|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| See Also | Recommended Books | Recommended Links | TAOCP Volume3 | Assembler is not for Dummies | |
| Animations | Testing Sorting Algorithms | The Art of Debugging | C language | Flowcharts | |
| Simple | Insertion sort | Selection sort | Bubblesort | ||
| Insertion based | Insertion sort | Shellsort | |||
| Merge based | Mergesort | Natural two way merge | |||
| Sorting by selection | Selection sort | Heapsort | |||
| Sorting by exchanging | Bubblesort | Shaker sort (bidirectional bubblesort) |
Quicksort | ||
| Distribution sorts | Bucket sort | Radix sort | |||
| Sorting algorithms style | Unix sort | Flashsort | Humor | Etc |
|
|
This page was partially created from lecture notes of Professor Nikolai Bezroukov.
This is a very special page: here students can find several references and actual implementation for Bubblesort :-). Actually bubblesort is a rather weak sorting algorithm for arrays. For some strange reason it still dominates introductory courses. Often it is implemented incorrectly, despite being one of the simplest sorting algorithms in existence. Still while inferior to, say, insertion sort, in most cases, it is not that bad on lists and perfect for already sorted arrays (a rather frequent practical case ;-). Or "almost sorted" arrays -- the array with a small percentage of permutations. Which are often the dominant case we dealing with. Becuase sometimes instead of merge programmer just write additional data to the end of the already sorted array and the sort it again. While it is clearly a perversion, it is pretty common technique. An important point is that it is very often is implemented incorrectly.
You can guess that the number of incorrect implementations grows with the complexity of the algorithms (BTW few people, including many instructors, are able to write correct binary search algorism, if asked and have no references, so algorithms are generally difficult areas with which saying that "to err is human" is especially applicable).
Actually one need to read volume 3 of Knuth to appreciate the beauty and complexity of some advanced sorting algorithms. Please note that sorting algorithms published in many textbooks are more often then not implemented with errors. Even insertion sort presents a serious challenge to many book authors ;-). Sometimes the author does not know the programming language he/she uses well, sometimes details of the algorithm are implemented incorrectly. And it is not that easy to debug them. In this sense Knuth remains "the reference", one of the few books where the author took a great effort to debug each and every algorithm he presented.
But the most dangerous case is when the instructor emphasizes object oriented programming while describing sorting. That applies to book authors too. It's better to get a second book in such case, as typically those guys try to obscure the subject making it more complex (and less interesting) than it should be. Of course, as a student you have no choice and need to pass the exam, but be very wary of this trap of mixing apples and oranges.
You might fail to understand the course material just because the instructor is too preoccupied with OO machinery instead of algorithms. So while you may feel that you are incapable to master the subject, in reality that simply means that the instructor is an overcomplexity junky, nothing more nothing less ;-).
In any case OO obscures the elegance of sorting algorithms to such an extent that most students hate the subject for the rest of their life. If this is the case, that only means that you are normal.
Notes:
In general different algorithms are optimal for N<20; 20<N<100; 100<N<1M; and N>1M records. For N <20 insertion sort is probably the fastest. So it makes sense to perform some intelligence before starting actual sorting and then invoke the algorithms that is the most suitable for particular data.
One important special case is then sorted data are iether sorted in reverse order or have very few permutations.
Classic treatise on sorting algorithms remains Volume 3 of TAoCP by Donald Knuth. The part of the book in which sorting algorithms are explained is very short (the volume also covers searching and several other subjects). Just the first 180 pages. Also when Knuth start writing the third volume he was exhausted and that shows. The quality of his writing is definitely lower than for the first volume.
Some explanations are sketchy and it is clear that he could benefit from more experimentation. He also pays excessive attention to establishing exact formula for the running time of sorting of random data. I think "O notation" (see below) is enough for this case.
Worst cases running time is a really interesting area for sorting algorithms about which Knuth is very brief. I think for algorithms which compare keys it is impossible to do better then O(n*log(n)) in worst case (both Heapsort and Mergesort do achieve that bound). Knowing the class of input data for which given algorithm, for example Quicksort produces worse case results is can be important in many practical cases. For example, if the algorithm degrades significantly in worst case it is unsuitable for real time systems, no matter how great is its running time on random data.
Also hardware changed dramatically since the volume 3 of TAOCP was written. Now most CPU have multiple cores and thus can sort large arrays in parallel (one core per chunk which on 16 core server allows to sort 16 chunks in parallel) and then merge sorted chunks.
SSD created an opportunity for merging of sorted fragment with the speed comparable with the merging in memory. That means that it might be better to split a huge file into several chunks, soft them on parallel and then merge that try to sort this monster in memory, even if there is enough RAM (modern servers can have several terabytes of RAM).
Still TAoCP vol. 3 is a valuable book. You can buy the first edition for 3-5 dollars (and they are still as good as later editions for teaching purposes as Knuth did a very good job in the first edition and never improved the presentation of the topics covered in later editions -- changes are mostly small corrections and typographic niceties).
Knuth is now over 80 and most probably the edition that we have is that last he will even produce. Most algorithms now are also available in MIXX instead of original MIX and that helps, because MIX is so remote from the modern computer architecture that it hurts. Still translation from MIX to your favorite language is a very important part of reading the Volume 3 and can't be skipped.
Please note that all flowcharts in the book are a horrible mess -- shame on Knuth (but more of Addison Wesley, who should know better). Both failed to do proper job, this destroying Knuth's own aesthetics of book writing. When I see some of the provided flowcharts, I have a mixed feeling, something between laugh and disgust. But again we need to understand that the third volume was rushed by-semi-exhausted Knuth and that shows. Still Knuth emerges in this volume as a scientist who is really interested in his field of study, which I can't tell about several other books on the subject. This is a virtue for which we can forgive a lot of shortcomings.
The other problem with the third volume is some algorithms are presented in a very sketchy fashion. This is partially because Knuth was really pressed to finish it, but also because the foundation of the book was not Knuth own research, but lecture notes of Professor Robert W. Floyd, one of the few winners of ACM Turing prize, the top 50 scientists and technologists of the USA early computer science explosion.
But despite brilliance of Professor Floyd (who also make important contribution to the compiler algorithms) at time he gave his lectures the field still quickly developed and this fact is reflected in the unevenness of his lecture notes which migrated to the book content.
Some algorithms are well covered but other important not so well, because their value was still unclear at the most of writing. That's why the third volume can be viewed as the most outdated volume out of three, despite the fact that it was published last. Nevertheless it remains classic because Knuth is Knuth, and his touch on the subject can't be replicated easily.
As any classic, it is quite difficult to read (examples are in MIX assembler; and growing on ancient IBM 650 Knuth missed the value of System/360 instruction set). Still like classic should, it produces insights that you never get reading regular textbooks. The most valuable are probably not the content, Knuth style and exercises. Most of the content of volume 3 can now be found in other books, although in somewhat emasculated fashion.
Again I would like to warn you that the main disaster in courses "Data structures and algorithms" happens when they try to mix applies with oranges, poisoning sorting algorithms by injecting into the course pretty much unrelated subject -- OO. And it is students in this case who suffer, not the instructor ;-)
|
|
Among simple sorting algorithms, the insertion sort seems to be the best small sets. It is stable and works perfectly on "almost sorted" arrays if you guessed the direction of sorting right. Those "almost sorted" data arrays are probably the most important class of input data for sorting algorithms (and they were undeservingly ignored by Knuth). Generally guessing the structure of array that you are sorting right is the key to high speed sorting. Otherwise you need to rely on worst case scenarios which often is horribly slow.
Selection sort, while not bad, does not takes advantage of the preexisting sorting order and is not stable. At the same time it moves "dissident" elements by larger distances then insertion sort, so the total number of moves might well be less. But a move typically cost about the same as unsuccessful comparison (on modern computer with predictive execution unsuccessful comparison costs 10 or more times then when comparison that does not change order of execution (typically successful comparison). So it is total number of comparisons plus total number of moves that counts. That also suggest that on modern computers algorithms that does not use comparisons of keys might have an edge.
Despite this fact it is still make sense to judge the quality of sorting algorithms by just the number of comparisons, despite the fact that algorithms which do not use comparisons at all have significant advantages on modern computers. But sun of the total number of comparisons and moves is even a b metric. But not all comparisons are created equal -- what really matter are unsuccessful comparisons, not so much successful one. Each unsuccessful comparison results in a jump in compiled code which forces the flush of the instruction pipeline.
The second important fact is the size of the set. There is no and can't be a sorting algorithms that is equally efficient of small sets and on large sets. For small sets "overhead" of the algorithms itself is an important factor, so the simpler algorithm is the better it performs on small sets. So no complex algorithms probably can beat simpler sorting algorithms on sets up to, say, 21 element.
On larger sets several more complex algorithms such as radixsort (which does not used comparisons), shellsort, mergesort, heapsort, and even quite fragile, but still fashionable quicksort are much faster. But for some algorithms like quick sort that is tricky effect called self-poisoning -- on larger sets higher number of subsets degenerate into worst case scenario. Mergesort does not has this defect. That's why mergesort is now used by several scripting languages as internal sorting algorithm instead of Quicksort.
A least significant digit (LSD) radix sort recently has resurfaced as an alternative to other high performance comparison-based sorting algorithms for integer keys and short strings because unlike Heapsort and Mergesort it does not use comparisons and can utilize modern CPUs much better then traditional comparison based algorithms.
Anyway, IMHO if an instructor uses bubblesort as an example you should be slightly vary ;-). The same is true if Quicksort is over-emphasized in the course as all singing-all dancing solution for sorting large sets..
Most often you not need to sort not the set of keys, but a set of records, each of which contains specific key as a part of the record. Only the key is used for comparison during the sorting If record is long , then in most cases it does not make much sense to sort records "in place", especially if you need to write the result to the disk. You better create a separate array with keys and indexes (or references) of the records and sort it. For example, any implementation of Unix sort utility that involves moving of the whole records for cases when the length of the record is three or more time longer then the key is suboptimal, as the result always is written tot he disk
Even in cases of in-memory sort, if records are long in many cases it is better to copy keys and index (or reference) them to the record in a separate array, This array has records in which the length of the record is typically less then two times the length of the key, so they can be sorted "in place" very efficiently. Speedup can more then ten or even 100 times, if records are sufficiently longer then the key (for example, if the key is IP address and records are HTTP proxy logs)
Modern computers have enough memory to make those methods that use additional storage to be preferable to "in place" sorting of the whole records, as moving long records after comparison of keys in such cases take much more time then the comparison of the keys. If this is necessary, then sorting algorithms which minimize the number of moves have the edge over all others. I would say that if record is 3 of more times longer then the key, sorting array of keys with indexes/references should be considered.
This method also allow faster insertion of new records into the array as you can already written them at the end of the existing array and insert only into "key-Index" array.
There are also some other less evident advantages of this approach. For example, it allows sorting arrays consisting of records of unequal length.
Generally preferences for "in-place" sorting which are typical for books like Knuth Vol 3 now need to be reconsidered, as often sorted array can be reconstructed in the new space and the memory of the initial array can be reclaimed later via garbage collection mechanisms which exist in most modern languages (actually all scripting languages, plus Java and Go).
As index to record is almost always can be represented by 4 bytes, the question arise if the key can also be represented by 4 bytes which make the whole sorting much faster as 8 bytes is a double word on modern machines and be moved with a single instruction.
for example in case of dates you can always pre-convert then into integers. You do not need to convert them back you can just store the original jkey with the rest of the record. Often there are some possibilities to compress key in 4 bytes for other types of the keys too. You can also perform partial sort by the first 5 bytes of the key using, say Shell sort, and only then "full sort" relying on the fact that now unsorted records are more adjacent to each other.
If you can't convert the key into4 bytes, may be you can convert then int 8, 12, 16, or 20 bytes. In all case that considably speeds the search. for example comparison of two 16 byte keys can be done using two instructions.
Another opportunity aeises with sort methods which do not rely of comparison of keys.
One popular way to classify sorting algorithms is by the number of comparison made during the sorting of the random array ("big O" notation which we mentioned above). Here is can distinguish between tree major classes of sorting algorithms:
The second important criteria is the complexity of algorithms. We can classify sorting algorithms as simple and complex with simple algorithms beating complex of small arrays (say up to 21-25 elements).
Another important classification is based on the internal structure of the algorithm:
Number of comparison, type and the complexity of the algorithms are not the only way to classify sorting algorithms. There are many others. We can also classify sorting algorithms by several other criteria such as:
Computational complexity (worst, average and best number of comparisons for several typical test cases, see below) in terms of the size of the list (n). Typically, good average number of comparisons is O(n log n) and bad is O(n2). Please note that O matters. Even if both algorithms belong to O(n log n) class, algorithm for which O=1 is 100 times faster then algorithm for which O=100. For small sets (say less then 100 elements) the value of O can be decisive and outweigh number of comparison metric. That's why insertion sort is considered to be optimal for small sets despite that face that it is O(n2) algorithms.
Another problem with O notation is that this asymptotic analysis does not tell about algorithms behavior on small lists, or worst case behavior. This is actually one of the major drawback of Knuth book in which he was carried too much by the attempt to establish theoretical bounds on algorithms, often sliding into what is called "mathiness" . Worst case behavior is probably tremendously more important then average.
|
In sorting algorithms the worst case behavior is more important then average. |
For example "plain-vanilla" Quicksort requires O(n2) comparisons in case of already sorted in the opposite direction or almost sorted array.
I would like to stress that sorting of almost completely sorted array is a very important in practice case as in many case sorting is used as "incompetent implementation of the merging": instead of merging two sets the second set concatenated to the sorted set and then the whole array is resorted. If you get statistic of usage of Unix sort in some large datacenter you will be see that a lot of sorting used for processing huge log files and then resorting them for additional key. For example the pipeline
gzip -dc $1.gz | grep '" 200' | cut -d '"' -f 2 | cut -d '/' -f 3 | \
'[:upper:]' '[:lower:]' | sort | uniq -c | sort -r > most_frequent
can be applied to 1GB or larger file (amount of record for a large Web site) and this script can be processed daily.
Sort algorithms which only use generic key comparison operation always need at least O(n log n) comparisons on average; while sort algorithms which exploit the structure of the key space cannot sort faster than O(n log k) where k is the size of the keyspace. So if key space is much less then N (a lot of records with identical keys), no comparison algorithms is competitive with radix type sorting. For example if you sort student grades there are only a few valid keys in what can be quite large array.
Please note that the number of comparison is just convenient theoretical metric. In reality both moves and comparisons matter, and failed comparisons matter more then successful due to specific of modern CPUs;
Also on short keys the cost of move is comparable to the cost of successful comparison (the same is true if pointers are used).
Size of the CPU cache is another important factor and algorithms that can be optimized for this size (inner loop and data on which it operated most of the time fits in the cache) will be much faster.
Stability is the way sorting algorithms behave if the array to be sorted contain multiple identical keys. Stable sorting algorithms maintain the relative order of records with equal keys.
If all keys are different then this distinction does not make any sense. But if there are equal keys, then a sorting algorithm is stable if whenever there are two records R and S with the same key and with R appearing before S in the original list, R will appear before S in the sorted list.
Stability is a valuable property of sorting algorithms as in many cases the order of identical keys in the sorting array should be preserved.
A very important way to classify sorting algorithms is by the differences between worst cases behaviors and "average" behaviour
For example, Quicksort is efficient only on the average, and its worst case is n2 , while Heapsort has an interesting property that the worst case is not much different from the an average case.
Generalizing we can talk about the behavior of the particular sorting algorithms on practically important data sets. Among them:
The latter is often is created as a perverted way of inserting one or two records into a large data set: instead of merging them they are added to the bottom and the whole dataset is sorted. Those has tremendous practical implications which are often not addressed or addressed incorrectly in textbooks that devote some pages to sorting.
Memory usage is an important criteria by which we can classify sorting algorithms. But it was more important in the past then now. Traditionally the most attention in studying sorting algorithms is devoted to a large class of algorithms that are called "in-place" sorting algorithms. They do not require additional space to perform the sorting. But there is no free lunch and they are generally slower than algorithms that use additional memory: additional memory can be used for mapping of keyspace which raises the efficiency of sorting. Also most fast stable algorithms use additional memory.
This "excessive" attention to "in-place" sorting now is a somewhat questionable approach. Modern computers have tremendous amount of RAM in comparison with ancient computers (which means computers produced before 1980). So usage of some additional memory by sorting algorithms is no longer a deficiency like it were in good old days of computers with just 64KB (the first IBM/360 mainframe), or with 1 MB of RAM ( Initial IBM PC; note this is a megabyte, not a gigabyte) of memory. With smart phones often having 4GB of RAM or more using additional space during sorting now is at least less a deficiency. And servers now often have more 128GB of memory, and sometimes as much as 1TB.
Please note that smartphone which has 2 GB of RAM has 2000 more RAM then an ancient IBM PC XP with 1 MB of RAM. With the current 8-16GB typical memory size on laptops and 64GB typical memory size on the servers as well as virtual memory implemented in all major OSes, the old emphasis on algorithms that does not require additional memory should probably be reconsidered.
That means that algorithms that require log2N or even N of additional space are now more or less acceptable. Please note that sorting of arrays up to 1TB is now possible to be performed completely in RAM.
This of course such a development was impossible to predict in early 70th when Knuth Vol 3 of TAOCP was written (it was published in 1973). Robert Floyd lectures notes on sorting, on which Knuth third volume was partially based, were written even earlier.
Speedup that can be achieved by using of a small amount of additional memory is considerable and it is stupid to ignore it. Moreover even for classic in-place algorithms you can always use pointers to speed up moving records. for long records this additional space proportional to N actually speed up moved dramatically and just due to this such an implementation will outcompete other algorithms. In other words when sorting records not to use pointers in modern machines in any case when the record of the sorting array is larger then 64 bit is not a good strategy. In real life sorting records usually are size several times bigger then the size of a pointers (4 bytes in 32 bit CPUs, 8 bytes on 64 bit). That means that, essentially, study of sorting algorithms on just integer arrays is a much more realistic abstraction, then it appear from the first site.
In modern computer multi-level memory is used with fast CPU-based case having the size of few megabytes (let's say 4-6MB for expensive multicore CPUs) . Cache-aware versions of the sort algorithms, in which operations have been specifically tuned to minimize the movement of pages in and out cache, can be dramatically quicker. One example is the tiled merge sort algorithm which stops partitioning sub arrays when subarrays of size S are reached, where S is the number of data items fitting into a single page in memory. Each of these subarrays is sorted with an in-place sorting algorithm, to discourage memory swaps, and normal merge sort is then completed in the standard recursive fashion. This algorithm has demonstrated better performance on modern servers that have CPU with substantial amount of cache. (LaMarca & Ladner 1997)
Modern CPUs designs try to minimize wait states of CPU that are inevitable due to the fact that it is connected to much slower (often 3 or more times) memory using a variety of techniques such as CPU caches, instruction pipelines, instruction prefetch, branch prediction. For example, the number of instruction pipeline (see also Classic RISC pipeline - Wikipedia) flushes (misses) on typical data greatly influence the speed of algorithm execution. Modern CPU typically use branch prediction (for example The Intel Core i7 has two branch target buffers and possibly two or more branch predictors). If branch guessed incorrectly penalty is significant and proportional to the number of stages in the pipeline. So one possible optimization of code strategy for modern CPUs is reordering branches, so that higher probability code was located after the branch instruction. This is a difficult optimization that requires instrumentation of algorithms and its profiling, gathering set of statistics about branching behaviors based on relevant data samples as well as some compiler pragma to implement it. In any case this is important factor for modern CPUs which have 7, 10 and even 20 stages pipelines (like in the Intel Pentium 4) and were cost of a pipeline miss can cost as much as three or fours instructions executed sequentially.
Among non-stable algorithms heapsort and Shellsort are probably the most underappreciated (with mergesort close to them), and quicksort is one of the most overhyped. Please note the quicksort is a fragile algorithm that is not that good in using predictive execution of instructions in pipeline (typical feature of modern CPUs). There are practically valuable sequences ("near sorted" data sets) in which for example shellsort is twice faster then quicksort (see examples below).
It is fragile because the choice of pivot is equal to guessing an important property of the data to be sorted (and if it went wrong the performance can be close to quadratic). There is also some experimental evidence that on very large sets Quicksort runs into "suboptimal partitioning" on a regular basis, so it becomes a feature, not a bug. It does not work well on already sorted or "almost sorted" (with a couple or permutations) data sorted in a reverse order, or worse have "chainsaw like" order. It does not work well on data that contain a lot of identical keys. Those are important cases that are frequent in real world usage of sorting (for example when you need to sort proxy logs by IP). Again I would like to stress that one will be surprised to find what percentage of sorting is performed on "almost" sorted datasets (datasets with less then 10% of permutations although not necessary in correct order, for example ascending when you need descending, or vice versa) is probably ten time higher that on "almost random" datasets.
For those (and not only for those ;-) reasons you need to be skeptical about "quicksort lobby" with Robert Sedgewick (at least in the past) as the main cheerleader. Quicksort is a really elegant algorithm invented by Hoare in Moscow in 1961, but in real life other qualities then elegance and speed of random data are more valuable ;-).
On important practical case of "semi-sorted" and "almost reverse sorted" data quicksort is far from being optimal and often demonstrates dismal performance. You need to do some experiments to see how horrible quicksort can be in case of already sorted data (simple variants exhibit quadratic behavior, the fact that is not mentioned in many textbooks on the subject) and how good shellsort is ;-).
And on typical corporate data sets including log records heapsort usually beats quicksort because performance of quicksort too much depends of the choice of pivot and series of bad choices of pivot increase time considerably. Each time the pivot element is close to minimum (or maximum) the performance of this stage goes into the drain and on large sets such degenerative cases are not only common, they can happen in series (I suspect that on large data sets quicksort "self-created" such cases -- in other words Quicksort poisons its data during partitions making bad choices of pivot progressively more probable). Here are results from one contrarian article written by Paul Hsieh in 2004
Data is time in seconds taken to sort 10000 lists of varying size of about 3000 integers each. Download test here |
||||||||||||||||||||||||||||||
Please note that total time while important, does not tell you the whole story. Actually it reveals that using Intel compiler Heapsort can beat Quicksort even "on average" -- not a small feat. But, of course, you also need also know the standard deviation.
That means that you need to take any predictions about relative efficiency of algorithms with the grain of salt unless they are provided for at least a dozen typical sets of data as described below. Shallow authors usually limit themselves to random sets, which are of little practical importance.
It is clear that you should not use sorting algorithms in worst case O(n2) in real time applications ;-). But even is less strict environment many of algorithms are simply not suitable. In order to judge suitability of a sorting algorithms to a particular application the key question is "what do you know about the data?
Other important questions include:
Do you need a stable sort ?
Does the size of RAM allow you to use some "extra" memory (at lease Log2N ), or you need strictly "in-place" sorting ? With the current computer memory sizes you usually can afford some additional memory, so "in-place" algorithms no longer have any advantages. Generally on modern computers datasets up to several terabytes can be sorted in memory as RAM in modern two socket reached sizes of 2TB or more. Four socket servers can have even larger size of RAM.
Generally the more we know about the properties of data to be sorted, the faster we can sort them.
As we already mentioned the size of key space is one of the most important characteristics of the datasets and if we know that it contains only a few values (ratio of the number of records to the number of keys is large, like often is the case in proxy logs) we can speed sorting dramatically
Sort algorithms that use the size of key space can sort any sequence for time O(n log k) ). For example if we are sorting subset of a card deck we can take into account that there are only 52 keys in any input sequence and select an algorithms that uses limited keyspace for dramatic speeding of the sorting. In this case using generic sorting algorithm is just a waist of time.
Similar situation exist if we need to sort people ages. Here clearly the size of space is limited to interval of 1-150, if you want to be generous and expect important advancement in gerontology (especially for super rich ;-).
Moreover, the relative speed of the algorithms depends on the size of the data set: one algorithm can be faster then the other for sorting less then, say, 64 or 128 items and slower on larger sequences. Simpler algorithms with minimal housekeeping tend to perform better on small sets ,even if the are O(n2) type of algorithms. Especially algorithms that have less number of jump statement in compiled version of code. For example, insertion sort is competitive with more complex algorithms up to N=25 or so.
The more you know about the order of the array that you need to sort then faster you can sort it. If there are a high probability that the array is already sorted, inversely sorted or "almost sorted" (in many cases this is a typical input) it make sense to use one "intelligence gathering pass" over the array.
Such an "intelligence gathering pass" allow you to select a faster algorithm. this approach can be called "adaptive sorting".
The simplest way to implement such an intelligence pass is to count the number of permutations. This requires exactly N "extra" comparisons to be performs. Which, if the order is close to random, slightly increase running time of the algorithm ( it slightly increases O of the particular algorithms). But if the order of elements belong to some "extreme" cases speed up from this information can be tremendous. Among such cases:
Another important information is the range of keys used for sorting. If the range of keys is small (people age, calendar dates, IP addresses, etc) they you can speed up sorting based on this fact.
Sometimes you can benefit from compressing the key (making it shorter and more suitable for comparison, for example by converting it from string to an integer (this is possible for example for dates and IP addresses). See below
Is general, like in searching, there is tremendous space for "self-adaptation" of sorting algorithms based on statistics gathered during some carefully constructed the fist pass over the data.
The speed of sorting algorithm depends on the speed of comparison of the keys. It is evident that the speed will be highest if you compare binary numbers (32 or 64 bit) as those comparison requires a single machine instruction. Or more correctly if the key fits word or double word (4 or 8 bytes on modern computers) and you can compare keys by comparing words.
In many cases sorting of the original key can be replaced by a binary number representing the key. For example dates can always be converted to binary numbers, sorted as binary numbers and then converted back. IP addresses also can and should be converted to binary numbers for sorting.
Sometimes the array to be sorted can be converted to "almost sorted" stage by sorting just first four or eight letters of the key as binary numbers, or using some binary number produced by applying some function to each key. After that simple insertion sort can produce completely sorted array very quickly as it will perform only "short distance" moves of keys.
If resulting sorting order is irrelevant (for example when you compute frequency of visits to a particular web site from Proxy logs), and the keys are long then it is possible to compress keys, using iether zip algorithm or some kind of hash function such as MD5 to speed up comparison.
Those methods are especially important if your sort tremendous amount of keys, for example several millions.
There is not "best sorting algorithm" for all data. Various algorithms have their own strength and weaknesses. For example some "sense" already sorted or "almost sorted" data sequences and perform faster on such sets. In this sense Knuth math analysis is insufficient although "worst time" estimates are useful.
As for input data it is useful to distinguish between the following broad categories that all should be used in testing (random number sorting is a very artificial test and as such the estimate it provides does not have much practical value, unless we know that other cases behave similarly or better):
Completely randomly reshuffled array (this is the only test that naive people use in evaluating sorting algorithms) .
Already sorted array (you need to see how horrible Quicksort is on this case and how good shellsort is ;-). This is actually a pretty important case as often sorting is actually resorting of previously sorted data done after minimal modifications of the data set. There are three important case of already sorted array
Array of distinct elements sorted in "right" direction for which no any reordering is required (triangular array).
Already sorted array consisting of small number of identical elements (stairs). The worst case is rectangular array in when single element is present (all values are identical).
Already sorted in reverse order array (many algorithms, such as insertion sort work slow on such an array)
Array that consisted of merged already sorted arrays (Chainsaw array). Arrays can be sorted
In the right direction for all subarrays. For example, several already sorted arrays were (stupidly) concatenated producing a large array instead of being merged.
In the opposite direction for all arrays.
Both sorted in right and opposite direction (one case is so called "symmetrical chainsaw" -- a very interesting test for most classic sorting algorithms with pretty surprising results ).
Array consisting of small number of frequently repeated identical elements (sometimes called "few unique" case). If number of distinct elements is large this is the case similar to chainsaw but without advantage of preordering. So it can be generated by "inflicting" certain number of permutations on chainsaw array. Worst case is when there is just two values of elements in the array (binary array). Quicksort is horrible on such data. Many other algorithms work slow on such an array.
Already sorted in right direction array with N permutations (with N from 0.1 to 10% of the size is called "almost sorted" array). Insertion sort does well on such arrays. Shellsort also is quick. Quick sort do not adapt well to nearly sorted data.
Already sorted array in reverse order array with N permutations
Large data sets with normal distribution of keys.
Pseudorandom data (daily values of S&P500 or other index for a decade or two might be a good test set here; they are available from Yahoo.com )
Behavior on "almost sorted" data and worst case behavior are a very important characteristics of sorting algorithms. For example, in sorting n objects, merge sort has an average and worst-case performance of O(n log n). If the input is already sorted, its complexity falls to O(n). Specifically, n-1 comparisons and zero moves are performed, which is the same as for simply running through the input, checking if it is pre-sorted. In Perl 5.8, merge sort is its default sorting algorithm (it was quicksort in previous versions of Perl). Python uses timsort, a hybrid of merge sort and insertion sort, which will also become the standard sort algorithm for Java SE 7.
Calculation of the number of comparisons and number of data moves can be done in any language. C and other compiled languages provide an opportunity to see the effect of computer instruction set and CPU speed on the sorting performance. Usually the test program is written as a subroutine that is called, say, 1000 times. Then data entry time (running just data coping or data generating part the same number of times without any sorting) is subtracted from the first.
Such a method can provide more or less accurate estimate of actual algorithms run time on a particular data set and particular CPU architecture. Modern CPUs that have a lot of general purpose registers tend to perform better on sorting: sorting algorithms tend to belong to the class of algorithms with tight inner loop and speed of this inner loop has disproportionate effect on the total run time. If most scalar variables used in this inner look can be kept in registers times improves considerably.
Artificial computers like Knuth MIXX can be used too. In this case the time is calculated based on the time table of performing of each instruction (instruction cost metric).
While choosing the language is somewhat a religious issue, there are good and bad language for sorting algorithms implementations. See Language Design and Programming Quotes for enlightened discussion of this very touchy subject ;-)
BTW you can use Perl or other interpreted scripting language in a similar way as the assembler of artificial computer like MIX. I actually prefer Perl as a tool of exploring sorting as this is an interpreted language (you do not need to compile anything) with a very good debugger and powerful control structures. And availability of powerful control structures is one thing that matter in implementation of sorting algorithms. Life is more complex then proponents of structured programming were trying us to convince.
I would like to stress it again that that a lot of examples in the textbooks are implemented with errors. For some reason that's especially true for Java books and Java demo implementations. Please use Knuth's book for reference.
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
May 23, 2021 | www.tecmint.com
7. Sort the contents of file ' lsl.txt ' on the basis of 2nd column (which represents number of symbolic links).
$ sort -nk2 lsl.txtNote: The ' -n ' option in the above example sort the contents numerically. Option ' -n ' must be used when we wanted to sort a file on the basis of a column which contains numerical values.
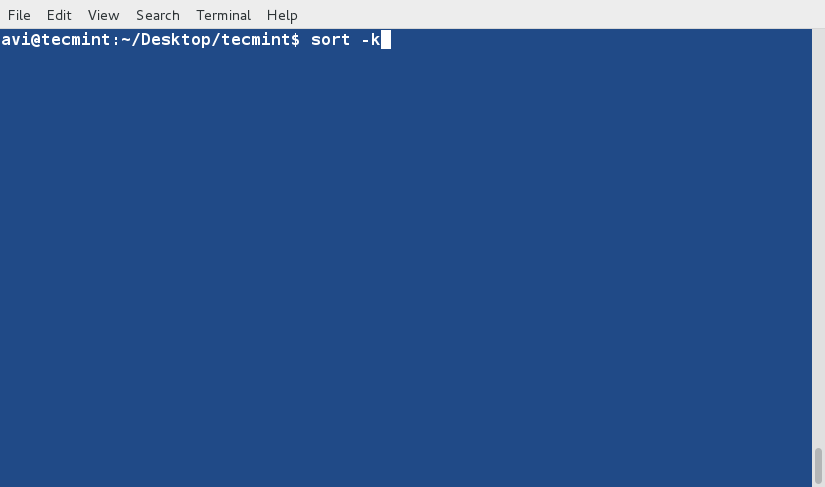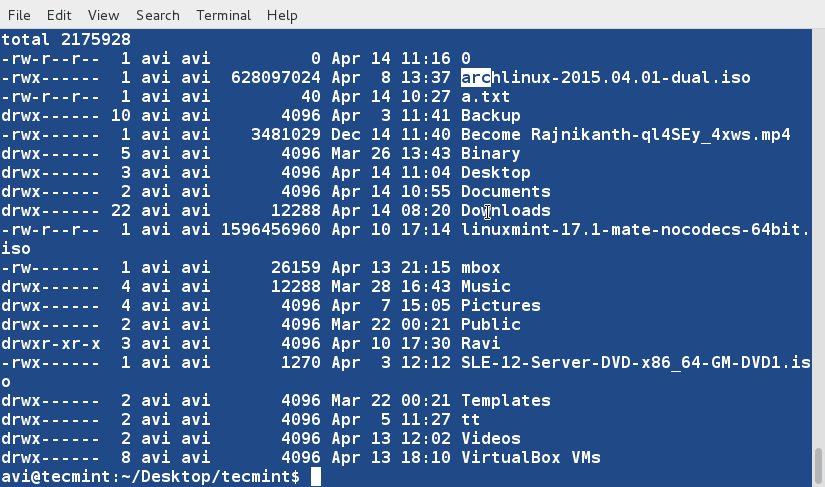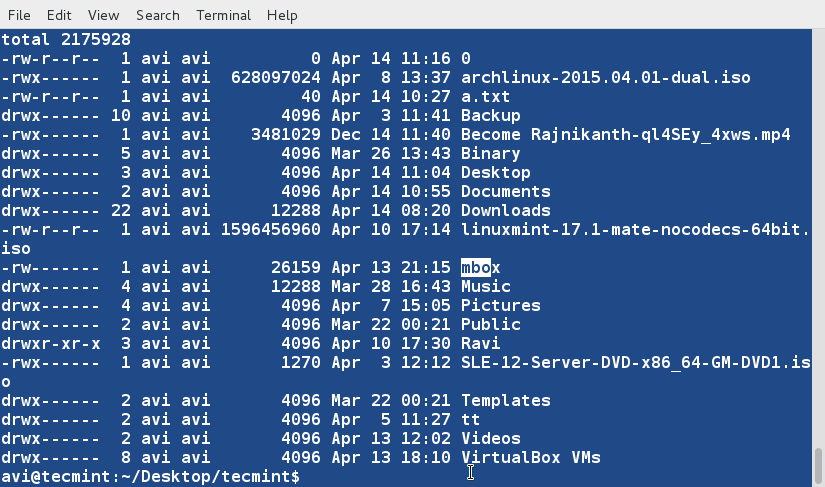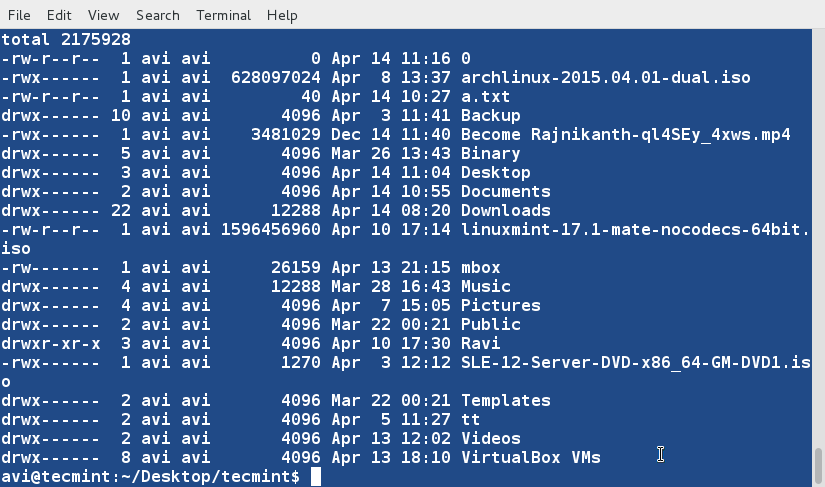
8. Sort the contents of file ' lsl.txt ' on the basis of 9th column (which is the name of the files and folders and is non-numeric).
$ sort -k9 lsl.txt
9. It is not always essential to run sort command on a file. We can pipeline it directly on the terminal with actual command.
$ ls -l /home/$USER | sort -nk5
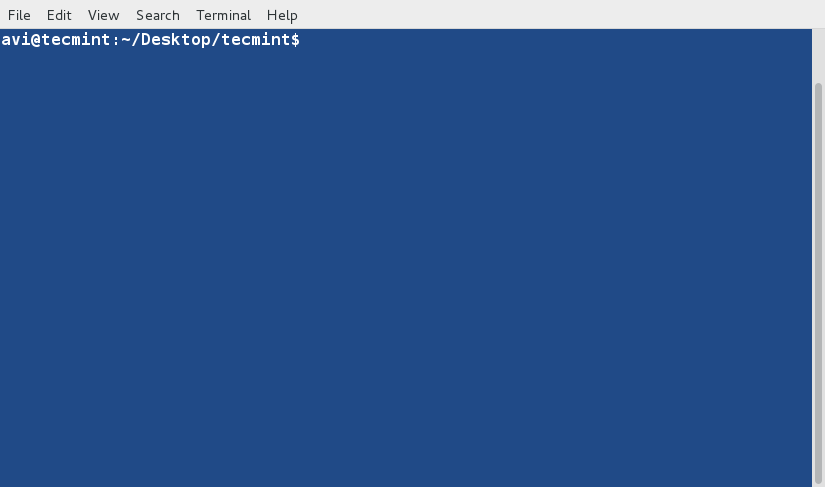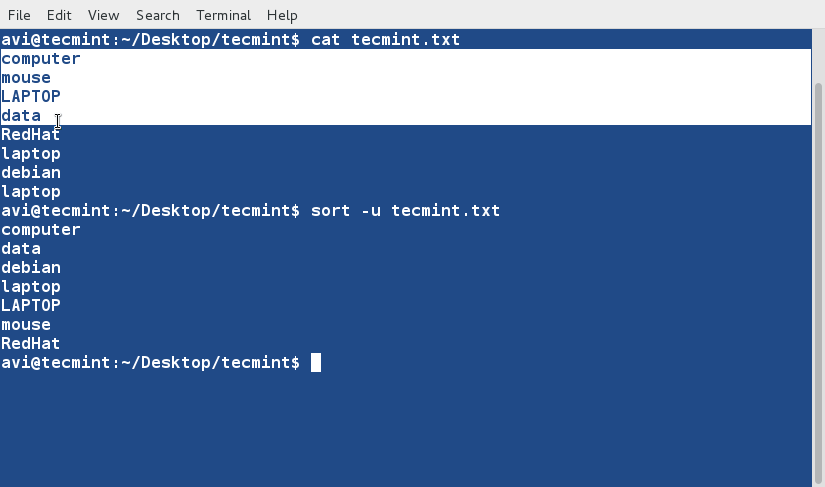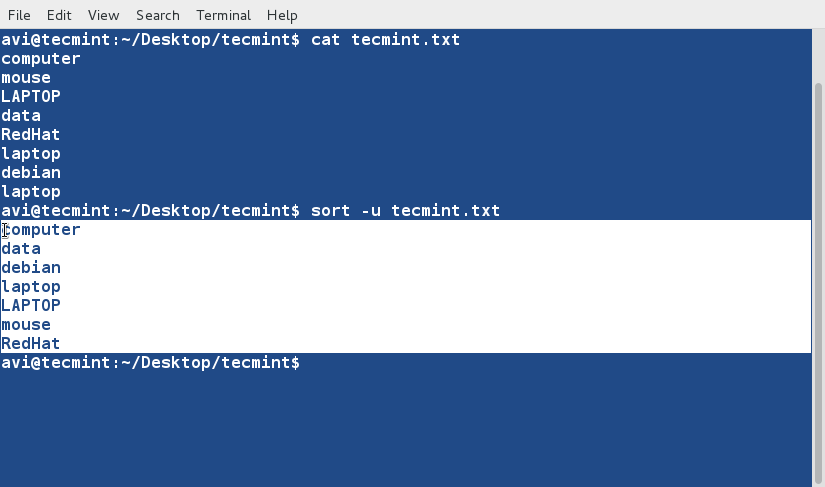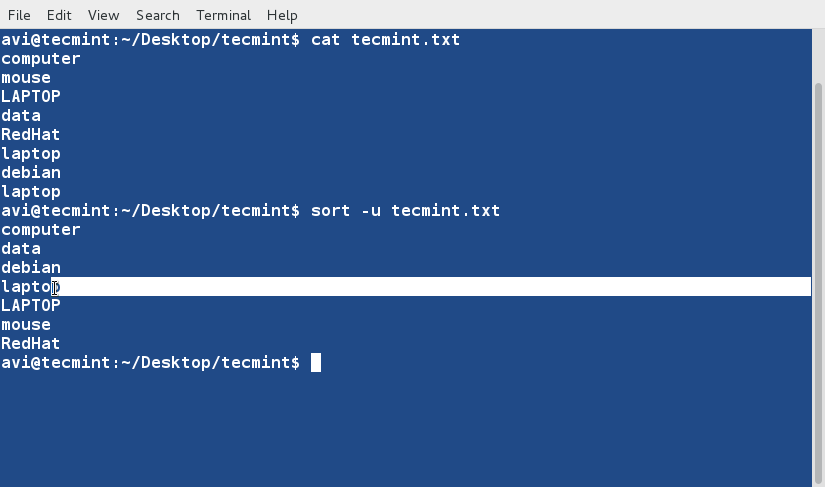
10. Sort and remove duplicates from the text file tecmint.txt . Check if the duplicate has been removed or not.
$ cat tecmint.txt $ sort -u tecmint.txt
Rules so far (what we have observed):
- Lines starting with numbers are preferred in the list and lies at the top until otherwise specified ( -r ).
- Lines starting with lowercase letters are preferred in the list and lies at the top until otherwise specified ( -r ).
- Contents are listed on the basis of occurrence of alphabets in dictionary until otherwise specified ( -r ).
- Sort command by default treat each line as string and then sort it depending upon dictionary occurrence of alphabets (Numeric preferred; see rule – 1) until otherwise specified.
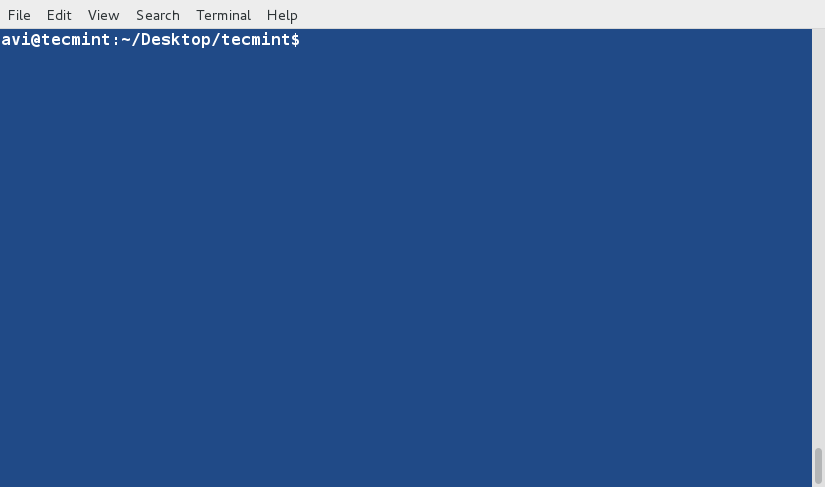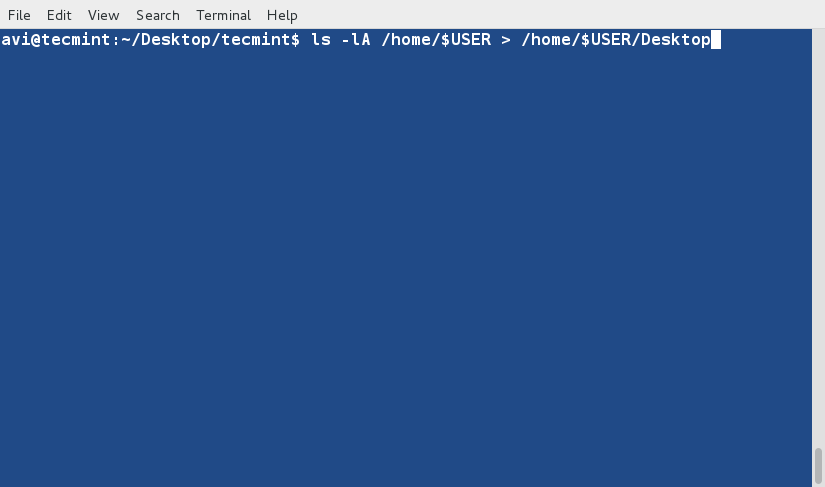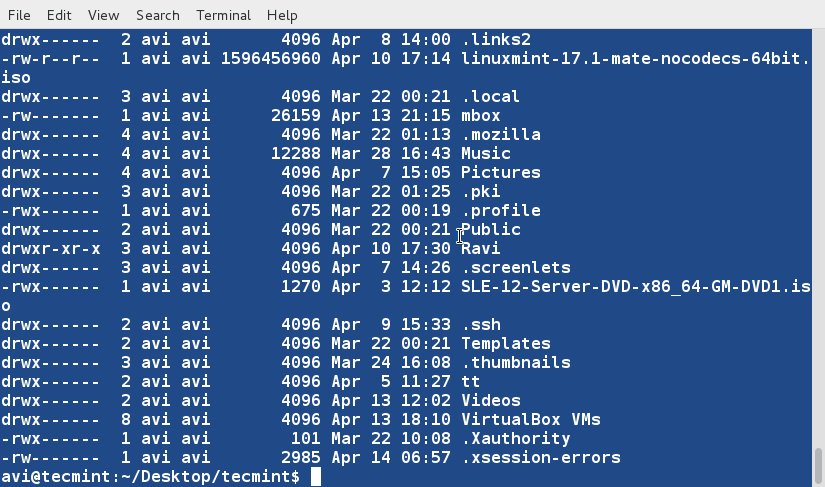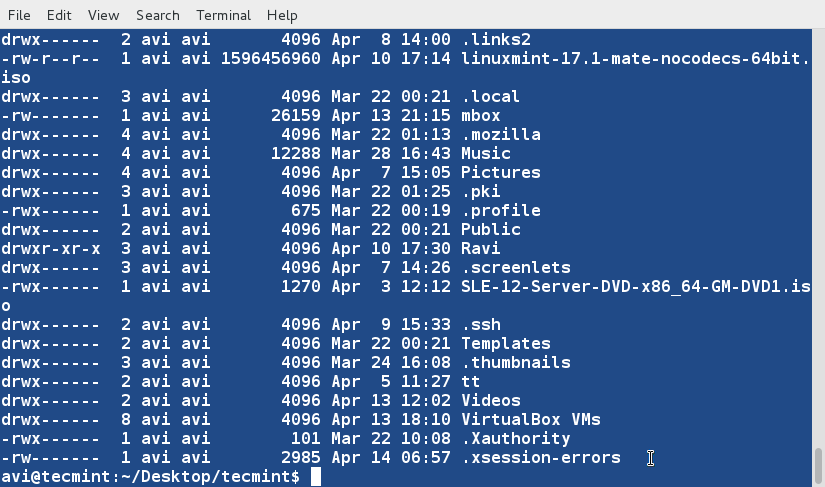
11. Create a third file ' lsla.txt ' at the current location and populate it with the output of ' ls -lA ' command.
$ ls -lA /home/$USER > /home/$USER/Desktop/tecmint/lsla.txt $ cat lsla.txt
Those having understanding of ' ls ' command knows that ' ls -lA'='ls -l ' + Hidden files. So most of the contents on these two files would be same.
12. Sort the contents of two files on standard output in one go.
$ sort lsl.txt lsla.txt
Notice the repetition of files and folders.
13. Now we can see how to sort, merge and remove duplicates from these two files.
$ sort -u lsl.txt lsla.txt
Notice that duplicates has been omitted from the output. Also, you can write the output to a new file by redirecting the output to a file.
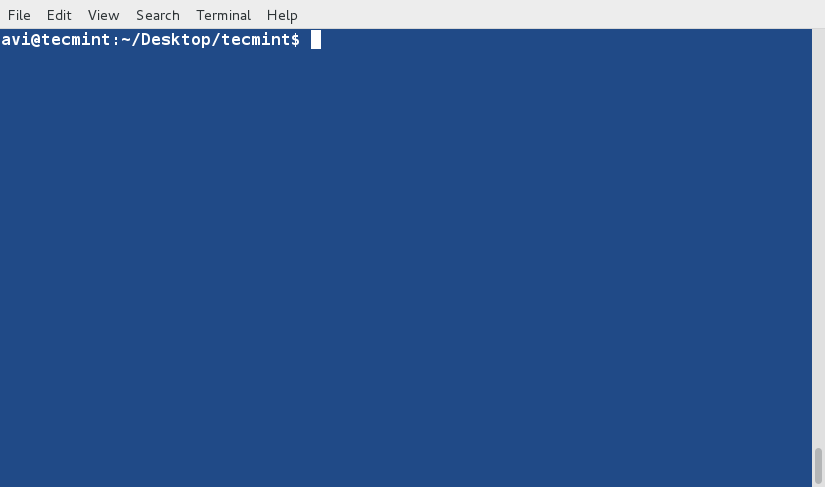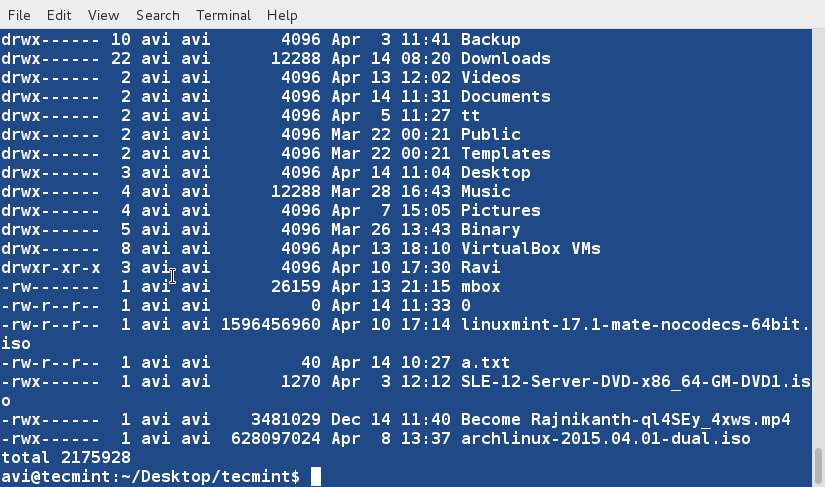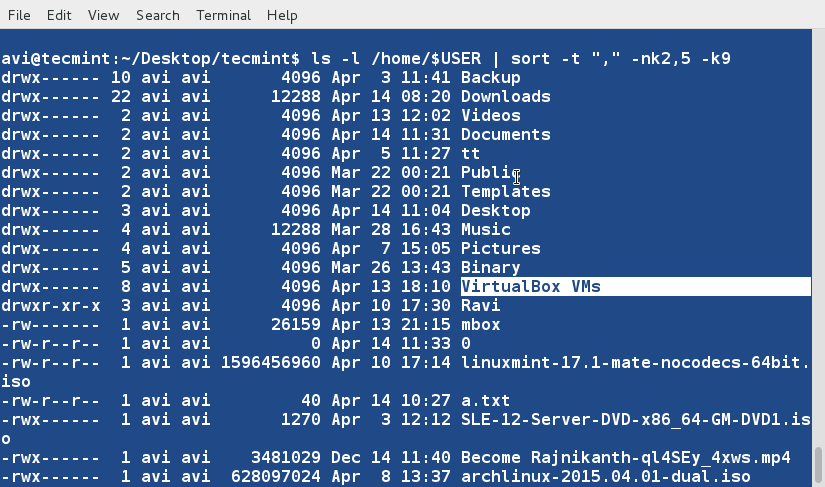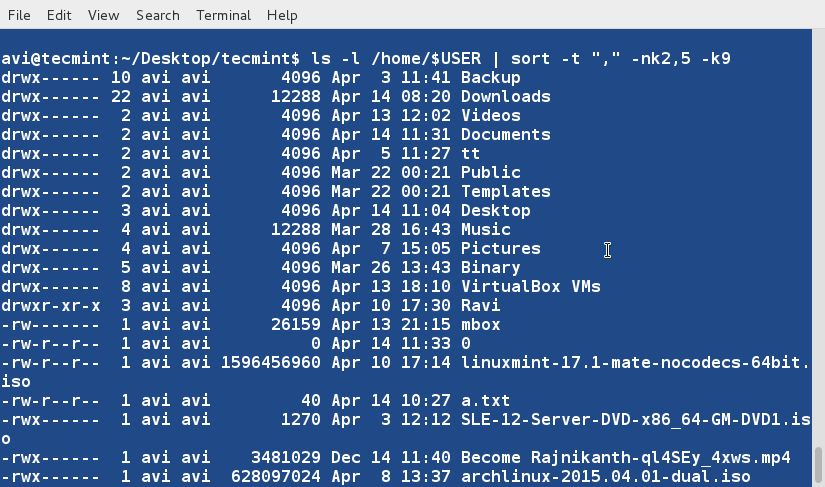
14. We may also sort the contents of a file or the output based upon more than one column. Sort the output of ' ls -l ' command on the basis of field 2,5 (Numeric) and 9 (Non-Numeric).
$ ls -l /home/$USER | sort -t "," -nk2,5 -k9
That's all for now. In the next article we will cover a few more examples of ' sort ' command in detail for you. Till then stay tuned and connected to Tecmint. Keep sharing. Keep commenting. Like and share us and help us get spread.
Jul 12, 2019 | linuxhandbook.com
5. Sort by months [option -M]Sort also has built in functionality to arrange by month. It recognizes several formats based on locale-specific information. I tried to demonstrate some unqiue tests to show that it will arrange by date-day, but not year. Month abbreviations display before full-names.
Here is the sample text file in this example:
March
Feb
February
April
August
July
June
November
October
December
May
September
1
4
3
6
01/05/19
01/10/19
02/06/18Let's sort it by months using the -M option:
sort filename.txt -MHere's the output you'll see:
01/05/19 01/10/19 02/06/18 1 3 4 6 Jan Feb February March April May June July August September October November December... ... ...
7. Sort Specific Column [option -k]If you have a table in your file, you can use the
-koption to specify which column to sort. I added some arbitrary numbers as a third column and will display the output sorted by each column. I've included several examples to show the variety of output possible. Options are added following the column number.1. MX Linux 100
2. Manjaro 400
3. Mint 300
4. elementary 500
5. Ubuntu 200sort filename.txt -k 2This will sort the text on the second column in alphabetical order:
4. elementary 500 2. Manjaro 400 3. Mint 300 1. MX Linux 100 5. Ubuntu 200sort filename.txt -k 3nThis will sort the text by the numerals on the third column.
1. MX Linux 100 5. Ubuntu 200 3. Mint 300 2. Manjaro 400 4. elementary 500sort filename.txt -k 3nrSame as the above command just that the sort order has been reversed.
4. elementary 500 2. Manjaro 400 3. Mint 300 5. Ubuntu 200 1. MX Linux 1008. Sort and remove duplicates [option -u]If you have a file with potential duplicates, the
READ Learn to Use CURL Command in Linux With These Examples-uoption will make your life much easier. Remember that sort will not make changes to your original data file. I chose to create a new file with just the items that are duplicates. Below you'll see the input and then the contents of each file after the command is run.1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntu
1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntu
1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntusort filename.txt -u > filename_duplicates.txtHere's the output files sorted and without duplicates.
1. MX Linux 2. Manjaro 3. Mint 4. elementary 5. Ubuntu9. Ignore case while sorting [option -f]Many modern distros running sort will implement ignore case by default. If yours does not, adding the
-foption will produce the expected results.sort filename.txt -fHere's the output where cases are ignored by the sort command:
alpha alPHa Alpha ALpha beta Beta BEta BETA10. Sort by human numeric values [option -h]This option allows the comparison of alphanumeric values like 1k (i.e. 1000).
sort filename.txt -hHere's the sorted output:
10.0 100 1000.0 1kI hope this tutorial helped you get the basic usage of the sort command in Linux. If you have some cool sort trick, why not share it with us in the comment section?
Christopher works as a Software Developer in Orlando, FL. He loves open source, Taco Bell, and a Chi-weenie named Max. Visit his website for more information or connect with him on social media.
JohnThe sort command option "k" specifies a field, not a column. In your example all five lines have the same character in column 2 – a "."Stephane Chauveau
In gnu sort, the default field separator is 'blank to non-blank transition' which is a good default to separate columns. In his example, the "." is part of the first column so it should work fine. If –debug is used then the range of characters used as keys is dumped.What is probably missing in that article is a short warning about the effect of the current locale. It is a common mistake to assume that the default behavior is to sort according ASCII texts according to the ASCII codes. For example, the command echo `printf ".nxn0nXn@në" | sort` produces ". 0 @ X x ë" with LC_ALL=C but ". @ 0 ë x X" with LC_ALL=en_US.UTF-8.
Dec 27, 2018 | en.wikipedia.org
Comb sort is a relatively simple sorting algorithm originally designed by Włodzimierz Dobosiewicz in 1980. [1] [2] Later it was rediscovered by Stephen Lacey and Richard Box in 1991. [3] Comb sort improves on bubble sort . Contents
Algorithm [ edit ]The basic idea is to eliminate turtles , or small values near the end of the list, since in a bubble sort these slow the sorting down tremendously. Rabbits , large values around the beginning of the list, do not pose a problem in bubble sort.
In bubble sort , when any two elements are compared, they always have a gap (distance from each other) of 1. The basic idea of comb sort is that the gap can be much more than 1. The inner loop of bubble sort, which does the actual swap , is modified such that gap between swapped elements goes down (for each iteration of outer loop) in steps of a "shrink factor" k : [ n / k , n / k 2 , n / k 3 , ..., 1 ].
The gap starts out as the length of the list n being sorted divided by the shrink factor k (generally 1.3; see below) and one pass of the aforementioned modified bubble sort is applied with that gap. Then the gap is divided by the shrink factor again, the list is sorted with this new gap, and the process repeats until the gap is 1. At this point, comb sort continues using a gap of 1 until the list is fully sorted. The final stage of the sort is thus equivalent to a bubble sort, but by this time most turtles have been dealt with, so a bubble sort will be efficient.
The shrink factor has a great effect on the efficiency of comb sort. k = 1.3 has been suggested as an ideal shrink factor by the authors of the original article after empirical testing on over 200,000 random lists. A value too small slows the algorithm down by making unnecessarily many comparisons, whereas a value too large fails to effectively deal with turtles, making it require many passes with 1 gap size.
The pattern of repeated sorting passes with decreasing gaps is similar to Shellsort , but in Shellsort the array is sorted completely each pass before going on to the next-smallest gap. Comb sort's passes do not completely sort the elements. This is the reason that Shellsort gap sequences have a larger optimal shrink factor of about 2.2.
Pseudocode
function combsort(array input) gap := input.size // Initialize gap size shrink := 1.3 // Set the gap shrink factor sorted := false loop while sorted = false // Update the gap value for a next comb gap := floor(gap / shrink) if gap ≤ 1 gap := 1 sorted := true // If there are no swaps this pass, we are done end if // A single "comb" over the input list i := 0 loop while i + gap < input.size // See Shell sort for a similar idea if input[i] > input[i+gap] swap(input[i], input[i+gap]) sorted := false // If this assignment never happens within the loop, // then there have been no swaps and the list is sorted. end if i := i + 1 end loop end loop end function
Dec 25, 2018 | news.ycombinator.com
Slightly Skeptical View on Sorting Algorithms ( softpanorama.org ) 17 points by nkurz on Oct 14, 2014 | hide | past | web | favorite | 12 comments
flebron on Oct 14, 2014 [-]
>Please note that O matters. Even if both algorithms belong to O(n log n) class, algorithm for which O=1 is 100 times faster then algorithm for which O=100.Wait, what? O = 100? That's just... not how it works.
nightcracker on Oct 14, 2014 [-]
I think they meant to illustrate that O(100) == O(1), despite a runtime of 100 being a hundred times slower than 1.
parados on Oct 14, 2014 [-]
I think what the author meant was that the elapsed time to sort: t = k * O(f(n)). So given two algorithms that have the same O(f(n)) then the smaller the k, the faster the sort.
mqsiuser on Oct 14, 2014 [-]
> Among complex algorithms Mergesort is stable> Among non-stable algorithms [...] quicksort [...]
QuickSort can be implemented so that it is stable: http://www.mqseries.net/phpBB2/viewtopic.php?p=273722&highli... (I am author, AMA)
Why is gnu-core-utils-sort implemented as mergesort (also in place, but slower) ?
Edit: And sorry: In-Place matters: Quicksort is fastest AND uses least memory.
Who the heck can say sth about the imput (that it may be like "pre-sorted" ?!)
wffurr on Oct 14, 2014 [-]
>> Who the heck can say sth about the imput (that it may be like "pre-sorted" ?!)Lots of real world (as opposed to synthetic random test data) may be already ordered or contain ordered subsequences. One wants to run a sorting algorithm to guarantee the data is sorted, and thus performance on pre-sorted data is important.
This is why Timsort is the default sort in Python and Java. http://en.m.wikipedia.org/wiki/Timsort
It is the worst case performance for quick sort.
abetusk on Oct 14, 2014 [-]
As far as I know, Quicksort cannot be implemented to be stable without an auxiliary array. So implementing Quicksort to be stable destroys the in-place feature.If you want something in-place and stable, you'll have to use something like WikiSort [1] or GrailSort [2].
mqsiuser on Oct 14, 2014 [-]
> Quicksort cannot be implemented to be stable without an auxiliary arrayOkay, you need an additional array (I am using a separate array, the "result array") [1]: But that doesn't matter, since the additional array can just grow (while the partitions/other arrays shrink).
Though my implementation is not cache-aware, which is very interesting and pretty relevant for performance.
[1] Actually I am using a linked tree data structure: "In-place"... which IS HIGHLY relevant: It can occur that the input data is large ((already) filling up (almost) all RAM) and these programs ("Execution Groups") terminate "the old way", so just 'abend'.
And hence it stands: By the way I have proven that you can implement QuickSort STABLE AND IN-PLACE
Thank you :) and fix you wording, when saying "Quicksort is..."
TheLoneWolfling on Oct 14, 2014 [-]
The problem with radix sort is the same problem in general with big-O notation:A factor of log(n) (or less) difference can often be overwhelmed for all practical inputs by a constant factor.
sika_grr on Oct 14, 2014 [-]
No. For radix sort this constant factor is quite low, so it outperforms std::sort in most cases.Try sorting a million integers, my results are: std::sort: 60 ms; radix-sort (LSB, hand coded, less than 20 lines): 11 ms. It gets even better when you mix MSB with LSB for better locality.
No, there are no problems with doubles or negative integers. For sizeof(key_value)<=16 B (8 for key, 8 for pointer), radix is the best sort on desktop computers.
sika_grr on Oct 14, 2014 [-]
Please note that radix sort is easy to implement to work correctly with doubles, Table 1 is misleading.
whoisjuan on Oct 14, 2014 [-]
timsort?
cbd1984 on Oct 14, 2014 [-]
It was invented by Tim Peters for Python, and has been the default there since 2.3. The Java runtime uses it to sort arrays of non-primitive type (that is, arrays of values that can be treated as Objects).http://en.wikipedia.org/wiki/Timsort
OpenJDK implementation. Good notes in the comments:
http://cr.openjdk.java.net/~martin/webrevs/openjdk7/timsort/...
Sep 25, 2018 | www.amazon.com
awk , cut , and join , sort views its input as a stream of records made up of fields of variable width, with records delimited by newline characters and fields delimited by whitespace or a user-specifiable single character.sort
- Usage
- sort [ options ] [ file(s) ]
- Purpose
- Sort input lines into an order determined by the key field and datatype options, and the locale.
- Major options
- -b
- Ignore leading whitespace.
- -c
- Check that input is correctly sorted. There is no output, but the exit code is nonzero if the input is not sorted.
- -d
- Dictionary order: only alphanumerics and whitespace are significant.
- -g
- General numeric value: compare fields as floating-point numbers. This works like -n , except that numbers may have decimal points and exponents (e.g., 6.022e+23 ). GNU version only.
- -f
- Fold letters implicitly to a common lettercase so that sorting is case-insensitive.
- -i
- Ignore nonprintable characters.
- -k
- Define the sort key field.
- -m
- Merge already-sorted input files into a sorted output stream.
- -n
- Compare fields as integer numbers.
- -o outfile
- Write output to the specified file instead of to standard output. If the file is one of the input files, sort copies it to a temporary file before sorting and writing the output.
- -r
- Reverse the sort order to descending, rather than the default ascending.
- -t char
- Use the single character char as the default field separator, instead of the default of whitespace.
- -u
- Unique records only: discard all but the first record in a group with equal keys. Only the key fields matter: other parts of the discarded records may differ.
- Behavior
- sort reads the specified files, or standard input if no files are given, and writes the sorted data on standard output.
Sorting by LinesIn the simplest case, when no command-line options are supplied, complete records are sorted according to the order defined by the current locale. In the traditional C locale, that means ASCII order, but you can set an alternate locale as we described in Section 2.8 . A tiny bilingual dictionary in the ISO 8859-1 encoding translates four French words differing only in accents:
$ cat french-english Show the tiny dictionary côte coast cote dimension coté dimensioned côté sideTo understand the sorting, use the octal dump tool, od , to display the French words in ASCII and octal:$ cut -f1 french-english | od -a -b Display French words in octal bytes 0000000 c t t e nl c o t e nl c o t i nl c 143 364 164 145 012 143 157 164 145 012 143 157 164 351 012 143 0000020 t t i nl 364 164 351 012 0000024Evidently, with the ASCII option -a , od strips the high-order bit of characters, so the accented letters have been mangled, but we can see their octal values: é is 351 8 and ô is 364 8 . On GNU/Linux systems, you can confirm the character values like this:$ man iso_8859_1 Check the ISO 8859-1 manual page ... Oct Dec Hex Char Description -------------------------------------------------------------------- ... 351 233 E9 é LATIN SMALL LETTER E WITH ACUTE ... 364 244 F4 ô LATIN SMALL LETTER O WITH CIRCUMFLEX ...First, sort the file in strict byte order:$ LC_ALL=C sort french-english Sort in traditional ASCII order cote dimension coté dimensioned côte coast côté sideNotice that e (145 8 ) sorted before é (351 8 ), and o (157 8 ) sorted before ô (364 8 ), as expected from their numerical values. Now sort the text in Canadian-French order:$ LC_ALL=fr_CA.iso88591 sort french-english Sort in Canadian-French locale côte coast cote dimension coté dimensioned côté sideThe output order clearly differs from the traditional ordering by raw byte values. Sorting conventions are strongly dependent on language, country, and culture, and the rules are sometimes astonishingly complex. Even English, which mostly pretends that accents are irrelevant, can have complex sorting rules: examine your local telephone directory to see how lettercase, digits, spaces, punctuation, and name variants like McKay and Mackay are handled.
Sorting by FieldsFor more control over sorting, the -k option allows you to specify the field to sort on, and the -t option lets you choose the field delimiter. If -t is not specified, then fields are separated by whitespace and leading and trailing whitespace in the record is ignored. With the -t option, the specified character delimits fields, and whitespace is significant. Thus, a three-character record consisting of space-X-space has one field without -t , but three with -t ' ' (the first and third fields are empty). The -k option is followed by a field number, or number pair, optionally separated by whitespace after -k . Each number may be suffixed by a dotted character position, and/or one of the modifier letters shown in Table.
Letter
Description
b
Ignore leading whitespace.
d
Dictionary order.
f
Fold letters implicitly to a common lettercase.
g
Compare as general floating-point numbers. GNU version only.
i
Ignore nonprintable characters.
n
Compare as (integer) numbers.
r
Reverse the sort order.
Fields and characters within fields are numbered starting from one.
If only one field number is specified, the sort key begins at the start of that field, and continues to the end of the record ( not the end of the field).
If a comma-separated pair of field numbers is given, the sort key starts at the beginning of the first field, and finishes at the end of the second field.
With a dotted character position, comparison begins (first of a number pair) or ends (second of a number pair) at that character position: -k2.4,5.6 compares starting with the fourth character of the second field and ending with the sixth character of the fifth field.
If the start of a sort key falls beyond the end of the record, then the sort key is empty, and empty sort keys sort before all nonempty ones.
When multiple -k options are given, sorting is by the first key field, and then, when records match in that key, by the second key field, and so on.
! While the -k option is available on all of the systems that we tested, sort also recognizes an older field specification, now considered obsolete, where fields and character positions are numbered from zero. The key start for character m in field n is defined by + n.m , and the key end by - n.m . For example, sort +2.1 -3.2 is equivalent to sort -k3.2,4.3 . If the character position is omitted, it defaults to zero. Thus, +4.0nr and +4nr mean the same thing: a numeric key, beginning at the start of the fifth field, to be sorted in reverse (descending) order.
Let's try out these options on a sample password file, sorting it by the username, which is found in the first colon-separated field:$ sort -t: -k1,1 /etc/passwd Sort by username bin:x:1:1:bin:/bin:/sbin/nologin chico:x:12501:1000:Chico Marx:/home/chico:/bin/bash daemon:x:2:2:daemon:/sbin:/sbin/nologin groucho:x:12503:2000:Groucho Marx:/home/groucho:/bin/sh gummo:x:12504:3000:Gummo Marx:/home/gummo:/usr/local/bin/ksh93 harpo:x:12502:1000:Harpo Marx:/home/harpo:/bin/ksh root:x:0:0:root:/root:/bin/bash zeppo:x:12505:1000:Zeppo Marx:/home/zeppo:/bin/zshFor more control, add a modifier letter in the field selector to define the type of data in the field and the sorting order. Here's how to sort the password file by descending UID:
$ sort -t: -k3nr /etc/passwd Sort by descending UID zeppo:x:12505:1000:Zeppo Marx:/home/zeppo:/bin/zsh gummo:x:12504:3000:Gummo Marx:/home/gummo:/usr/local/bin/ksh93 groucho:x:12503:2000:Groucho Marx:/home/groucho:/bin/sh harpo:x:12502:1000:Harpo Marx:/home/harpo:/bin/ksh chico:x:12501:1000:Chico Marx:/home/chico:/bin/bash daemon:x:2:2:daemon:/sbin:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin root:x:0:0:root:/root:/bin/bashA more precise field specification would have been -k3nr,3 (that is, from the start of field three, numerically, in reverse order, to the end of field three), or -k3,3nr , or even -k3,3 -n -r , but sort stops collecting a number at the first nondigit, so -k3nr works correctly.
In our password file example, three users have a common GID in field 4, so we could sort first by GID, and then by UID, with:
$ sort -t: -k4n -k3n /etc/passwd Sort by GID and UID root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin chico:x:12501:1000:Chico Marx:/home/chico:/bin/bash harpo:x:12502:1000:Harpo Marx:/home/harpo:/bin/ksh zeppo:x:12505:1000:Zeppo Marx:/home/zeppo:/bin/zsh groucho:x:12503:2000:Groucho Marx:/home/groucho:/bin/sh gummo:x:12504:3000:Gummo Marx:/home/gummo:/usr/local/bin/ksh93The useful -u option asks sort to output only unique records, where unique means that their sort-key fields match, even if there are differences elsewhere. Reusing the password file one last time, we find:
$ sort -t: -k4n -u /etc/passwd Sort by unique GID root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin chico:x:12501:1000:Chico Marx:/home/chico:/bin/bash groucho:x:12503:2000:Groucho Marx:/home/groucho:/bin/sh gummo:x:12504:3000:Gummo Marx:/home/gummo:/usr/local/bin/ksh93Notice that the output is shorter: three users are in group 1000, but only one of them was output...
Sorting Text BlocksSometimes you need to sort data composed of multiline records. A good example is an address list, which is conveniently stored with one or more blank lines between addresses. For data like this, there is no constant sort-key position that could be used in a -k option, so you have to help out by supplying some extra markup. Here's a simple example:
$ cat my-friends Show address file # SORTKEY: Schloß, Hans Jürgen Hans Jürgen Schloß Unter den Linden 78 D-10117 Berlin Germany # SORTKEY: Jones, Adrian Adrian Jones 371 Montgomery Park Road Henley-on-Thames RG9 4AJ UK # SORTKEY: Brown, Kim Kim Brown 1841 S Main Street Westchester, NY 10502 USAThe sorting trick is to use the ability of awk to handle more-general record separators to recognize paragraph breaks, temporarily replace the line breaks inside each address with an otherwise unused character, such as an unprintable control character, and replace the paragraph break with a newline. sort then sees lines that look like this:
# SORTKEY: Schloß, Hans Jürgen^ZHans Jürgen Schloß^ZUnter den Linden 78^Z... # SORTKEY: Jones, Adrian^ZAdrian Jones^Z371 Montgomery Park Road^Z... # SORTKEY: Brown, Kim^ZKim Brown^Z1841 S Main Street^Z...Here, ^Z is a Ctrl-Z character. A filter step downstream from sort restores the line breaks and paragraph breaks, and the sort key lines are easily removed, if desired, with grep . The entire pipeline looks like this:
cat my-friends | Pipe in address file awk -v RS="" { gsub("\n", "^Z"); print }' | Convert addresses to single lines sort -f | Sort address bundles, ignoring case awk -v ORS="\n\n" '{ gsub("^Z", "\n"); print }' | Restore line structure grep -v '# SORTKEY' Remove markup linesThe gsub( ) function performs "global substitutions." It is similar to the s/x/y/g construct in sed . The RS variable is the input Record Separator. Normally, input records are separated by newlines, making each line a separate record. Using RS=" " is a special case, whereby records are separated by blank lines; i.e., each block or "paragraph" of text forms a separate record. This is exactly the form of our input data. Finally, ORS is the Output Record Separator; each output record printed with print is terminated with its value. Its default is also normally a single newline; setting it here to " \n\n " preserves the input format with blank lines separating records. (More detail on these constructs may be found in Chapter 9 .)
The beauty of this approach is that we can easily include additional keys in each address that can be used for both sorting and selection: for example, an extra markup line of the form:
# COUNTRY: UKin each address, and an additional pipeline stage of grep '# COUNTRY: UK ' just before the sort , would let us extract only the UK addresses for further processing.
You could, of course, go overboard and use XML markup to identify the parts of the address in excruciating detail:
<address> <personalname>Hans Jürgen</personalname> <familyname>Schloß</familyname> <streetname>Unter den Linden<streetname> <streetnumber>78</streetnumber> <postalcode>D-10117</postalcode> <city>Berlin</city> <country>Germany</country> </address>With fancier data-processing filters, you could then please your post office by presorting your mail by country and postal code, but our minimal markup and simple pipeline are often good enough to get the job done.
4.1.4. Sort EfficiencyThe obvious way to sort data requires comparing all pairs of items to see which comes first, and leads to algorithms known as bubble sort and insertion sort . These quick-and-dirty algorithms are fine for small amounts of data, but they certainly are not quick for large amounts, because their work to sort n records grows like n 2 . This is quite different from almost all of the filters that we discuss in this book: they read a record, process it, and output it, so their execution time is directly proportional to the number of records, n .
Fortunately, the sorting problem has had lots of attention in the computing community, and good sorting algorithms are known whose average complexity goes like n 3/2 ( shellsort ), n log n ( heapsort , mergesort , and quicksort ), and for restricted kinds of data, n ( distribution sort ). The Unix sort command implementation has received extensive study and optimization: you can be confident that it will do the job efficiently, and almost certainly better than you can do yourself without learning a lot more about sorting algorithms.
4.1.5. Sort StabilityAn important question about sorting algorithms is whether or not they are stable : that is, is the input order of equal records preserved in the output? A stable sort may be desirable when records are sorted by multiple keys, or more than once in a pipeline. POSIX does not require that sort be stable, and most implementations are not, as this example shows:
$ sort -t_ -k1,1 -k2,2 << EOF Sort four lines by first two fields> one_two > one_two_three > one_two_four > one_two_five > EOF one_two one_two_five one_two_four one_two_threeThe sort fields are identical in each record, but the output differs from the input, so sort is not stable. Fortunately, the GNU implementation in the coreutils package [1] remedies that deficiency via the -- stable option: its output for this example correctly matches the input.
[1] Available at ftp://ftp.gnu.org/gnu/coreutils/ .
[Nov 07, 2017] Timsort, the sorting algorithms invented by Tim Peters for Cpython interpteter
Nov 07, 2017 | www.amazon.com
sortedandlist.sortis Timsort, an adaptive algorithm that switches from insertion sort to merge sort strategies, depending on how ordered the data is. This is efficient because real-world data tends to have runs of sorted items. There is a Wikipedia article about it.Timsort was first deployed in CPython, in 2002. Since 2009, Timsort is also used to sort arrays in both standard Java and Android, a fact that became widely known when Oracle used some of the code related to Timsort as evidence of Google infringement of Sun's intellectual property. See Oracle v. Google - Day 14 Filings .
Timsort was invented by Tim Peters, a Python core developer so prolific that he is believed to be an AI, the Timbot. You can read about that conspiracy theory in Python Humor . Tim also wrote The Zen of Python:
import this.
[Oct 28, 2017] C Source Code for Sort Algorithms
Oct 28, 2017 | durangobill.com
//****************************************************************************
//
// Sort Algorithms
// by
// Bill Butler
//
// This program can execute various sort algorithms to test how fast they run.
//
// Sorting algorithms include:
// Bubble sort
// Insertion sort
// Median-of-three quicksort
// Multiple link list sort
// Shell sort
//
// For each of the above, the user can generate up to 10 million random
// integers to sort. (Uses a pseudo random number generator so that the list
// to sort can be exactly regenerated.)
// The program also times how long each sort takes.
//
[Oct 28, 2017] SORTING AND SEARCHING ALGORITHMS by Tom Niemann
Oct 28, 2017 | epaperpress.com
26 pages PDF. Source code in C and Visual Basic c are linked in the original paper
This is a collection of algorithms for sorting and searching. Descriptions are brief and intuitive, with just enough theory thrown in to make you nervous. I assume you know a high-level language, such as C, and that you are familiar with programming concepts including arrays and pointers.
The first section introduces basic data structures and notation. The next section presents several sorting algorithms. This is followed by a section on dictionaries, structures that allow efficient insert, search, and delete operations. The last section describes algorithms that sort data and implement dictionaries for very large files. Source code for each algorithm, in ANSI C, is included.
Most algorithms have also been coded in Visual Basic. If you are programming in Visual Basic, I recommend you read Visual Basic Collections and Hash Tables, for an explanation of hashing and node representation.
If you are interested in translating this document to another language, please send me email. Special thanks go to Pavel Dubner, whose numerous suggestions were much appreciated. The following files may be downloaded:
source code (C) (24k)
source code (Visual Basic) (27k)
Permission to reproduce portions of this document is given provided the web site listed below is referenced, and no additional restrictions apply. Source code, when part of a software project, may be used freely without reference to the author.
Thomas Niemann
Portland, Oregon epaperpress.
Contents
Contents .......................................................................................................................................... 2
Preface ............................................................................................................................................ 3
Introduction ...................................................................................................................................... 4
Arrays........................................................................................................................................... 4
Linked Lists .................................................................................................................................. 5
Timing Estimates.......................................................................................................................... 5
Summary...................................................................................................................................... 6
Sorting ............................................................................................................................................. 7
Insertion Sort................................................................................................................................ 7
Shell Sort...................................................................................................................................... 8
Quicksort ...................................................................................................................................... 9
Comparison................................................................................................................................ 11
External Sorting.......................................................................................................................... 11
Dictionaries .................................................................................................................................... 14
Hash Tables ............................................................................................................................... 14
Binary Search Trees .................................................................................................................. 18
Red-Black Trees ........................................................................................................................ 20
Skip Lists.................................................................................................................................... 23
Comparison................................................................................................................................ 24
Bibliography................................................................................................................................... 26
[Dec 26, 2014] The World of YouTube Bubble Sort Algorithm Dancing 63
Posted by timothy
from the right-under-our-very-noses dept.theodp writes In addition to The Ghost of Steve Jobs, The Codecracker, a remix of 'The Nutcracker' performed by Silicon Valley's all-girl Castilleja School during Computer Science Education Week earlier this month featured a Bubble Sort Dance. Bubble Sort dancing, it turns out, is more popular than one might imagine. Search YouTube, for example, and you'll find students from the University of Rochester to Osmania University dancing to sort algorithms. Are you a fan of Hungarian folk-dancing? Well there's a very professionally-done Bubble Sort Dance for you! Indeed, well-meaning CS teachers are pushing kids to Bubble Sort Dance to hits like Beauty and a Beat, Roar, Gentleman, Heartbeat, Under the Sea, as well as other music.
A Comparison of Sorting Algorithms
Not clear how the data were compiled... Code is amateurish so timing should be taken with the grain of salt.
Recently, I have translated a variety of sorting routines into Visual Basic and compared their performance... I hope you will find the code for these sorts useful and interesting.

What makes a good sorting algorithm? Speed is probably the top consideration, but other factors of interest include versatility in handling various data types, consistency of performance, memory requirements, length and complexity of code, and the property of stability (preserving the original order of records that have equal keys). As you may guess, no single sort is the winner in all categories simultaneously (Table 2).

Let's start with speed, which breaks down into "order" and "overhead". When we talk about the order of a sort, we mean the relationship between the number of keys to be sorted and the time required. The best case is O(N); time is linearly proportional to the number of items. We can't do this with any sort that works by comparing keys; the best such sorts can do is O(N log N), but we can do it with a RadixSort, which doesn't use comparisons. Many simple sorts (Bubble, Insertion, Selection) have O(N^2) behavior, and should never be used for sorting long lists. But what about short lists? The other part of the speed equation is overhead resulting from complex code, and the sorts that are good for long lists tend to have more of it. For short lists of 5 to 50 keys or for long lists that are almost sorted, Insertion-Sort is extremely efficient and can be faster than finishing the same job with QuickSort or a RadixSort. Many of the routines in my collection are "hybrids", with a version of InsertionSort finishing up after a fast algorithm has done most of the job.The third aspect of speed is consistency. Some sorts always take the same amount of time , but many have "best case" and "worst case" performance for particular input orders of keys. A famous example is QuickSort, generally the fastest of the O(N log N) sorts, but it always has an O(N^2) worst case. It can be tweaked to make this worst case very unlikely to occur, but other O(N log N) sorts like HeapSort and MergeSort remain O(N log N) in their worst cases. QuickSort will almost always beat them, but occasionally they will leave it in the dust.
[Oct 10, 2010] The Heroic Tales of Sorting Algorithms
Notation:
- O(x) = Worst Case Running Time
- W(x) = Best Case Running Time
- Q(x) = Best and Worst case are the same.
Page numbers refer to the Preiss text book Data Structures and Algorithms with Object-Orientated Design Patterns in Java.
This page was created with some references to Paul's spiffy sorting algorithms page which can be found here. Most of the images scans of the text book (accept the code samples) were gratefully taken from that site.
Sorting Algorithm Page Implementation Summary Comments Type Stable? Asymptotic Complexities Straight Insertion 495 On each pass the current item is inserted into the sorted section of the list. It starts with the last position of the sorted list, and moves backwards until it finds the proper place of the current item. That item is then inserted into that place, and all items after that are shuffled to the left to accommodate it. It is for this reason, that if the list is already sorted, then the sorting would be O(n) because every element is already in its sorted position. If however the list is sorted in reverse, it would take O(n2) time as it would be searching through the entire sorted section of the list each time it does an insertion, and shuffling all other elements down the list.. Good for nearly sorted lists, very bad for out of order lists, due to the shuffling. Insertion Yes Best Case: O(n). Worst Case: O(n2)
Binary Insertion Sort 497 This is an extension of the Straight Insertion as above, however instead of doing a linear search each time for the correct position, it does a binary search, which is O(log n) instead of O(n). The only problem is that it always has to do a binary search even if the item is in its current position. This brings the cost of the best cast up to O(n log n). Due to the possibility of having to shuffle all other elements down the list on each pass, the worst case running time remains at O(n2). This is better than the Strait Insertion if the comparisons are costly. This is because even though, it always has to do log n comparisons, it would generally work out to be less than a linear search. Insertion Yes Best Case: O(n log n). Worst Case: O(n2)
Bubble Sort 499 On each pass of the data, adjacent elements are compared, and switched if they are out of order. eg. e1 with e2, then e2 with e3 and so on. This means that on each pass, the largest element that is left unsorted, has been "bubbled" to its rightful place at the end of the array. However, due to the fact that all adjacent out of order pairs are swapped, the algorithm could be finished sooner. Preiss claims that it will always take O(n2) time because it keeps sorting even if it is in order, as we can see, the algorithm doesn't recognise that. Now someone with a bit more knowledge than Preiss will obviously see, that you can end the algorithm in the case when no swaps were made, thereby making the best case O(n) (when it is already sorted) and worst case still at O(n2). In general this is better than Insertion Sort I believe, because it has a good change of being sorted in much less than O(n2) time, unless you are a blind Preiss follower. Exchange Yes. NOTE: Preiss uses a bad algorithm, and claims that best and worst case is O(n2). We however using a little bit of insight, can see that the following is correct of a better bubble sort Algorithm (which does Peake agree with?)
Best Case: O(n).
Worst Case: O(n2)
Quicksort 501 I strongly recommend looking at the diagram for this one. The code is also useful and provided below (included is the selectPivot method even though that probably won't help you understanding anyway).
The quick sort operates along these lines: Firstly a pivot is selected, and removed from the list (hidden at the end). Then the elements are partitioned into 2 sections. One which is less than the pivot, and one that is greater. This partitioning is achieved by exchanging values. Then the pivot is restored in the middle, and those 2 sections are recursively quick sorted.A complicated but effective sorting algorithm. Exchange No Best Case: O(n log n). Worst Case: O(n2)
Refer to page 506 for more information about these values. Note: Preiss on page 524 says that the worst case is O(n log n) contradicting page 506, but I believe that it is O(n2), as per page 506.
Straight Selection Sorting. 511 This one, although not very efficient is very simply. Basically, it does n2 linear passes on the list, and on each pass, it selects the largest value, and swaps it with the last unsorted element.
This means that it isn't stable, because for example a 3 could be swapped with a 5 that is to the left of a different 3.A very simple algorithm, to code, and a very simple one to explain, but a little slow. Note that you can do this using the smallest value, and swapping it with the first unsorted element.
Selection No Unlike the Bubble sort this one is truly Q(n2), where best case and worst case are the same, because even if the list is sorted, the same number of selections must still be performed. Heap Sort 513 This uses a similar idea to the Straight Selection Sorting, except, instead of using a linear search for the maximum, a heap is constructed, and the maximum can easily be removed (and the heap reformed) in log n time. This means that you will do n passes, each time doing a log n remove maximum, meaning that the algorithm will always run in Q(n log n) time, as it makes no difference the original order of the list. This utilises, just about the only good use of heaps, that is finding the maximum element, in a max heap (or the minimum of a min heap). Is in every way as good as the straight selection sort, but faster. Selection No Best Case: O(n log n). Worst Case: O(n log n).
Ok, now I know that looks tempting, but for a much more programmer friendly solution, look at Merge sort instead, for a better O(n log n) sort .2 Way Merge Sort 519 It is fairly simple to take 2 sorted lists, and combine the into another sorted list, simply by going through, comparing the heads of each list, removing the smallest to join the new sorted list. As you may guess, this is an O(n) operation. With 2 way sorting, we apply this method to an single unsorted list. In brief, the algorithm recursively splits up the array until it is fragmented into pairs of two single element arrays. Each of those single elements is then merged with its pairs, and then those pairs are merged with their pairs and so on, until the entire list is united in sorted order. Noting that if there is every an odd number, an extra operation is added, where it is added to one of the pairs, so that that particular pair will have 1 more element than most of the others, and won't have any effect on the actual sorting. Now isn't this much easier to understand that Heap sort, its really quite intuitive. This one is best explain with the aid of the diagram, and if you haven't already, you should look at it. Merge Yes Best and Worst Case: Q(n log n) Bucket Sort 526 Bucket sort initially creates a "counts" array whose size is the size of the range of all possible values for the data we are sorting, eg. all of the values could be between 1 and 100, therefore the array would have 100 elements. 2 passes are then done on the list. The first tallies up the occurrences of each of number into the "counts" array. That is for each index of the array, the data that it contains signifies the number of times that number occurred in list. The second and final pass goes though the counts array, regenerating the list in sorted form. So if there were 3 instance of 1, 0 of 2, and 1 of 3, the sorted list would be recreated to 1,1,1,3. This diagram will most likely remove all shadows of doubt in your minds. This sufferers a limitation that Radix doesn't, in that if the possible range of your numbers is very high, you would need too many "buckets" and it would be impractical. The other limitation that Radix doesn't have, that this one does is that stability is not maintained. It does however outperform radix sort if the possible range is very small. Distribution No Best and Worst case:Q(m + n) where m is the number of possible values. Obviously this is O(n) for most values of m, so long as m isn't too large. The reason that these distribution sorts break the O(n log n) barrier is because no comparisons are performed!
Radix Sort 528 This is an extremely spiffy implementation of the bucket sort algorithm. This time, several bucket like sorts are performed (one for each digit), but instead of having a counts array representing the range of all possible values for the data, it represents all of the possible values for each individual digit, which in decimal numbering is only 10. Firstly a bucked sort is performed, using only the least significant digit to sort it by, then another is done using the next least significant digit, until the end, when you have done the number of bucket sorts equal to the maximum number of digits of your biggest number. Because with the bucket sort, there are only 10 buckets (the counts array is of size 10), this will always be an O(n) sorting algorithm! See below for a Radix Example. On each of the adapted bucket sorts it does, the count array stores the numbers of each digit. Then the offsets are created using the counts, and then the sorted array regenerated using the offsets and the original data.
This is the god of sorting algorithms. It will search the largest list, with the biggest numbers, and has a is guaranteed O(n) time complexity. And it ain't very complex to understand or implement.
My recommendations are to use this one wherever possible.Distribution Yes Best and Worst Case: Q(n)
Bloody awesome!
[Oct 09, 2010] Sorting Knuth
1. About the code
2. The Algorithms2.1. 5.2 Internal Sorting
2.2. 5.2.1 Sorting by Insertion
2.3. 5.2.2 Sorting by Exchanging
2.4. 5.2.3 Sorting by selection
2.5. 5.2.4 Sorting by Merging
2.6. 5.2.5 Sorting by Distribution3. Epilog
by Marc Tardif
last updated 2000/01/31 (version 1.1)
also available as XMLThis article should be considered an independent re-implementation of all of Knuth's sorting algorithms from The Art of Programming - Vol. 3, Sorting and Searching. It provides the C code to every algorithm discussed at length in section 5.2, Internal Sorting. No explanations are provided here, the book should provide all the necessary comments. The following link is a sample implementation to confirm that everything is in working order: sknuth.c.
[Jul 25, 2005] The Code Project - Sorting Algorithms In C# - C# Programming
God bless their misguided object-oriented souls ;-)
Richard Harter's World
Postman's Sort Article from C Users Journal
This article describes a program that sorts an arbitrarily large number of records in less time than any algorithm based on comparison sorting can. For many commonly encountered files, time will be strictly proportional to the number of records. It is not a toy program. It can sort on an arbitrary group of fields with arbitrary collating sequence on each field faster than any other program available.
An Improved Comb Sort with Pre-Defined Gap Table
PennySort is a measure of how many 100-byte records you can sort for a penny of capital cost
4 Programs Make NT 'Sort' of Fast
Benchmark results -- all times in seconds
10,000 records, 10-character alpha key 100,000 records, 10-character alpha key 1 million unique 180-byte records, 10-character alpha key 1 million unique 180-byte records, 7-character integer key 1 million unique 180-byte records, full 180-byte alphanumeric key Windows NT sort command 2.73 54.66 NA NA NA Cosort .31 7.89 300.66 297.33 201.34 NitroSort .28 6.94 296.1 294.71 270.67 Opt-Tech .54 9.27 313.33 295.31 291.52 Postman's Sort
Fast median search an ANSI C implementation
An inverted taxonomy of sorting algorithms
An alternative taxonomy (to that of Knuth and others) of sorting algorithms is proposed.
An alternative taxonomy (to that of Knuth and others) of sorting algorithms is proposed. It emerges naturally out of a top-down approach to the derivation of sorting algorithms. Work done in automatic program synthesis has produced interesting results about sorting algorithms that suggest this approach. In particular, all sorts are divided into two categories: hardsplit/easyjoin and easysplit/hardjoin.
Quicksort and merge sort, respectively, are the canonical examples in these categories.
Insertion sort and selection sort are seen to be instances of merge sort and quicksort, respectively, and sinking sort and bubble sort are in-place versions of insertion sort and selection sort. Such an organization introduces new insights into the connections and symmetries among sorting algorithms, and is based on a higher level, more abstract, and conceptually simple basis. It is proposed as an alternative way of understanding, describing, and teaching sorting algorithms.
Data Structures and Algorithms with Object-Oriented Design Patterns in C++ online book by Bruno R. Preiss B.A.Sc., M.A.Sc., Ph.D., P.Eng. Associate Professor Department of Electrical and Computer Engineering University of Waterloo, Waterloo, Canada
sortchk - a sort algorithm test suite
sortchk is a simple test suite I wrote in order to measure the costs (in terms of needed comparisons and data moves, not in terms of time consumed by the algorithm, as this is too dependend on things like type of computer, programming language or operating system) of different sorting algorithms. The software is meant to be easy extensible and easy to use.It was developed on NetBSD, but it will also compile and run well on other systems, such as FreeBSD, OpenBSD, Darwin, AIX and Linux. With little work, it should also be able to run on foreign platforms such as Microsoft Windows or MacOS 9.
Sorting Algorithms Implementations of sorting algorithms.
- Techniques for sorting arrays
- Bubble sort
- Linear insertion sort
- Quicksort
- Shellsort
- Heapsort
- Interpolation sort
- Linear probing sort
- Sorting other data structures
- Merge sort
- Quicksort for lists
- Bucket sort
- Radix sort
- Hybrid methods of sorting
- Recursion termination
- Distributive partitioning
- Non-recursive bucket sort
- Treesort
- Merging
- External sorting
- Selection phase techniques
- Replacement selection
- Natural selection
- Alternating selection
- Merging phase
- Balanced merge sort
- Cascade merge sort
- Polyphase merge sort
- Oscillating merge sort
- External Quicksort
Recommended Links
Google matched content
Softpanorama Recommended
Top articles
Sites
- Sorting algorithm - Wikipedia, the free encyclopedia
- Google Directory - Computers Algorithms Sorting and Searching
- Cool sorting links on the Web
- Data Structures and Algorithms with Object-Oriented Design Patterns in C++ online book by Bruno R. Preiss B.A.Sc., M.A.Sc., Ph.D., P.Eng. Associate Professor Department of Electrical and Computer Engineering University of Waterloo, Waterloo, Canada
- Apr00 Table of Contents THE FASTEST SORTING ALGORITHM? by Stefan Nilsson. Which sorting algorithm is the fastest? Stefan presents his answer to this age-old question. Additional resources include fastsort.txt (listings) and fastsort.zip (source code). See also Stefan Nilsson Publications
- A Compact Guide to Sorting and Searching by Thomas Niemann
This is a collection of algorithms for sorting and searching. Descriptions are brief and intuitive, with just enough theory thrown in to make you nervous. I assume you know a high-level language, such as C, and that you are familiar with programming concepts including arrays and pointers.
The first section introduces basic data structures and notation. The next section presents several sorting algorithms. This is followed by a section on dictionaries, structures that allow efficient insert, search, and delete operations. The last section describes algorithms that sort data and implement dictionaries for very large files. Source code for each algorithm, in ANSI C, is included.
Most algorithms have also been coded in Visual Basic. If you are programming in Visual Basic, I recommend you read Visual Basic Collections and Hash Tables, for an explanation of hashing and node representation.
If you are interested in translating this document to another language, please send me email. Special thanks go to Pavel Dubner, whose numerous suggestions were much appreciated. The following files may be downloaded:
- PDF format (200k)
- source code (C) (24k)
- source code (Visual Basic) (27k)
- Algorithm Archive
- Welcome To Sorting Animation -includes Shell sort, Heap sort and quick sort
- The Postman's Sort Article by Robert Ramey about distributive sort. Not that impressive for UTF-8, but still can be used if you you view the each UTF-8 letter as two separate bytes (effectively doubling the length of the key)
- Sort Benchmark Home Page Hosted by Microsoft. Webmaster Jim Gray
- Sorting and Searching Strings
- The Sorting Algorithm Demo (1.0.2)
- The J Sort
- Sorting Algorithms -- some explanation of simple sorting algorithms
- Sorting Algorithms -Skolnick -- very good explanation of insertion sort and selection sort. Insertion sort "inserts" each element of the array into a sorted sub-array of increasing size. Initially, the subarray is of size 0. It depends on the insert function shown below to insert an element somewhere into a sorted array, shifting everything to the right of that element over one space.
- Sorting Algorithms Page -- several C programs for simple sorting argorithms (Insertion, Bubblesort, Selection sort) and several advanced (Quicksort, Mergesort, Shellsort, Heapsort)
- Definitions of Algorithms Data Structures and Problems
- Algorithms A Help Site -- a pretty raw
- Mustafa's Modified Sorting Algorithms
- Outline Chapter 8 the source code for the chapter on Sorting from Algorithms, Data Structures, and Problem Solving with C++, by Mark Allen Weiss.
- Sorting Algorithms -- tutorial with animations
- Sorting Algorithms The Complete Collection of Algorithm Animations
- Some sorting algorithms -- Pascal
- Sorting Algorithms
Animations
- Sort Algorithms Visualizer
- Sandeep Mitra's Java Sorting Animation Page with user input
- The Complete Collection of Algorithm Animations
- Sorting Algorithms Demo by Jason Harrison ([email protected]) -- Java applets, not possibility to alter input.
- xSortLab Lab
Animation of Sorting Algorithms
- Sorting Algorithms Demo Demonstrated with 15 java applets. Cool!
- The Improved Sorting Algorithm Demo Lots of sorting (18) algorithms demos.
- Heap sort visualization A short primer on the heap sort algorithm + a user's guide to learn the applet's interface and how it works. Finally, check out the visualization applet itself to dissect this truly elegent sorting algorithm. Technical documentation is also available for anyone wanting to see how this applet was designed and implemented in the Java language. From there, the source code is explained.
- Merge Sort Algorithm Simulation With good explanation.
- Sandeep Mitra's Java Sorting Animation Page Nine classic algorithms with explanation.
- MergeSort demo with comparison bounds With merge sort description.
- The Sorting Algorithm Demo Sequential and parallel - includes also time analysis.
- Sorting Algorithms Nine algorithms demonstrated.
- Sort Animator Bubble, Insertion, Selection, Quicksort, Shell, Merge sort demonstrated.
- The Sorting Algorithm Demo 6 classics algorithms (Bubble + Bi, Quick, Insert, Heap and Shell).
- Analysis of Sorting Algorithm Merge Sort, Insertion Sort, and a combination Merge/Insertion Sort compared.
- Don Stone's Program Visualization Page Different sorts visualized on your PC (Old Ms/Dos view)
- Sorting Algorithms Bookmark for sorting algorithms demos.
- Welcome to Sorting Animation Insertion, Shell, Heap, Radix and Quicksort explained in clear way, by Yin-So Chen.
- Animation of Sort Algorithms Java - five algorithms.
- Illustration of sorting algorithms BubbleSort, Bidirectional BubbleSort, QuickSort, SelectionSort, Insertionsort and ShellSort
Sorting Demo is a powerful tool for demonstrating how sorting algorithms work. It was designed to alleviate some of the difficulty instructors often have in conveying these concepts to students due to lack of blackboard space and having to constantly erase. This program started out as a quicksort demonstration applet, and after proposing the idea to Seton Hall's math and computer science department, I was given permission to expand the idea to encompass many of the sorts commonly taught in a data structures/algorithms class. There are currently 9 algorithms featured, all of which allow you to either type in your own array or make the computer generate a random array of a milestone size. Although graphics limit the input array to a length of 25 elements, there is the option to run the algorithm without graphics in order to get an understanding of its running time in comparison with the other sorts.We all know that Quicksort is one of the fastest algorithms for sorting. It's not often, however, that we get a chance to see exactly how fast Quicksort really is. The following applets chart the progress of several common sorting algorthms while sorting an array of data using constant space algorithms. (This is inspired by the algorithm animation work at Brown University and the video Sorting out Sorting from the University of Toronto (circa 1970!).)
This applet lets you observe the dynamic operation of several basic sort algorithms. The implementations, explanations
and display technique are all taken from Algorithms in C++, third Edition, Sedgewick, 1998.
- Generate a data set by clicking one of the data set buttons.
- This generates a data set with the appropriate characteristics. Each data set is an array of 512 values in the range 0..511. Data sets have no duplicate entries except the Gaussian distribution.
- Run one or more sort algorithms on the data set to see how the algorithm works.
- Each execution of a sort runs on the same data set until you generate a new one.
Animator for selection sort Provided by - Peter Brummund through the Hope College Summer Research Program. Algorithms covered:
- Bubble Sort -- incorrect implementation
- Insertion Sort
- Merge Sort
- Quick Sort
- Selection Sort
- Shell Sort
Recommended Papers
P. M. McIlroy, K. Bostic and M. D. McIlroy, Engineering radix sort, Computing Systems 6 (1993) 5-27 gzipped PostScript (preprint)
M. D. McIlroy, A killer adversary for quicksort, Software--Practice and Experience 29 (1999) 341-344, gzipped PostScript or pdfLecture Notes
- Data Structures Lecture 12
- Sorting Algorithms
- Sorting Algorithms
- Discussion of Sorting Algorithms
- Sequential and parallel sorting algorithms
- CCAA - Sorting Algorithms
- Sorting and Searching Algorithms: A Cookbook Good explanations & source code, Thomas Niemann
- The Online Guide to Sorting at IIT
- Radix Sort Tutorial .
- Sort Benchmark Home Page all you need to know on sort benchmark...
- M. H. Albert and M. D. Atkinson, Sorting with a Forklift, Eigth Scandinavian Workshop on Algorithm Theory, July 2002.
- Vladmir Estivill-Castro , Derick Wood, A survey of adaptive sorting algorithms, ACM Computing Surveys (CSUR), v.24 n.4, p.441-476, Dec. 1992
Random Findings
- Sorting and Searching Strings Jon Bentley and Robert Sedgewick work
- Bubble Soft of an Unsorted Linked List Good explanation with a skeleton program
- Index of /sequoia/misc/qsort/ Qsort C sources
- Some sorting algorithms Selection, Insertion, Bubble, shell, quick, merge, heap and radix (Pascal src)
- Radix sorting Explanation and Pascal source
- Steven's Project Page
- Bentley's qsort function
- Sorting Algorithm Examples
- The J Sort
- high performance computing archive (sorting algorithms)
- http://www.ajk.tele.fi/libc/stdlib/radixsort.c.html
- Peter Pamberg
- Insert Counting Sort
Etc
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...

You can use PayPal to to buy a cup of coffee for authors of this site Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: October, 21, 2020