|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| Sorting | Recommended Books | Recommended Links | Shellsort | Mergesort | Heapsort | |
| Animations | Test suits | Donald Knuth | The Art of Computer Programming | History | Humor | Etc |
|
|
Quicksort is an efficient and until lately the most fashionable sorting algorithm invented by C.A.R. Hoare in 1962 while he was in Moscow and was first publish in 1962 in British Computer Society monthly Computer Journal (Hoare, C. A. R. "Quicksort." Computer Journal 5 (1): 10-15. (1962). ). So it is three years older than shellsort. At the same time on modern CPUs with large caches and modern compilers, heapsort will actually outperform quicksort both theoretically and in practice (Sorting revisited). See also Heapsort, Quicksort, and Entropy
Quicksort is not stable. The algorithm is well described in Quicksort - Wikipedia, the free encyclopedia so we will concentrate on non-trivial points rather then simple tutorial.
|
|
Algorithms has two phases:
It is important to understand that quicksort is efficient only on the average, and its worst case is n2 , while heapsort has an interesting property that the worst case is not much different from the an average case.
If the choice of pivot always results in equal-sized (or close to equal-sized) partitions before and after the pivot, then quick sort will run in O(N log N) time. But there no way to guarantee that the pivot will result in this outcome. Choosing a bad pivot (equal to the min or max element in the region being sorted) would result in subregions of size 1 and size N-1. If a bad pivot is chosen at every step, then the total running time will be O(N2). (The problem is that we are only eliminating one element, the pivot, at each step!)For this reason more modern algorithms textbooks that cover sorting is sufficient details actually pay more attention to heapsort then quicksort. Moreover presence of the honest discussion of fundamental weaknesses of quicksort can serve as a litmus text of the quality of the textbook.
As size of the array increases merge-sort became more and more competitive and eventually overtakes both heapsort and quicksort.
In pseudocode the algorithm looks like:
The quicksort algorithm requires O(log n) extra storage space, making it not a strictly in-place algorithm. but O(log n) is a very small number and does not matter much on modern computers.
It is important to understand that Quicksort can go quadratic in the worst case. The worst case time for Quicksort is the same as for insertion sort and other simple algorithms, which is substantially worse than Heapsort or Mergesort. Moreover no matter what kind of improvement you use for quicksort, the worst case remains O(n2).
And it's not difficult to imagine such case: chainsaw data completely kill the idea. In this case instead of partitioning into two segments we have one segment too small to be useful. If at any stage the pivot is close to maximum value of the segment the partitions will be lopsided. See also [PDF] A Killer Adversary for Quicksort
And far from optimal for Quicksort cases are far more frequent in real data that people assume. What is worse is that "bad data" for Quicksort can arise dynamically during sorting of a large non-random array. This "self-poisoning of data" behavior of Quicksort is an interesting phenomenon that requires further study.
It is clear that the main work is done in the partition phase, so the quality of division of the set into two sub-partitions is crucial. For the strategy to be effective, the partition phase must ensure that two partitions are almost equal in size. This is an unsolvable problem. The most common "compromize" solution is "selection-based pivoting" when you select middle element of three elements (left, right and middle, or randomly chosen). You can also sort a small area (say 8 elements) in the middle of the current segment using insertion sort and pickup the middle element. the latter allow to avoid the worst case: when one of the partitions has the size of one (contains a single element). Also problematic are:
In general, Quicksort a good example of the divide and conquer strategy for solving problems (the code borrowed from Data Structures and Algorithms Quick Sort. This example presuppose M=1 so insertion sort phase is absent )
quicksort( void *a, int low, int high )
{
int pivot;
/* Termination condition! */
if ( high > low )
{
pivot = partition( a, low, high );
quicksort( a, low, pivot-1 );
quicksort( a, pivot+1, high );
}
}
|
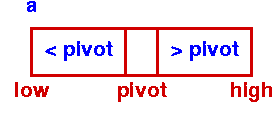 Initial Step - First Partition |
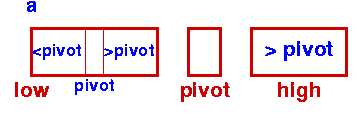 Sort Left Partition in the same way |
Partitioning array into part that contains elements less or equal then pivot and the part that contains element greater then pivot is an interesting problem in itself. Several such algorithms exists.
The most straightforward is keeping two pointers: one moving in from the left
and a second moving in from the right. They are moved towards the centre until the
left pointer finds an element greater than the pivot and the right one finds an
element less than the pivot. Then those two elements are swapped. Process repeated
until left and right index overlap. The pivot is then swapped into the slot to which
the right pointer points and the partition is complete. See
How do we Partition
void SWAP( int a[], int left, int right)
{
int t;
t=a[left];
a[left]=a[right];
a[right]=t;
}
int partition( int a[], int low, int high )
{
int left, right, pivot; /* indexes */
int pivot_item; /* value of pivot item */
pivot = low; /* naive method of selection of pivot used for simplicity*/
pivot_item=a[low];
SWAP(a,low,high); /* move pivot to position high to ensure loop termination*/
left = low;
right = high;
while (1) {
/* Find left element that is greater or equal to pivot*/
while( a[left] < pivot_item ) {left++;}
/* Find right element that is less pivot*/
while( left < right && a[right] >= pivot_item) {right++;}
/*swap them*/
if ( left >= right ) break;
SWAP(a,left,right);
}
/* right is final position for the pivot , swap pivot with the item in question*/
a[high] = a[right];
a[right] = pivot_item;
return right;
}
Note: above code checks that left does not exceed
the array bound because the pivot is moved to the last element of the array (a[high])
and comparison with pivot is preformed using condition a[left] < pivot_value
which always terminates the loop as soon as it hits the last element
(equal to pivot)Another one described in textbooks algorithms of partitioning is shorter, does not require additional test checking if left exceeds the array bound. In case of random data it slightly more efficient, But, unfortunately, it is more difficult to understand. The idea is that if pivot at the end occupies the position S then exactly S-1 items should be less or equal then pivot. So partitioning can be done by exchanging each found element that it less or equal then pivot with 1,2,3,...S-1 elements of the array correspondingly. Final order of elements here will be different then in previous partitioning algorithm and some elements can be swapped two or more time. In case of identical elements this algorithms does a lot of unnecessary work so in some cases it is less efficient them previous.
Here is one possible implementation (Quicksort - Wikipedia, Algorithms in nutshell, p 78):
int partition( void *a, int low, int high )
{
int left, right;
void *pivot_item;
pivot=low; /* naive method of selection of pivot is used for simplisity */
pivot_item=a[pivot];
SWAP(a,high,pivot); /* move pivot item to the end of array */
store=low; /* this is the index of the last exchanged element */
for (i=low; i<high; i++) {
if ( a[i] <= pivot_item ) {
SWAP(a,i,store);
store++;
}
} /*for*/
SWAP(a,store,high);
return store
}
At the end both partition algorithms split array into two parts:
There is a possibility to split array in three parts:
We will not discuss it here.
The next and critical part of the algorithm is the choice of pivot. There are three "mainstream" strategies for this operation:
The pivot is selected blindly: you can chose the first or the middle element of the current segment as a pivot. This is generally OK for random data but not so much for data with a lot of identical elements.
In certain cases (and very important cases) such a strategy leads to disaster. If the array to be sorted is already sorted or already reverse sorted, choice of the first element lead to the running time is O(n2), which is no better than Insertion sort! What happens in the worst case is that all the elements get partitioned to one side of the chosen pivot. For example, given an array (1, 2, 3, 4), the partition algorithm based on the first element chooses 1 as the pivot, then all the elements stay where they were, and no partitioning actually happens.
To overcome this problem two approaches were introduced: selection of pivot using median of three elements and random selection of pivot.
In this case we select the pivot out of three elements: first, last and middle). Results are much better then in case of naive selection, but still generally bad in approximately 20% of cases.
Typically median pivot helps to avoid significant percentage of so called "failed partitioning". We will call failed partitioning the partitioning that has asymmetry index abs((R-L)/(R+L)) more then 0.8. The latter means that the larger segment is at least nine time longer then the smaller. This number depends on the cutting length for insertion sort and for single digit cutting length is in the range 10-20% and in low teens cutting range it drops to 5-10%.
On realistic data (I used various time series including one for S&500 index since its inception) it looks like Quicksort "poison" itself: the shorter is the segment, the higher is probability of bad pivot selection. That is especially pronounced if the data contains considerable number of equal or very close to each other elements. That's why usage of insertion sort for small segments is so important and no reasonable Quicksort implementation can use "pure" partitioning.
But even with insertion sort I observed that almost 50% of partitioned segments are highly asymmetrical (have asymmetry index greater then 0.33, which means that the smaller segment is at least twice longer then the larger segment). In other words highly asymmetrical partitioning looks like a rule, not an exception.
Usage of insertion sort also has another positive effect: it cuts down the number of partitioning operations. It looks like low teens "cutting length" of segment for insertion sort works the best (Robert Sedgewick mentions range 5-15 in 2011 edition of his book; this edition was co-authored with Kevin Wayne) .
Here are the data on one of my S&P500 samples:
| No | Asymmetry index interval | Number of partitioning that fall into particular asymmetry index interval | Percentage of total number of partitionings | Cumulative |
| Cutting length for insertion sort is 5 elements | ||||
| 1 | 0 | 168 | 15.27% | 15.27% |
| 2 | 0-0.1 | 111 | 10.09% | 25.36% |
| 3 | 0.1-0.2 | 179 | 16.27% | 41.64% |
| 4 | 0.2-0.3 | 109 | 9.91% | 51.55% |
| 5 | 0.3-04 | 83 | 7.55% | 59.09% |
| 6 | 0.4-0.5 | 78 | 7.09% | 66.18% |
| 7 | 0.5-0.6 | 62 | 5.64% | 71.82% |
| 8 | 0.6-0.7 | 47 | 4.27% | 76.09% |
| 9 | 0.7-0.8 | 29 | 2.64% | 78.73% |
| 10 | 0.8-0.9 | 22 | 2.00% | 80.73% |
| 11 | 0.9-1 | 11 | 1.00% | 81.73% |
| 12 | 1 | 201 | 18.27% | 100.00% |
| Total partitionings | 1100 | |||
| Cutting length for insertion sort is 11 elements | ||||
| 1 | 0 | 62 | 10.30% | 10.30% |
| 2 | 0-0.1 | 113 | 18.77% | 29.07% |
| 3 | 0.1-0.2 | 93 | 15.45% | 44.52% |
| 4 | 0.2-0.3 | 69 | 11.46% | 55.98% |
| 5 | 0.3-04 | 65 | 10.80% | 66.78% |
| 6 | 0.4-0.5 | 56 | 9.30% | 76.08% |
| 7 | 0.5-0.6 | 48 | 7.97% | 84.05% |
| 8 | 0.6-0.7 | 38 | 6.31% | 90.37% |
| 9 | 0.7-0.8 | 19 | 3.16% | 93.52% |
| 10 | 0.8-0.9 | 11 | 1.83% | 95.35% |
| 11 | 0.9-1 | 6 | 1.00% | 96.35% |
| 12 | 1 | 22 | 3.65% | 100.00% |
| Total partitionings | 602 | |||
Optimal point for insertion sort is difficult to find, but a good guess is low to high teens:
Tresh- Compari- Parti-, Failed, Insertion sort % of part Part Insertion hold sons tionings partitionings invocations failures swaps swaps
100 102900 74 0 75 0% 3034 21565 50 96028 152 1 152 0.6% 3778 13077 25 97957 306 0 307 0 4626 6555 21 100082 347 4 344 1.1% 4804 5963 19 98680 390 10 381 2.5% 4853 5819 17 94239 411 5 407 1.2% 4949 5264 15 94045 472 13 460 2.7% 5210 4603 13 101321 544 20 525 3.6% 5357 3989 11 97475 602 21 582 3.4% 5585 3496 9 101680 753 48 706 6.3% 5837 3042 7 101952 898 75 824 8.3% 6180 2448 5 107073 1100 176 925 16% 6645 1729 3 110223 1516 662 855 43.6% 7364 1032
As one can see for this particular dataset, the number of comparisons has minimum at 15, The total number of swaps (partitioning swaps+ insertions sort swaps) increases with the increase of cutting threshold for insertion sort and has minimum at 5.
If we increase cutting threshold above 25 the number of comparisons increases non-significantly and for certain values can actually decrease, but the number of insertion swaps (performed by insertion sort) increases dramatically. From comparison of data for threshold 15 and 13 is clear that number of failed partitions matter and increases the total number of comparisons. It is also clear that the cost of comparison vs. the cost of element swap is the critical parameter.
Unfortunately the number of comparisons per se is not as essential on modern computers as the number of failed comparisons and in cases where failures dominated, the test generally should be negated and then and else branches swapped to increase the number of successful comparisons. For example, for cutting threshold 11 on this particular data set the number of successful comparisons would be 75503 and the number of failed comparisons 21972 so the algorithm is pretty good in utilizing predictive execution.
Unfortunately median pivot produces O(n2) running time on a list filled with identical items (see Tim Peters's discussion in the Python Cookbook or article Sorting In Anger.).
If you pick the pivot element at random index in an array of n keys, then approximately half of the time the selected pivot element will belong to the center half of the sorted array. Whenever the pivot element is from positions n=4 to 3n=4, the larger remaining subarray contains at most 3n=4 elements. Randomization is a general tool to improve algorithms with bad worst-case but good average-case complexity. The worst-case is still there, but the chances to get one are pretty slim.
There are two additional methods used for the optimization of Quicksort performance:
As an illustration of this idea, you can view this animation, which shows a partition algorithm in which items to be sorted are copied from the original array to a new one: items smaller than the pivot are placed to the left of the new array and items greater than the pivot are placed on the right. In the final step, the pivot is dropped into the remaining slot in the middle.
qsort CMU -- good explanation of partitioning
Quick Sort Umich
lecture13 Good lecture for U of Alberta
qsort (Prinston slides)
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
December 2005 | Cavendish Laboratory, Cambridge, Inference Group
We can give quicksort the entropy treatment too. Quicksort is wasteful because it persists in making experiments where the two possible outcomes are not equally likely. Roughly half of the time, quicksort is using a 'bad' pivot - 'bad' in the sense that the pivot is outside the interquartile range - and, once it has become clear that it's a bad pivot, every comparison made with that pivot yields an expected information content significantly less than 1 bit.
A simple hack that reduces quicksort's wastefulness is the 'median of three' modification of quicksort: rather than picking one pivot at random, three candidates are picked, and their median is chosen as the pivot. The probability of having a bad pivot is reduced by this hack. But we can do better than this. Let's go back to the beginning and analyse the information produced by quicksort.
When we pick a pivot element at random and compare another randomly selected element with it, the entropy of the outcome is clearly one bit. A perfect start. When we compare another element with the pivot, however, we instantly are making a poor comparison. If the first element came out `higher', the second is more likely to be higher too. Indeed the probability that the second is higher is roughly 2/3. (A nice Bayes' theorem illustration, I must remember that one! For N=3, N=4 objects 2/3 is exactly right; perhaps it is exact for all N.) The entropy of (1/3,2/3) is 0.918 bits, so the inefficiency of this first comparison is not awful - just 8%. On entropy grounds, we should go and compare two other elements with each other at our second comparison. But let's continue using Quicksort. If the first two elements both turn out higher than the pivot, the next comparison has a probability of 3/4 of coming out `higher' too. (Entropy: 0.811 bits.) This situation will arise more than half the time.
Table 1 shows, after 5 elements have been compared with the pivot element, what the possible states are, and what the entropy of the next comparison in quicksort would be, if we went ahead and did it. There is a one-third probability that the state is (0,5) or (5,0) (meaning all comparisons with the pivot have gone the same way); in these states, the entropy of the next comparison is 0.59.
State Probability of this state Probability that next element will go left Entropy left right 0 5 1/6 1/7 0.59167 1 4 1/6 2/7 0.86312 2 3 1/6 3/7 0.98523 3 2 1/6 4/7 0.98523 4 1 1/6 5/7 0.86312 5 0 1/6 6/7 0.59167 Table 1
Table 2 shows the mean entropy of the outcome at each iteration of quicksort.
Iteration of quicksort Expected entropy at this step Minimum entropy at this step 0 1 1 1 0.918296 0.918296 2 0.874185 0.811278 3 0.846439 0.721928 4 0.827327 0.650022 5 0.81334 0.591673 6 0.80265 0.543564 7 0.794209 0.503258 8 0.78737 0.468996 9 0.781715 0.439497 10 0.77696 0.413817 Table 2 We can use calculations like these to make rational decisions when running quicksort. For example, we could give ourselves the choice between continuing using the current pivot, and selecting a new pivot from among the elements that have been compared with the current pivot (in a somewhat costly manner) and continuing with the new pivot. The 'median of three' starting procedure can be described like this: we always start by comparing two elements with the pivot, as in standard quicksort. If we reach the state (1,1), which has probability of 1/3 of happening, then we continue using the current pivot; if we reach the state (0,2) or (2,0), we decide this is a bad pivot and discard it. We select a new pivot from among the other two by comparing them and choosing the one that is the median of all 3. This switch of pivot has an extra cost of one comparison, and is expected to yield beneficial returns in the form of more bits per comparison (to put it one way) or a more balanced tree (to put it another way).
We can put the 'median of 3' method on an objective footing using information theory, and we can generalize it too.
Imagine that we have compared (M-1) of N items with a randomly selected pivot, and have reached the state (m1,m2) (i.e., m1 to the left and m2 to thte right). We now have a choice to continue using the same pivot, which gives us an expected return of H_2(p) at the next comparison, where p = (m1+1)/(m1+m2+2), or we could invest in a median-finding algorithm, finding the median of the M items handled thus far. (Median can be found with an expected cost proportional to M; for example, quickselect's cost is about 4M.) We can evaluate the expected return-to-cost ratio of these two alternatives. If we decide to make (N-M) more comparisons with the pivot the expected return is roughly R = (N-M)H_2(p) bits. [Not exactly right; need to do the integrals to find the exact answer.] If we switch to a new pivot then proceed with quicksort, discarding the information generated while finding the new pivot at subsequent iterations (which is wasteful of course - and points us to a new algorithm, in which we first sort a subset of elements in order to select multiple pivots), the cost is roughly (N-M)+4(M-1) comparisons and the expected return is roughly R' = (N-M)H_2(p') bits, where p' is the new pivot's rank.
If we approximate R' \simeq N-M then finding the new pivot has the better return-to-cost ratio if
(N-M)/ ( (N-M)+4(M-1) ) > H_2(p)
i.e. 1/ ( 1+4(M-1)/(N-M) ) > H_2(p)As we would expect, if the number of points to be compared with the pivot, N-M, is large, then we feel more urge to criticise the current pivot.
Further modifying quicksort, we can plan ahead: it's almost certainly a good idea to perfectly sort a M randomly selected points and find their median, where M is roughly sqrt(N/log(N)), and use that fairly accurate median as the pivot for the first iteration.
Summary: 'median-of-3' is a good idea, but even better (for all N greater than 70 or so) is 'median-of-sqrt(N/log(N))'. If you retain the sorted subset from iteration to iteration, you'll end up with something rather like a Self-balancing binary search tree.
What is the time complexity of quicksort? The answer that first pops up in my head is O(N logN). That answer is only partly right: the worst case is in fact O(N2). However, since very few inputs take anywhere that long, a reasonable quicksort implementation will almost never encounter the quadratic case in real life.I came across a very cool paper that describes how to easily defeat just about any quicksort implementation. The paper describes a simple comparer that decides ordering of elements lazily as the sort executes, and arranges the order so that the sort takes quadratic time. This works even if the quicksort is randomized! Furthermore, if the quicksort is deterministic (not randomized), this algorithm also reveals the input which reliably triggers quadratic behavior for this particular quicksort implementation.
qsort CMU
Quick Sort Umich
lecture13 Good lecture for U of Alberta
qsort (Prinston slides)
Recommended books
- Cormen, Leiserson, Rivest. Introduction to algorithms. (Theory)
- Aho, Ullman, Hopcroft. Data Structures and Algorithms. (Theory)
- Robert Lafore. Data Structures and Algorithms in Java. (Practice)
- Mark Allen Weiss. Data Structures and Problem Solving Using C++. (Practice)
Visualizers
Three Divide and Conquer Sorting Algorithms
Today we'll finish heapsort, and describe both mergesort and quicksort. Why do we need multiple sorting algorithms? Different methods work better in different applications.
- Heapsort uses close to the right number of comparisons but needs to move data around quite a bit. It can be done in a way that uses very little extra memory. It's probably good when memory is tight, and you are sorting many small items that come stored in an array.
- Merge sort is good for data that's too big to have in memory at once, because its pattern of storage access is very regular. It also uses even fewer comparisons than heapsort, and is especially suited for data stored as linked lists.
- Quicksort also uses few comparisons (somewhat more than the other two). Like heapsort it can sort "in place" by moving data in an array.
Mar 3, 2016
The main aim of this study is to implement the QuickSort algorithm using the Open MPI library and therefore compare the sequential with the parallel implementation.
1 Contents
- 1. Objective
- 2 Related Works
- 3 Theory of Experiment
- 4 Algorithm and Implementation of QuickSort USING MPI
- 5 Experimental Setup and Results
- 6 Problems
- 7 Conclusion
- 8 Future Works
- 9 References
1. Objective
Sorting is used in human activities and devices like personal computers, smart phones, and it continues to play a crucial role in the development of recent technologies. The QuickSort algorithm has been known as one of the fastest and most efficient sorting algorithm. It was invented by C.A.R Hoare in 1961and is using the divide-and-conquer strategy for solving problems [3]. Its partitioning aspects make QuickSort amenable to parallelization using task parallelism. MPI is a message passing interface library allowing parallel computing by sending codes to multiple processors, and can therefore be easily used on most multi-core computers available today. The main aim of this study is to implement the QuickSort algorithm using the Open MPI library and therefore compare the sequential with the parallel implementation. The entire study will be divided in many sections: related works, theory of experiment, algorithm and implementation of Quicksort using open MPI, the experimental setup and results, problems followed by the conclusion and future works.
2. Related Works
Many studies have been done on parallel implementation of Quicksort algorithm using either Posix threads (Pthreads), OpenMP or message passing interface (OpenMPI). For instance the time profit obtained by the parallelization of Quicksort Algorithm using OpenMP is presented in [9]. Here authors have taken advantage of the rich library offers by OpenMP and its simplicity to considerably reduce the execution time of Quicksort in parallel compared to its sequential version. In this study the unpredictability of the execution time in parallel version appears to be the main problem. Another similar experiment [7] on parallel Quicksort is carried out using multiprocessors on clusters by OpenMPI and Pthreads highlighting different benchmarking and optimization techniques. The same implementation of the algorithm done in [7] is used in [8] this time focusing merely on performance analysis. In short [7, 8] present almost a common implementation of parallel Quicksort and MPI, after the sorting their respective chunks of data, a tree based merge is used for the collection of different chunks in order to get the final sorted data. However in our study a completely different approach has been taken. In our implementation, we have simply used the MPI collective routine and an additional sorting step to replace the merge functionality. Initially for each version of QuickSort (iterative and recursive) algorithm we have made a sequential implementation using the C programming language. Then we have ported the two sequential implementations to MPI in order to run them in parallel.
3. Theory of Experiment
Similar to mergesort, QuickSort uses a divide-and-conquer strategy and is one of the fastest sorting algorithms; it can be implemented in a recursive or iterative fashion. The divide and conquer is a general algorithm design paradigm and key steps of this strategy can be summarized as follows:
- Divide
:divide the input data set S into disjoint subsets S1, S2, S3…Sk.- Recursion
:solve the sub-problems associated with S1, S2, S3…Sk- Conquer
:combine the solutions for S1, S2, S3…Sk. into a solution for S.- Base case
:the base case for the recursion is generally sub-problems of size 0 or 1.Many studies [2] have revealed that in order to sort N items; it will take the QuickSort an average running time of O(NlogN). The worst-case running time for QuickSort will occur when the pivot is a unique minimum or maximum element, and as stated in [2] the worst-case running time for QuickSort on N items is O(N2). These different running times can be influenced by the inputs distribution (uniform, sorted or semi-sorted, unsorted, duplicates) and the choice of the pivot element. Here is a simple Pseudocode of the QuickSort algorithm adapted from Wikipedia [1].
As shown in the above Pseudocode, the following is the basic working mechanism of Quicksort:
- Choose any element of the array to be the pivot
- Divide all other elements (except the pivot) into two partitions
- All elements less than the pivot must be in the first partition
- All elements greater than the pivot must be in the second partition
- Use recursion to sort both partitions
- Join the first sorted partition, the pivot and the second partition
- The output is a sorted array.
We have made use of Open MPI as the backbone library for parallelizing the QuickSort algorithm. In fact learning message passing interface (MPI) allows us to strengthen our fundamentals knowledge on parallel programming, given that MPI is lower level than equivalent libraries (OpenMP). As simple as its name means, the basic idea behind MPI is that messages can be passed or exchanged among different processes in order to perform a given task. An illustration can be a communication and coordination by a master process which split a huge task into chunks and share them to its slave processes. Open MPI is developed and maintained by a consortium of academic, research and industry partners; it combines the expertise, technologies and resources all across the high performance computing community [11]. As elaborated in [4], MPI has two types of communication routines: point-to-point communication routines and collective communication routines. Collective routines as explained in the implementation section have been used in this study.
4 Algorithm and Implementation of QuickSort with MPI
A detailed explanation of how we have ported the QuickSort algorithm to MPI is given in the following sections:
4.1 Proposed Algorithm
In general the overall algorithm used here to perform QuickSort with MPI works as followed:
- Start and initialize MPI.
- Under the root process
MASTER,get inputs:
- Read the list of numbers
Lfrom an input file.- Initialize the main array
globaldatawithL.- Start the timer.
- Divide the input size
SIZEby the number of participating processesnpesto get each chunk sizelocalsize.- Distribute
globaldataproportionally to all processes:
- From
MASTERscatterglobaldatato all processes.- Each process receives in a sub data
localdata.- Each process locally sorts its
localdataof sizelocalsize.- Master gathers all sorted
localdataby other processes inglobaldata.
- Gather each sorted
localdata.- Free
localdata.- Under MASTER perform a final sort of
globaldata.
- Final sort of
globaldata.- Stop the timer.
- Write the output to file.
- Sequentially check that
globaldatais properly and correctly sorted.- Free
globaldata.- Finalize MPI.
4.2 Implementation
In order to implement the above algorithm using C programming, we have made use of a few MPI collective routine operations. Therefore after initializing MPI with
MPI_Init,the size and rank are obtained respectively usingMPI_Comm_sizeandMPI_Comm_rank. The beginning wall time is received fromMPI_Wtimeand the array containing inputs is distributed proportionally to the size to all participating processes withMPI_Scatterby the root process which collect them again after they are sorted usingMPI_Gather.Finally the ending wall time is retrieved again fromMPI_Wtimeand the MPI terminate callingMPI_Finalize.In the following part, each section of our proposed algorithm is illustrated with a code snippet taken from the implementation source code.
- Start and initialize MPI.
- Under the root process
MASTER, get inputs:
Starting the timer.
- Divide the input size
SIZEby the number of participating processesnpesto get each chunk sizelocalsize.
- Distribute
globaldataproportionally to all processes:
- Each process locally sorts its
localdataof sizelocalsize.
Mastergathers all sortedlocaldataby other processes inglobaldata.
- Under
MASTERperform a final sort ofglobaldata.
Stop the timer
Write information to in the output file
Checking that the final globaldata array is properly sorted.
Free the allocated memory
- Finalize MPI.
The two versions of QuickSort algorithm have been implemented; however even though they have almost the same implementation using similar functions, the recursion in the recursive part has been replaced by a stack in order to make it iterative. Their function signatures are presented in the following part:
- Recursive QuickSort
- Iterative QuickSort
The input file necessary to run this program can be generated using an input generator where we specify the size and the filename (input_generator.c), then compile and run with the following instructions:
Quicksort - Wikipedia, the free encyclopedia
Quicksort -- from Wolfram MathWorld
Algorithm Implementation-Sorting-Quicksort - Wikibooks, open books for an open world -- multiple implementations that should be taken with a grain of salt.
[PDF] QUICKSORT IS OPTIMAL Robert Sedgewick Jon the quicksort cheerleader paper. Very questionable argumentation. Optimal on what? On ideal random data ? See A Killer Adversary for Quicksort
Definition: A variant of quicksort which attempts to choose a pivot likely to represent the middle of the values to be sorted.
See also median.
Note: This is one of several attempts to prevent bad worst cases in quicksort by choosing the initial pivot.
Author: ASK
Analysis of Quicksort (6) Michael L. Littman; September 15th, 1998
NIST quicksort ;www.nist.gov/dads/HTML/quicksort.html
Science Fair Projects - Quicksort
Quicksort is a well-known sorting algorithm developed by C. A. R. Hoare that, on average, needs Θ(n log n) comparisons to sort n items, while requiring Θ(n2) comparisons in the worst-case.Quicksort's inner loop is such that it is usually easy to implement very efficiently on most computer architectures, which makes it significantly faster in practice than other Θ(n log n) algorithms that can sort in place or nearly so in the average case (recursively-implemented quicksort is not, as is sometimes regarded, an in-place algorithm, requiring Θ(log n) on average, and Θ(n) in the worst case, of stack space for recursion.)
Quicksort. Quicksort is a sorting algorithm that, on average, needs O(n log(n))
comparisons to sort n items. ... Quicksort was developed by CAR Hoare
[PDF] Microsoft PowerPoint - QuickSort
Quicksort Quicksort is one of the fastest and simplest sorting algorithms [Hoare]. It works recursively by a divide-and-conquer strategy
The Code Project - A QuickSort Algorithm With Customizable Swapping - C# Programming
Interactive Quicksort. Press "Start" to restart the algorithm. When you press the
"Start" button the algorithm will sort the numbers in the textfields. ...
Quicksort - C++, Java, Algorithm and Data Structure Tutorials by Denis Kulagin
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: March 12, 2019












