the networking layer.
The Ethernets of the Virtual Brewery and the Virtual Winery are linked through such a gateway, namely
the host vlager. Assuming that vlager has already
been configured, we just have to add another entry to vstout's routing table that
tells the kernel it can reach all hosts on the Winery's network through vlager. The
appropriate incantation of route is shown below; the gw
keyword tells it that the next argument denotes a gateway:
# route add wine-net gw vlager
Of course, any host on the Winery network you wish to talk to must have a routing entry for the Brewery's
network. Otherwise you would only be able to send data to the Winery network from the Brewery network, but the hosts
on the Winery would be unable to reply.
This example describes only a gateway that switches packets between two isolated Ethernets. Now assume
that vlager also has a connection to the Internet (say, through an additional SLIP
link). Then we would want datagrams to any destination network other than the Brewery to be
handed to vlager. This action can be accomplished by making it the default gateway
for vstout:
# route add default gw vlager
The network name default is a shorthand for
0.0.0.0, which denotes the default route. The default route matches every destination
and will be used if there is no more specific route that matches. You do not have to add this name to
/etc/networks because it is built into route.
If you see high packet loss rates when pinging a host behind one or more gateways, this may hint at
a very congested network. Packet loss is not so much due to technical deficiencies as to temporary excess loads on forwarding
hosts, which makes them delay or even drop incoming datagrams.
Configuring a machine to switch packets between two Ethernets is pretty straightforward. Assume we're
back at vlager, which is equipped with two Ethernet cards, each connected to one
of the two networks. All you have to do is configure both interfaces separately, giving them their respective IP addresses
and matching routes, and that's it.
It is quite useful to add information on the two interfaces to the hosts file
as shown in the following example, so we have handy names for them, too:
If this sequence doesn't work, make sure your kernel has been compiled with support for IP forwarding
enabled. One good way to do this is to ensure that the first number on the second line of /proc/net/snmp
is set to 1.
Over the past few years, Linux has made its way into the data centers of many corporations all over
the globe. The Linux operating system has become accepted by both the scientific and enterprise user population. Today,
Linux is by far the most versatile operating system. You can find Linux on embedded devices such as firewalls and cell
phones and mainframes. Naturally, performance of the Linux operating system has become a hot topic for both scientific
and enterprise users. However, calculating a global weather forecast and hosting a database impose different requirements
on the operating system. Linux has to accommodate all possible usage scenarios with the most optimal performance. The
consequence of this challenge is that most Linux distributions contain general tuning parameters to accommodate all
users.
IBM® has embraced Linux, and it is recognized as an operating system suitable for enterprise-level applications running
on IBM systems. Most enterprise applications are now available on Linux, including file and print servers, database
servers, Web servers, and collaboration and mail servers.
With use of Linux in an enterprise-class server comes the need to monitor performance and, when necessary, tune the
server to remove bottlenecks that affect users. This IBM Redpaper describes the methods you can use to tune Linux, tools
that you can use to monitor and analyze server performance, and key tuning parameters for specific server applications.
The purpose of this redpaper is to understand, analyze, and tune the Linux operating system to yield superior performance
for any type of application you plan to run on these systems.
The tuning parameters, benchmark results, and monitoring tools used in our test environment were executed on Red
Hat and Novell SUSE Linux kernel 2.6 systems running on IBM System x servers and IBM System z servers. However, the
information in this redpaper should be helpful for all Linux hardware platforms.
You've just had your first cup of coffee and have received that dreaded phone call. The system is slow.
What are you going to do? This article will discuss performance bottlenecks and optimization in Red Hat Enterprise Linux
(RHEL5).
Before getting into any monitoring or tuning specifics, you should always use some kind of tuning methodology. This
is one which I've used successfully through the years:
1. Baseline – The first thing you must do is establish a baseline, which is a snapshot of how the system appears
when it's performing well. This baseline should not only compile data, but also document your system's configuration
(RAM, CPU and I/O). This is necessary because you need to know what a well-performing system looks like prior to fixing
it.
2. Stress testing and monitoring – This is the part where you monitor and stress your systems at peak workloads.
It's the monitoring which is key here – as you cannot effectively tune anything without some historic trending data.
3. Bottleneck identification – This is where you come up with the diagnosis for what is ailing your system.
The primary objective of section 2 is to determine the bottleneck. I like to use several monitoring tools here. This
allows me to cross-reference my data for accuracy.
4. Tune – Only after you've identified the bottleneck can you tune it.
5. Repeat – Once you've tuned it, you can start the cycle again – but this time start from step 2 (monitoring)
– as you already have your baseline.
It's important to note that you should only make one change at a time. Otherwise, you'll never know exactly what
impacted any changes which might have occurred. It is only by repeating your tests and consistently monitoring your
systems that you can determine if your tuning is making an impact.
RHEL monitoring tools
Before we can begin to improve the performance of our system, we need to use the monitoring tools available to us
to baseline. Here are some monitoring tools you should consider using:
This tool (made available in
RHEL5) utilizes the processor to retrieve kernel system information about system executables. It allows one to collect
samples of performance data every time a counter detects an interrupt. I like the tool also
because it carries little overhead – which is very important because you don't want monitoring tools to be causing system
bottlenecks. One important limitation is that the tool is very much geared towards finding problems with
CPU limited processes. It does not identify processes which are sleeping or waiting on I/O.
The steps used to start up Oprofile include setting up the profiler, starting it and then dumping the data.
First we'll set up the profile. This option assumes that one wants to monitor the kernel.
This tool (introduced in RHEL5) collects data by analyzing the running kernel. It really helps one come up with a
correct diagnosis of a performance problem and is tailor-made for developers. SystemTap eliminates the need for the
developer to go through the recompile and reinstallation process to collect data.
This is another tool which was introduced
by Red Hat in RHEL5. What does it do for you? It allows both developers and system administrators to monitor running
processes and threads. Frysk differs from Oprofile in that it uses 100% reliable information (similar to SystemTap)
- not just a sampling of data. It also runs in user mode and does not require kernel modules or elevated privileges.
Allowing one to stop or start running threads or processes is also a very useful feature.
Some more general Linux tools include
top and
vmstat. While these are considered more
basic, often I find them much more useful than more complex tools. Certainly they are easier to use and can help provide
information in a much quicker fashion.
Top provides a quick snapshot of what is going on in your system – in a friendly character-based display.
It also provides information on CPU, Memory and Swap Space.
Let's look at vmstat – one of the oldest but more important Unix/Linux tools ever created. Vmstat allows one
to get a valuable snapshot of process, memory, sway I/O and overall CPU utilization.
Now let's define some of the fields:
Memory
swpd – The amount of virtual memory
free – The amount of free memory
buff – Amount of memory used for buffers
cache – Amount of memory used as page cache
Process
r – number of run-able processes
b – number or processes sleeping. Make sure this number does not exceed the amount of run-able processes, because
when this condition occurs it usually signifies that there are performance problems.
Swap si – the amount of memory swapped in from disk
so – the amount of memory swapped out.
This is another important field you should be monitoring – if you are swapping out data, you will likely be having performance
problems with virtual memory.
CPU us – The % of time spent in user-level code.
It is preferable for you to have processes which spend more time in user code rather than system code. Time spent in
system level code usually means that the process is tied up in the kernel rather than processing real data. sy – the time spent in system level code
id – the amount of time the CPU is idle wa – The amount of time the system is spending waiting for I/O.
If your system is waiting on I/O – everything tends to come to a halt. I start to get worried when this is > 10.
There is also:
Free – This tool provides memory information, giving you data around the total amount of free and used physical
and swap memory.
Now that we've analyzed our systems – lets look at what we can do to optimize and tune our systems.
CPU Overhead – Shutting Running Processes
Linux starts up all sorts of processes which are usually not required. This includes processes such as autofs, cups,
xfs, nfslock and sendmail. As a general rule, shut down anything that isn't explicitly required. How do you do this?
The best method is to use the chkconfig command.
Here's how we can shut these processes down. [root ((Content component not found.)) _29_140_234 ~]# chkconfig --del xfs
You can also use the GUI - /usr/bin/system-config-services to shut down daemon process.
Tuning the kernel
To tune your kernel for optimal performance, start with:
sysctl – This is the command we use for changing kernel parameters. The parameters themselves are found in
/proc/sys/kernel
Let's change some of the parameters. We'll start with the msgmax parameter. This parameter specifies the maximum
allowable size of a single message in an IPC message queue. Let's view how it currently looks.
[root ((Content component not found.)) _29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 65536
[root ((Content component not found.)) _29_139_52 ~]#
There are three ways to make these kinds of kernel changes. One way is to change this using the echo command.
[root ((Content component not found.)) _29_139_52 ~]# echo 131072 >/proc/sys/kernel/msgmax
[root ((Content component not found.)) _29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 131072
[root ((Content component not found.)) _29_139_52 ~]#
Another parameter that is changed quite frequently is SHMMAX, which is used to define the maximum size (in
bytes) for a shared memory segment. In Oracle this should be set large enough for the largest SGA size. Let's look at
the default parameter:
# sysctl kernel.shmmax
kernel.shmmax = 268435456
This is in bytes – which translates to 256 MG. Let's change this to 512 MG, using the -w flag.
[root ((Content component not found.)) _29_139_52 ~]# sysctl -w kernel.shmmax=5368709132
kernel.shmmax = 5368709132
[root ((Content component not found.)) _29_139_52 ~]#
The final method for making changes is to use a text editor such as vi – directly editing the /etc/sysctl.conf
file to manually make our changes.
To allow the parameter to take affect dynamically without a reboot, issue the sysctl command with the -p parameter.
Obviously, there is more to performance tuning and optimization than we can discuss in the context of this small
article – entire books have been written on Linux performance tuning. For those of you first getting your hands dirty
with tuning, I suggest you tread lightly and spend time working on development, test and/or sandbox environments prior
to deploying any changes into production. Ensure that you monitor the effects of any changes that you make immediately;
it's imperative to know the effect of your change. Be prepared for the possibility that fixing your bottleneck has created
another one. This is actually not a bad thing in itself, as long as your overall performance has improved and you understand
fully what is happening.
Performance monitoring and tuning is a dynamic process which does not stop after you have fixed a problem. All you've
done is established a new baseline. Don't rest on your laurels, and understand that performance monitoring must be a
routine part of your role as a systems administrator.
About the author: Ken Milberg is a systems consultant with two decades of experience working with Unix
and Linux systems. He is a SearchEnterpriseLinux.com Ask the Experts advisor and columnist.
Before you learn how to configure your system, you should learn how to gather essential system> information. For
example, you should know how to find the amount of free memory, the amount of available hard drive space, how your hard
drive is partitioned, and what processes are running. This chapter discusses how to retrieve this type of information
from your Red Hat Enterprise Linux system using simple commands and a few simple programs.
1. System Processes
The
ps ax command displays a list of current
system processes, including processes owned by other users. To display the owner alongside each process, use the
ps aux command. This list is a static list;
in other words, it is a snapshot of what was running when you invoked the command. If you want a constantly updated
list of running processes, use top as described
below. The ps output can be long. To prevent
it from scrolling off the screen, you can pipe it through less:
ps aux | less
You can use the
ps command in combination
with the grep command to see if a process is
running. For example, to determine if Emacs is running, use the following
command:
ps ax | grep emacs
The
top command displays currently running
processes and important information about them including their memory and CPU usage. The list is both real-time and
interactive. An example of output from the top
command is provided as follows:
To exit top press the q key. Useful interactive commands that you can use:
Space
Immediately refresh the display
h
Display a help screen
k
Kill a process. You are prompted for the
process ID and the signal to send to it.
n Change the number of processes displayed.
You are prompted to enter the number.
u Sort by user.
M Sort by memory usage.
P Sort by CPU usage.
For more information, refer to the top(1) manual
page.
Over the past few years, Linux has made its way into the data centers of many corporations all over the globe. The Linux
operating system has become accepted by both the scientific and enterprise user population. Today, Linux is by far the
most versatile operating system. You can find Linux on embedded devices such as firewalls and cell phones and mainframes.
Naturally, performance of the Linux operating system has become a hot topic for both scientific and enterprise users.
However, calculating a global weather forecast and hosting a database impose different requirements on the operating
system. Linux has to accommodate all possible usage scenarios with the most optimal performance. The consequence of
this challenge is that most Linux distributions contain general tuning parameters to accommodate all users.
IBM® has
embraced Linux, and it is recognized as an operating system suitable for enterprise-level applications running on IBM
systems. Most enterprise applications are now available on Linux, including file and print servers, database servers,
Web servers, and collaboration and mail servers.
With use of Linux in an enterprise-class server comes the need to monitor performance and, when necessary, tune the
server to remove bottlenecks that affect users. This IBM Redpaper describes the methods you can use to tune Linux, tools
that you can use to monitor and analyze server performance, and key tuning parameters for specific server applications.
The purpose of this redpaper is to understand, analyze, and tune the Linux operating system to yield superior performance
for any type of application you plan to run on these systems.
The tuning parameters, benchmark results, and monitoring tools used in our test environment were executed on Red
Hat and Novell SUSE Linux kernel 2.6 systems running on IBM System x servers and IBM System z servers. However, the
information in this redpaper should be helpful for all Linux hardware platforms. >
Need to stress out an ftp server, or measure how many users it can support? dkftpbench can do it.
Want to write your own highly efficient networking software, but annoyed by having to support very different
code for Linux, FreeBSD, and Solaris? libPoller can help.
dklimits
a simple util to check the actually number of file descriptors available, ephemeral ports available, and poll()-able
sockets. Handy. Be warned that it can take a while to run if there are a large number of fd's available, as
it will try to open that many files, and then unlinkt them.
A util for determining the number of pthreads a system can use. This and fd-count are both from the system tuning
page for Volano chat, a multithread java based chat server.
The Last but not LeastTechnology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
FAIR USE NOTICEThis site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a 'fair use' of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree...
You can use PayPal to to buy a cup of coffee for authors
of this site
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society.We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.
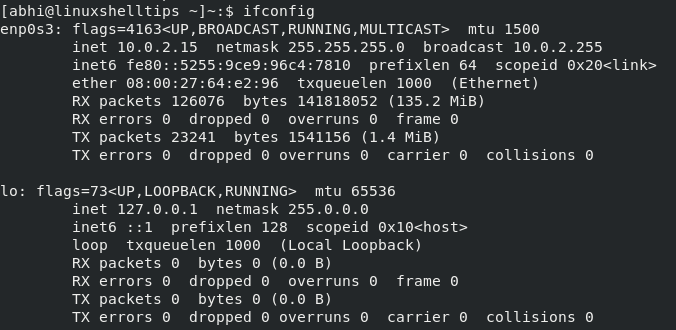


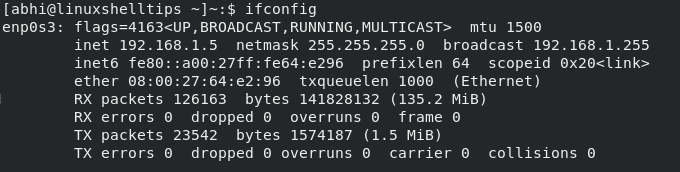

<img src="https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-1.png?resize=425%2C366&ssl=1" alt="IP aliasing" width="425" height="366" data-recalc-dims="1" />
<img src="https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-2.png?resize=795%2C618&ssl=1" alt="IP aliasing" width="795" height="618" srcset="https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-2.png?w=795&ssl=1 795w, https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2019/04/IP-Alias-2.png?resize=768%2C597&ssl=1 768w" sizes="(max-width: 795px) 100vw, 795px" data-recalc-dims="1" />
<img src="https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/03/ifconfig.jpg?resize=545%2C301&ssl=1" alt="ip aliasing" width="545" height="301" srcset="https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/03/ifconfig.jpg?w=545&ssl=1 545w, https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/03/ifconfig.jpg?resize=300%2C166&ssl=1 300w" sizes="(max-width: 545px) 100vw, 545px" data-recalc-dims="1" />